word2vec的原理(一)
最近上了公司的新员工基础培训课,又对NLP重新产生的兴趣。NLP的第一步大家知道的就是不停的写正则,那个以前学的还可以就不看了。接着就是我们在把NLP的词料在传入神经网络之前的一个预处理,最经典的就是2013年google提出的那个word2vec算法,所以最近想再把这个算法给好好学习一下,然后实现一下。
1. 词向量基础
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0)(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
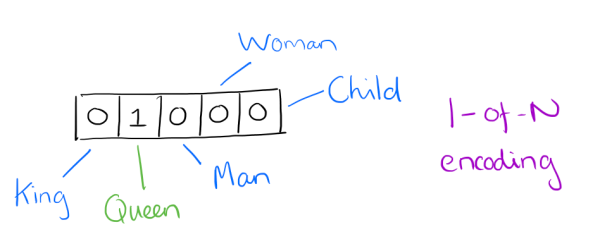
One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
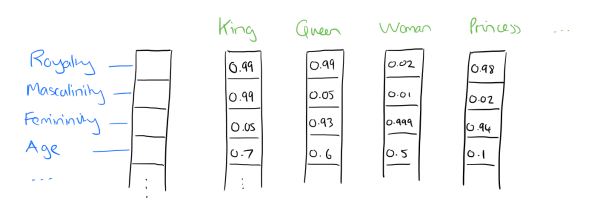
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
VEC(king) - VEC(man) + VEC(woman) = vec(Queen)

2. CBOW与Skip-Gram用于神经网络语言模型
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。比如下面这段话,我们的上下文大小取值为4,特定的这个词是"Learning",也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
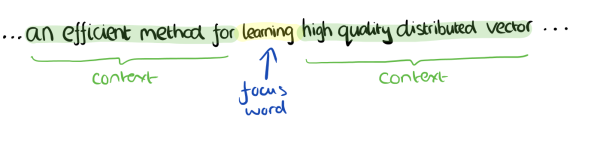
这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为4, 特定的这个词"Learning"是我们的输入,而这8个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
word2vec为什么 不用现成的DNN模型,要继续优化出新方法呢?最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。有没有简化一点点的方法呢?
3. word2vec基础之霍夫曼树
word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。
具体如何用霍夫曼树来进行CBOW和Skip-Gram的训练我们在下一节讲,这里我们先复习下霍夫曼树。
霍夫曼树的建立其实并不难,过程如下:
输入:权值为(w1,w2,...wn)(w1,w2,...wn)的nn个节点
输出:对应的霍夫曼树
1)将(w1,w2,...wn)(w1,w2,...wn)看做是有nn棵树的森林,每个树仅有一个节点。
2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和。
3) 将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林。
4)重复步骤2)和3)直到森林里只有一棵树为止。
下面我们用一个具体的例子来说明霍夫曼树建立的过程,我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(16,4,8,6,20,3)。
首先是最小的b和f合并,得到的新树根节点权重是7.此时森林里5棵树,根节点权重分别是16,8,6,20,7。此时根节点权重最小的6,7合并,得到新子树,依次类推,最终得到下面的霍夫曼树。
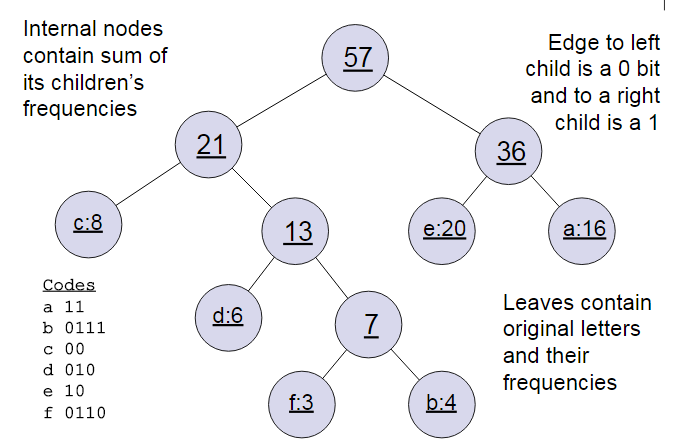
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.如上图,则可以得到c的编码是00。
在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
word2vec的原理(一)的更多相关文章
- word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用了CBOW(Continuous B ...
