Jmeter使用笔记之html报告扩展(一)
题记:在用loadrunner的时候可以生成一个HTML的报告,并且里面包含各种图表,各种详细的数据。而在使用Jmeter测试完后并不能直接生成Html
的报告(无论是用GUI还是命令行启动)。
经过查找资料发现Jmeter的extras目录下有生成HTML的xsl样式表,其实Jenkins+ant+Jmeter生成的HTML报告也是调用了这里的样式表生成的,于是
通过xsltproc report.jtl > test.html,或者ant也可以。这个命令把Jmeter的结果文件转换为HTML的报告。结果如下:

这里虽然能生成HTML报告了,但是这个报告太弱了,基本不能用,包含的参数太少。所以需要对这个报告进行扩展。因为Jmeter本身的聚合报告的数据还是比较全的,
因此打算按照那个报告的值进行扩展。
xsltproc,xlst介绍
XSL 指扩展样式表语言(EXtensible Stylesheet Language),把XML转换为HTML用的就是xls编写的样式表,所以如果要扩展这个报告,首先要对xls
熟悉,才能更改和扩展样式表。可以在http://www.w3school.com.cn/xsl/index.asp这里进行此语言的学习。
xsltproc是一个快速XSLT引擎,它可以将通过XSL层叠样式表把XML转换为相应格式的文件,比如:HTML,XHTML,PDF
比如将XML转换为HTML,使用格式如下:
<xsl:variable name="allMedianTime">
<xsl:call-template name="LineTime">
<xsl:with-param name="nodes" select="/testResults/*/@t" />
<xsl:with-param name="position" select="ceiling($allCount * 0.9)" />
</xsl:call-template>
</xsl:variable>
这里主要是获得时间元素的集合,以及90%line的位置,有了这两个参数后就可以进行后续的扩展了,扩展后的效果图如下:

因为90%Line和95%Line,99%Line计算原理都是一致的,因此只要计算出一个值其他的值也很好计算
QPS扩展
Jmeter的具合报告有Throughput这个值,这个在loadrunner中是表示为吞吐量的,这里可以表示QPS或者TPS(在使用了事务的情况下),个人把这个称为QPS,因为更直观。
和%90Line同样的道理,首先必须知道这个值是怎么计算出来,经过查找资料和官网的比较,发现这个值是通过如下的公式计算出来的:
官网的截图:

Throughput = (number of requests) / (total time)
total time = 测试结束时间 - 测试开始时间
测试结束时间 = MAX(请求开始时间 + Elapsed Time)
测试开始时间 = MIN(请求开始时间)
知道了公式,那么计算就容易了,以下是关键代码:
<xsl:variable name="nodeThroughput">
<xsl:call-template name="throughput">
<xsl:with-param name="nodes" select="/testResults/*/@ts" />
<xsl:with-param name="count" select="$allCount" />
</xsl:call-template>
</xsl:variable>
扩展后的结果如下:
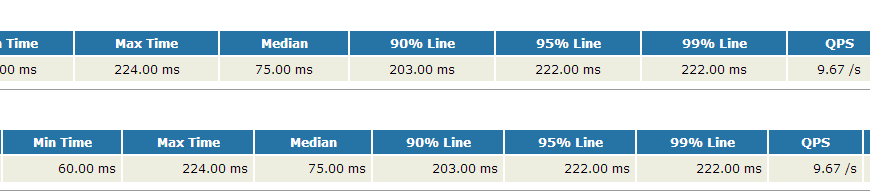
吞吐量扩展
在loadrunner中吞吐量就是Throughput,在Jmeter的聚合报告中最后一列的值就是loadrunner中的Throughput,为了便于区分,我把这里的值称为Throughput,
也就是吞吐量。
经过查找资料发现吞吐量的计算和QPS的计算公式是一样的,因为也就是如下的公式:
Throughput = (请求的总字节数) / (total time)
这里的total time计算和QPS是一样的,而总字节数直接把所有请求的加起来即可,关键代码如下:
<xsl:variable name="nodeKB">
<xsl:call-template name="throughput">
<xsl:with-param name="nodes" select="/testResults/*/@ts" />
<xsl:with-param name="count" select="sum(/testResults/*/@by) div 1024" />
</xsl:call-template>
</xsl:variable>
因为这里显示的字节,最后的结果我打算以KB的单位显示,因此这里需要除以1024,扩展后的结果如下

TPS扩展
TPS在Jmeter中虽然某些情况和QPS是一致的,但是还是有不一致的地方,因此这里也需要扩展,这样的结果看着更清晰明了。
首先和其他的参数扩展一样,需要知道计算公式,这里的计算公式和QPS也是一样的,只是数据的集合不一样,以下是扩展后的效果。

