《机器学习实战》KNN算法实现
本系列都是参考《机器学习实战》这本书,只对学习过程一个记录,不做详细的描述!
注释:看了一段时间Ng的机器学习视频,感觉不能光看不练,现在一边练习再一边去学习理论!
KNN很早就之前就看过也记录过,在此不做更多说明,这是k-means之前的记录,感觉差不多:http://www.cnblogs.com/wjy-lulu/p/7002688.html
1.简单的分类
代码:
import numpy as np
import operator
import KNN def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #样本个数
diffMat = np.tile(inX,(dataSetSize,1)) - dataSet#样本每个值和测试数据做差
sqDiffMat = diffMat**2#平方
sqDistances = sqDiffMat.sum(axis=1)#第二维度求和,也就是列
distances = sqDistances**0.5#平方根
sortedDistIndicies = distances.argsort()#下标排序
classCount = {} for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]#得到距离最近的几个数
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1#标签计数
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)#按照数值排序operator.itemgetter(1)代表第二个域
#上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)]
return sortedClassCount[0][0] if __name__ == '__main__':
group,labels = KNN.createDataSet()
result = classify0([0,0.5],group,labels,1)
print (result)
KNN.Py文件
import numpy as np
import operator def createDataSet():
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'B', 'C', 'D']
return group, labels
2.约会网站的预测
下面给出每个部分的代码和注释:
A.文本文件转换为可用数据
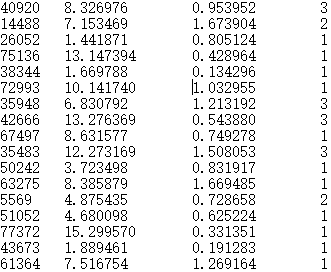
上面的文本中有空格和换行,而且样本和标签都在一起,必须的分开处理成矩阵才可以进行下一步操作。
def file2matrix(filename):#把文件转化为可操作数据
fr = open(filename)#打开文件
arrayOLines = fr.readlines()#读取每行文件
numberOfLines = len(arrayOLines)#行数量
returnMat = np.zeros([numberOfLines,3])#存储数据
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()#去除换行符
listFromLine = line.split('\t')#按照空格去分割
returnMat[index,:] = listFromLine[0:3]#样本
classLabelVector.append(int(listFromLine[-1]))#labels
index += 1
return returnMat,classLabelVector#返回数据和标签
B.归一化
数据大小差异太明显,比如有三个特征:a=[1,2,3],b=[1000,2000,3000],c=[0.1,0.2,0.3],我们发现c和a根本没啥作用,因为b的值太大了,或者说b的权重太大了,Ng中可以用惩罚系数去操作,或者正则化都可以处理这类数据,当然这是题外话。
def autoNorm(dataSet):#归一化函数
#每列的最值
minValue = dataSet.min(0)
maxValue = dataSet.max(0)
range = maxValue - minValue
#创建最小值矩阵
midData = np.tile(minValue,[dataSet.shape[0],1])
dataSet = dataSet - midData
#创建range矩阵
range = np.tile(range,[dataSet.shape[0],1])
dataSet = dataSet / range #直接相除不是矩阵相除
return dataSet,minValue,maxValue
C.预测
KNN的方法就是距离,计算K个距离,然后排序看哪个占得比重大就选哪个类。
def classify0(inX, dataSet, labels, k):#核心分类程序
dataSetSize = dataSet.shape[0] # 样本个数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差
sqDiffMat = diffMat ** 2 # 平方
sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列
distances = sqDistances ** 0.5 # 平方根
sortedDistIndicies = distances.argsort() # 下标排序
classCount = {} for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1),
reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域
# 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)]
return sortedClassCount[0][0]
D.性能测试
比如1000个数据,900个用做样本,100用做测试,看看精确度是多少?