- word2vec 数学原理
word2vec 是 Google 于 2013 年推出的一个用于获取词向量的开源工具包.我们在项目中多次使用到它,但囿于时间关系,一直没仔细探究其背后的原理. 网络上 <word2vec 中的 ...
- Word2Vec实现原理(Hierarchical Softmax)
由于word2vec有两种改进方法,一种是基于Hierarchical Softmax的,另一种是基于Negative Sampling的.本文关注于基于Hierarchical Softmax的改进 ...
- 文本分布式表示(一):word2vec理论
Word2vec是Google的Mikolov等人提出来的一种文本分布式表示的方法,这种方法是对神经网络语言模型的“瘦身”, 巧妙地运用层次softmax(hierarchical softmax ) ...
- 基于CBOW网络手动实现面向中文语料的word2vec
最近在工作之余学习NLP相关的知识,对word2vec的原理进行了研究.在本篇文章中,尝试使用TensorFlow自行构建.训练出一个word2vec模型,以强化学习效果,加深理解. 一.背景知识: ...
- 利用搜狐新闻语料库训练100维的word2vec——使用python中的gensim模块
关于word2vec的原理知识参考文章https://www.cnblogs.com/Micang/p/10235783.html 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会, ...
- 深入理解Word2Vec
Word2Vec Tutorial - The Skip-Gram Model,Skip-Gram模型的实现原理:http://mccormickml.com/2016/04/19/word2vec- ...
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- word2vec模型cbow与skip-gram的比较
cbow和skip-gram都是在word2vec中用于将文本进行向量表示的实现方法,具体的算法实现细节可以去看word2vec的原理介绍文章.我们这里大体讲下两者的区别,尤其注意在使用当中的不同特点 ...
随机推荐
- Spring配置ArgumentResolver,统一进行session鉴定
一.编写WebMvcConfig配置类: 重写addArgumentResolvers方法,将解析类加入 @Configuration public class WebConfig extends W ...
- 使用 IntelliTrace 调试应用程序
IntelliTrace 如何能够大幅改善您的日常开发活动,并提升您快速轻松诊断问题的能力,而不必重新启动应用程序和使用传统的“中断-单步执行-检查”技术进行调试.介绍了组织如何能够通过在测试过程中收 ...
- linux文件系统问题:wrong fs type, bad option, bad superblock
http://blog.itpub.net/26006637/viewspace-1059946/ 报错内容: mount: wrong fs type, bad option, bad superb ...
- Java关键字解释及作用
JAVA 关键字及其作用解释 1. 访问控制 1) private 私有的 private 关键字是访问控制修饰符,可以应用于类.方法或字段(在类中声明的变量). 只能在声明 private(内部)类 ...
- git版本控制工具的使用(1)。
为了使用. 感谢:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000 讲解的很清晰, ...
- 检测鼠标是否在UI上unity
public static bool IsCursorOnUI(int inputID=-1){ EventSystem eventSystem = EventSystem.current; retu ...
- kbmMW均衡负载与容灾(2)(转载红鱼儿)
集中式均衡负载 为实现集中式均衡负载方案,需要实现两个不同的应用服务器,一个是只包含均衡负载组件再无其他内容的应用服务器,可称之为均衡负载应用服务器,下文简称LB Server,另外一个就是包含一个或 ...
- Mysql命令drop database:删除数据库
drop命令用于删除数据库. drop命令格式:drop database <数据库名>; 例如,删除名为 xhkdb的数据库:mysql> drop database xhkdb; ...
- 2019.01.23 hdu3377 Plan(轮廓线dp)
传送门 题意简述:给一个n*m的带权矩阵,求从左上角走到右下角的最大分数,每个格子只能经过最多一次,n,m≤9n,m\le9n,m≤9. 思路: 考虑轮廓线dpdpdp,但这道题并没有出现回路的限制因 ...
- Opencv(3):基本数据类型
1.比较简单的原子类型 结构 成员 意义 CvPoint int x,y 图像中的点 CvPoint2D32f float x,y 二维空间中的点 CvPoint3D32f float x,y,z 三 ...