在扩展的过程中进一步发现Jmeter的聚合结果中最后的”总体“一行在某些情况下计算的数值是不准确的。如果脚本中不包含事务,那么这里的结果是准确的,如果都包含事务并且把
Generate parent sample选中后这里的结果也是准确的,在脚本中有事务并且没有选中Generate parent sample,或者有些有事务有些没有时,这时的结果就不准确了,因为查看计算
方式发现它把所有的请求都算进去了。
比如,一个jtl文件中即包含HTTP请求也包含事务,因为事务只是对之前请求的一个统计,本身是不发送请求的,所以计算总的吞吐量、QPS,TPS时是不能这么算的。
所以在扩展的过程中分成了两个样式表,一个样式表处理包含事务,或者没有事务的情况,这时的结果以QPS衡量;一个样式表处理全都是事务的情况,这时候的结果以TPS衡量,这样
就准确了。
测试
扩展了好几个指标,这些指标的正确性如何呢?需要在多种情况下进行测试,经过测试后各个指标都是正确的。但是还没有在大的数据量级别下测试,如果测试后发现哪里会有问题,会及时
更改。
切记:由于样式表中是按照lb进行请求区分的,因此这里的lable不能重复,本身也不应该重复,包括Jmeter的聚合报告都是以lable进行区分的
PS:在扩展过程中的难点一是公式如何计算的,二是xls这个 指扩展样式表语言不是很熟悉,本身也有很多限制,会在下个博客中说明。但是用过后感觉还是很不错的既熟悉了xpath还熟悉了xls。
三是需要对Jmeter的测试结果文件每个字段戴表什么意思熟悉,这样才能定制更多的指标,这个也会在单独的博客中说明
Jmeter使用笔记之html报告扩展(一)的更多相关文章
- Jmeter 使用笔记之 html 报告扩展(一)
题记:在用 loadrunner 的时候可以生成一个 HTML 的报告,并且里面包含各种图表,各种详细的数据.而在使用 Jmeter 测试完后并不能直接生成 Html 的报告(无论是用 GUI 还是命 ...
- DuiLib学习笔记(二) 扩展CScrollbar属性
DuiLib学习笔记(二) 扩展CScrollbar属性 Duilib的滚动条滑块默认最小值为滚动条的高度(HScrollbar)或者宽度(VScrollbar).并且这个值默认为16.当采用系统样式 ...
- odoo开发笔记 -- 搜索视图继承扩展
odoo开发笔记 -- 搜索视图继承扩展
- jmeter+ant+jenkins生产的报告乱码
jmeter+ant+jenkins生产的报告乱码 问题:生产报告会乱码的问题,一般是有编码格式引起的.我遇到的问题是,jmeter需要读取csv的数据作为参数.但是我们并不知道csv保存是什么编码格 ...
- Jmeter学习笔记(二十三)——生成HTML性能报告
有时候我们写性能报告的时候需要一些性能分布图,JMeter是可以生成HTML性能报告的.这篇博客,简单介绍下在利用jmeter进行性能测试时,是如何生成HTML的可视化测试报告的 一.准备工作 1:j ...
- Jmeter学习笔记(八)——监听器元件之聚合报告
1.聚合报告添加 聚合报告是常用的监听器之一,添加路径: 点击线程组->添加->监听器->聚合报告 2.聚合报告界面及说明 Label:请求的名称,就是我们在进行测试的httpreq ...
- Jmeter使用笔记1
1.简介 jmeter 是一款专门用于功能测试和压力测试的轻量级测试开发平台.多数情况下是用作压力测试,该测试工具在阿里巴巴有着广泛的使用. 2.安装 下载apache-jmeter-3.1.rar; ...
- Jmeter学习笔记(二十一)——Concurrency Thread Group阶梯式加压测试
一.先安装jmeter的插件管理工具 1.下载地址:jmeter-plugins.org 点击plugins-manager.jar下载. 2.安装 把下载下来的文件plugins-manager.j ...
- jmeter接口测试笔记
1.接口测试基础 API:Application Programming Interface,即调用应用程序的通道. 接口测试遵循点 接口的功能性实现:检查接口返回的数据与预期结果的一致性. 测试接口 ...
随机推荐
- java使用elasticsearch实现集群管理
本篇博客主要是查看集群中的相关信息,具体请看代码和注释 @Test public void test45() throws UnknownHostException{ //1.指定es集群 clust ...
- 从此使用linux系统,但是QQ是必不可少的!!该篇文章方法成功!!!已验证!!!!!
一开始,我在Ubuntu14.04下安装的QQ版本是WineQQ2013SP6-20140102-Longene, 但后来发现这个版本QQ在linux下问题很多,比如不能用键盘输入密码,QQ表情使用失 ...
- php面试中的经典问题
原文:https://blog.csdn.net/ghostlv/article/details/51284745 问题一问题描述考虑下面代码: $str1 = 'yabadabadoo';$str2 ...
- Python脱产8期 Day11 2019/4/25
一 字符串比较 1.字符串比较:字符串对应的ascii进行比较 2.多个字符的字符串进行比较:从前往后逐个字符进行比较,一旦哪个位置的字符出现了大小关系就结束比较. 二 形参与实参 1.参数介绍: 函 ...
- Linux进程管理 (篇外)内核线程简要介绍
关键词:kthread.irq.ksoftirqd.kworker.workqueues 在使用ps查看线程的时候,会有不少[...]名称的线程,这些有别于其它线程,都是内核线程. 其中多数内核线程从 ...
- 如何备份和恢复你的TFS服务器(一)
备份和恢复一个TFS(Team Foundation Server)服务器常常令人心生畏惧.因为这会涉及到很多服务和步骤.TFS(Team Foundation Server)2010一发布,我就知道 ...
- NuGet的本地服务器安装与Package的发布(呕吐)
主要的步骤是按照下面的例子来做的: NuGet学习笔记(1)——初识NuGet及快速安装使用 NuGet学习笔记(2)——使用图形化界面打包自己的类库 NuGet学习笔记(3)——搭建属于自己的NuG ...
- 深入理解Redis高可用方案-Sentinel
Redis Sentinel是Redis的高可用方案.是Redis 2.8中正式引入的. 在之前的主从复制方案中,如果主节点出现问题,需要手动将一个从节点升级为主节点,然后将其它从节点指向新的主节点, ...
- CSS Grid 读书笔记
基本概念 MDN上的解释是这样的 CSS Grid Layout excels at dividing a page into major regions or defining the relati ...
- 模块的语法 import ,from...import....
------------------------积极的人在每一次忧患中都看到一个机会, 而消极的人则在每个机会都看到某种忧患 1. 认识模块 模块可以认为是一个py文件. 模块实际上是我们的py文件运 ...