def datingClassTest():
hoRatio = 0.2
datingDataMat , datingLabels = file2matrix('datingTestSet2.txt')
normMat = autoNorm(datingDataMat)
n = normMat.shape[0]
numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点
erroCount = 0.0
#numTestVecs:n样本,[i,numTestVecs]测试
for i in range(numTestVecs):
classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:],
datingLabels[numTestVecs:n],3)
if (classfiResult!=datingLabels[i]): erroCount+=1.0
print ("the totle error os: %f" %(erroCount/float(numTestVecs)))
E.实战分类
注意输入的数据也得归一化
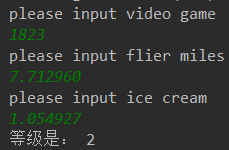
def classfiPerson():
resultList = ['not at all','in small doses','in large doses']
personTats = float(input('please input video game \n'))
ffMiles = float(input('please input flier miles \n'))
iceCream = float(input('please input ice cream \n'))
datingData,datingLabels = file2matrix('datingTestSet2.txt')
normData,minData,maxData = autoNorm(datingData)
inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵
inputData = (inputData - minData)/(maxData - minData)#输入归一化
result = classify0(inputData,normData,datingLabels,3)
print('等级是:',result)
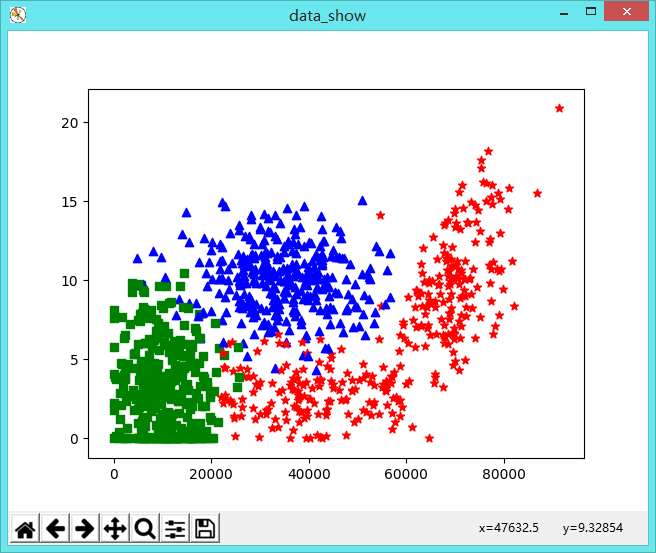
F.可视化显示
datingDatas, datingLabels = KNN.file2matrix('datingTestSet2.txt')
#可视化样本数据显示
fig = plt.figure('data_show')
ax = fig.add_subplot(111)
for i in range(datingDatas.shape[0]):
if datingLabels[i]==1:
ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="*",c='r') # 用后两个特征绘图
if datingLabels[i]==2:
ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="s", c='g') # 用后两个特征绘图
if datingLabels[i]==3:
ax.scatter(datingDatas[i, 0], datingDatas[i, 1], marker="^", c='b') # 用后两个特征绘图
plt.show()
G.完整代码
import numpy as np
import operator
#from numpy import * def createDataSet():#创建简单测试的几个数
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'B', 'C', 'D']
return group, labels def autoNorm(dataSet):#归一化函数
#每列的最值
minValue = dataSet.min(0)
maxValue = dataSet.max(0)
range = maxValue - minValue
#创建最小值矩阵
midData = np.tile(minValue,[dataSet.shape[0],1])
dataSet = dataSet - midData
#创建range矩阵
range = np.tile(range,[dataSet.shape[0],1])
dataSet = dataSet / range #直接相除不是矩阵相除
return dataSet,minValue,maxValue def file2matrix(filename):#把文件转化为可操作数据
fr = open(filename)#打开文件
arrayOLines = fr.readlines()#读取每行文件
numberOfLines = len(arrayOLines)#行数量
returnMat = np.zeros([numberOfLines,3])#存储数据
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()#去除换行符
listFromLine = line.split('\t')#按照空格去分割
returnMat[index,:] = listFromLine[0:3]#样本
classLabelVector.append(int(listFromLine[-1]))#labels
index += 1
return returnMat,classLabelVector#返回数据和标签 def classify0(inX, dataSet, labels, k):#核心分类程序
dataSetSize = dataSet.shape[0] # 样本个数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差
sqDiffMat = diffMat ** 2 # 平方
sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列
distances = sqDistances ** 0.5 # 平方根
sortedDistIndicies = distances.argsort() # 下标排序
classCount = {} for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1),
reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域
# 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)]
return sortedClassCount[0][0] def datingClassTest():
hoRatio = 0.2
datingDataMat , datingLabels = file2matrix('datingTestSet2.txt')
normMat = autoNorm(datingDataMat)
n = normMat.shape[0]
numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点
erroCount = 0.0
#numTestVecs:n样本,[i,numTestVecs]测试
for i in range(numTestVecs):
classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:],
datingLabels[numTestVecs:n],3)
if (classfiResult!=datingLabels[i]): erroCount+=1.0
print ("the totle error os: %f" %(erroCount/float(numTestVecs))) def classfiPerson():
resultList = ['not at all','in small doses','in large doses']
personTats = float(input('please input video game \n'))
ffMiles = float(input('please input flier miles \n'))
iceCream = float(input('please input ice cream \n'))
datingData,datingLabels = file2matrix('datingTestSet2.txt')
normData,minData,maxData = autoNorm(datingData)
inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵
inputData = (inputData - minData)/(maxData - minData)#输入归一化
result = classify0(inputData,normData,datingLabels,3)
print('等级是:',result)
3.手写数字识别
A.转换文件
def img2vector(filename):
returnVector = np.zeros([32,32])
fr = open(filename)
lineData = fr.readlines()
count = 0
for line in lineData:
line = line.strip()#去除换行符
for j in range(len(line)):
returnVector[count,j] = line[j]
count += 1
returnVector = returnVector.reshape(1,1024).astype(int)#转化为1X1024
return returnVector
B.识别分类
def handWriteringClassTest():
#--------------------------读取数据---------------------------------
hwLabels = []
trainingFileList = os.listdir('trainingDigits')#获取文件目录
m = len(trainingFileList)#获取目录个数
trainingMat = np.zeros([m,1024])#全部样本
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]#得到不带格式的文件名
classNumStr = int(fileStr.split('_')[0])#得到最前面的数字类别0-9
hwLabels.append(classNumStr)#存储
dirList = 'trainingDigits/' + fileNameStr#绝对目录信息
vectorUnderTest = img2vector(dirList)#读取第i个数据信息
trainingMat[i,:] = vectorUnderTest #存储
#--------------------------测试数据--------------------------------
testFileList = os.listdir('testDigits')
errorCount = 0.0
m = len(testFileList)
for i in range(m):
fileNameStr = testFileList[i]
fileInt = fileNameStr.split('.')[0].split('_')[0]
dirList = 'testDigits/' + fileNameStr # 绝对目录信息
vectorUnderTest = img2vector(dirList) # 读取第i个数据信息
if int(fileInt) != int(classify0(vectorUnderTest,trainingMat,hwLabels,3)):
errorCount += 1
print('error count is : ',errorCount)
print('error Rate is : ', (errorCount/m))
C.完整代码
import numpy as np
import operator
import os
#from numpy import * def createDataSet():#创建简单测试的几个数
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'B', 'C', 'D']
return group, labels def autoNorm(dataSet):#归一化函数
#每列的最值
minValue = dataSet.min(0)
maxValue = dataSet.max(0)
range = maxValue - minValue
#创建最小值矩阵
midData = np.tile(minValue,[dataSet.shape[0],1])
dataSet = dataSet - midData
#创建range矩阵
range = np.tile(range,[dataSet.shape[0],1])
dataSet = dataSet / range #直接相除不是矩阵相除
return dataSet,minValue,maxValue def file2matrix(filename):#把文件转化为可操作数据
fr = open(filename)#打开文件
arrayOLines = fr.readlines()#读取每行文件
numberOfLines = len(arrayOLines)#行数量
returnMat = np.zeros([numberOfLines,3])#存储数据
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()#去除换行符
listFromLine = line.split('\t')#按照空格去分割
returnMat[index,:] = listFromLine[0:3]#样本
classLabelVector.append(int(listFromLine[-1]))#labels
index += 1
return returnMat,classLabelVector#返回数据和标签 def classify0(inX, dataSet, labels, k):#核心分类程序
dataSetSize = dataSet.shape[0] # 样本个数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 样本每个值和测试数据做差
sqDiffMat = diffMat ** 2 # 平方
sqDistances = sqDiffMat.sum(axis=1) # 第二维度求和,也就是列
distances = sqDistances ** 0.5 # 平方根
sortedDistIndicies = distances.argsort() # 下标排序
classCount = {} for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 得到距离最近的几个数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 标签计数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1),
reverse=True) # 按照数值排序operator.itemgetter(1)代表第二个域
# 上面排序之后就不是字典了,而是一个列表里面包含的元组[('c',2),('a',3)]
return sortedClassCount[0][0] def datingClassTest():
hoRatio = 0.2
datingDataMat , datingLabels = file2matrix('datingTestSet2.txt')
normMat = autoNorm(datingDataMat)
n = normMat.shape[0]
numTestVecs = int(n*hoRatio)#测试数据和样本数据的分割点
erroCount = 0.0
#numTestVecs:n样本,[i,numTestVecs]测试
for i in range(numTestVecs):
classfiResult = classify0(normMat[i,:],normMat[numTestVecs:n,:],
datingLabels[numTestVecs:n],3)
if (classfiResult!=datingLabels[i]): erroCount+=1.0
print ("the totle error os: %f" %(erroCount/float(numTestVecs))) def classfiPerson():
resultList = ['not at all','in small doses','in large doses']
personTats = float(input('please input video game \n'))
ffMiles = float(input('please input flier miles \n'))
iceCream = float(input('please input ice cream \n'))
datingData,datingLabels = file2matrix('datingTestSet2.txt')
normData,minData,maxData = autoNorm(datingData)
inputData = np.array([personTats,ffMiles,iceCream])#转化为矩阵
inputData = (inputData - minData)/(maxData - minData)#输入归一化
result = classify0(inputData,normData,datingLabels,3)
print('等级是:',result) def img2vector(filename):
returnVector = np.zeros([32,32])
fr = open(filename)
lineData = fr.readlines()
count = 0
for line in lineData:
line = line.strip()#去除换行符
for j in range(len(line)):
returnVector[count,j] = line[j]
count += 1
returnVector = returnVector.reshape(1,1024).astype(int)#转化为1X1024
return returnVector def img2vector2(filename):
returnVect = np.zeros([1,1024])
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect def handWriteringClassTest():
#--------------------------读取数据---------------------------------
hwLabels = []
trainingFileList = os.listdir('trainingDigits')#获取文件目录
m = len(trainingFileList)#获取目录个数
trainingMat = np.zeros([m,1024])#全部样本
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]#得到不带格式的文件名
classNumStr = int(fileStr.split('_')[0])#得到最前面的数字类别0-9
hwLabels.append(classNumStr)#存储
dirList = 'trainingDigits/' + fileNameStr#绝对目录信息
vectorUnderTest = img2vector(dirList)#读取第i个数据信息
trainingMat[i,:] = vectorUnderTest #存储
#--------------------------测试数据--------------------------------
testFileList = os.listdir('testDigits')
errorCount = 0.0
m = len(testFileList)
for i in range(m):
fileNameStr = testFileList[i]
fileInt = fileNameStr.split('.')[0].split('_')[0]
dirList = 'testDigits/' + fileNameStr # 绝对目录信息
vectorUnderTest = img2vector(dirList) # 读取第i个数据信息
if int(fileInt) != int(classify0(vectorUnderTest,trainingMat,hwLabels,3)):
errorCount += 1
print('error count is : ',errorCount)
print('error Rate is : ', (errorCount/m))

《机器学习实战》KNN算法实现的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- KNN算法
1.算法讲解 KNN算法是一个最基本.最简单的有监督算法,基本思路就是给定一个样本,先通过距离计算,得到这个样本最近的topK个样本,然后根据这topK个样本的标签,投票决定给定样本的标签: 训练过程 ...
- kNN算法python实现和简单数字识别
kNN算法 算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单 ...
- 什么是 kNN 算法?
学习 machine learning 的最低要求是什么? 我发觉要求可以很低,甚至初中程度已经可以. 首先要学习一点 Python 编程,譬如这两本小孩子用的书:[1][2]便可. 数学方面 ...
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
- 机器学习笔记--KNN算法1
前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的狐朋狗友算法---KNN算法,为什么叫狐朋狗友算法呢,在这里我先卖个关子,且听我慢慢道来. 一 K ...
- 学习OpenCV——KNN算法
转自:http://blog.csdn.net/lyflower/article/details/1728642 文本分类中KNN算法,该方法的思路非常简单直观:如果一个样本在特征空间中的k个最相似( ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- Python 手写数字识别-knn算法应用
在上一篇博文中,我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算.这里简述KNN算法的特点 ...
随机推荐
- Go hashcode 输入一个字符串,得到一个唯一标识码
如何输入一个字符串,得到一个唯一的hashcode? 例子如下: package main import ( "fmt" "hash/crc32" ) // S ...
- Spark代码Eclipse远程调试
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等.用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代 ...
- Maven下载项目依赖jar包和使用方法
一.Maven3.5.0安装与配置+Eclipse应用 参考:Maven3.5.0安装与配置+Eclipse应用 二.http://mvnrepository.com/ 此处以http://mvnre ...
- Release Notes for XE5
开发者之前说明 http://docwiki.embarcadero.com/RADStudio/XE5/en/Release_Notes_for_XE5
- sqlserver 全局事务查询
-- 此语句用于查看最老的活动事务.未完成的分布式事务或复制事务的信息. dbcc opentran -- 通过动态管理视图查看活动事务 select*from sys.dm_tran_active_ ...
- spring boot编译项目打jar包
<build> <plugins> <!--jar包打包--> <plugin> <groupId>org.springframework. ...
- 2.Linux技能要求
Linux嵌入式工程师技能要求: 1.C语言 具备C语言基础.理解C语言基础编程及高级编程,包括:数据类型.数组.指针.结构体.链表.文件操作.队列.栈. ...
- eKingCloud 从 OpenStack 到 OpenInfra 演进之路
本内容首发于 2016/06/21 北京 OpenInfra 大会上本人的演讲 发文章要求至少150个字,那就把最后一页说明一下吧. 我前面介绍了我们的5大产品,包括企业的私有云架构和实践,包括企业数 ...
- python图片和字符串的转换
有个业务,需要将图片压缩转化为64位编码上传到服务端. import json,requests,base64 #网上下载图片素材 r = requests.get("https://tim ...
- JDK、JRE与JVM的关系