【Spark调优】:如果实在要shuffle,使用map侧预聚合的算子
因业务上的需要,无可避免的一些运算一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map侧预聚合的算子。
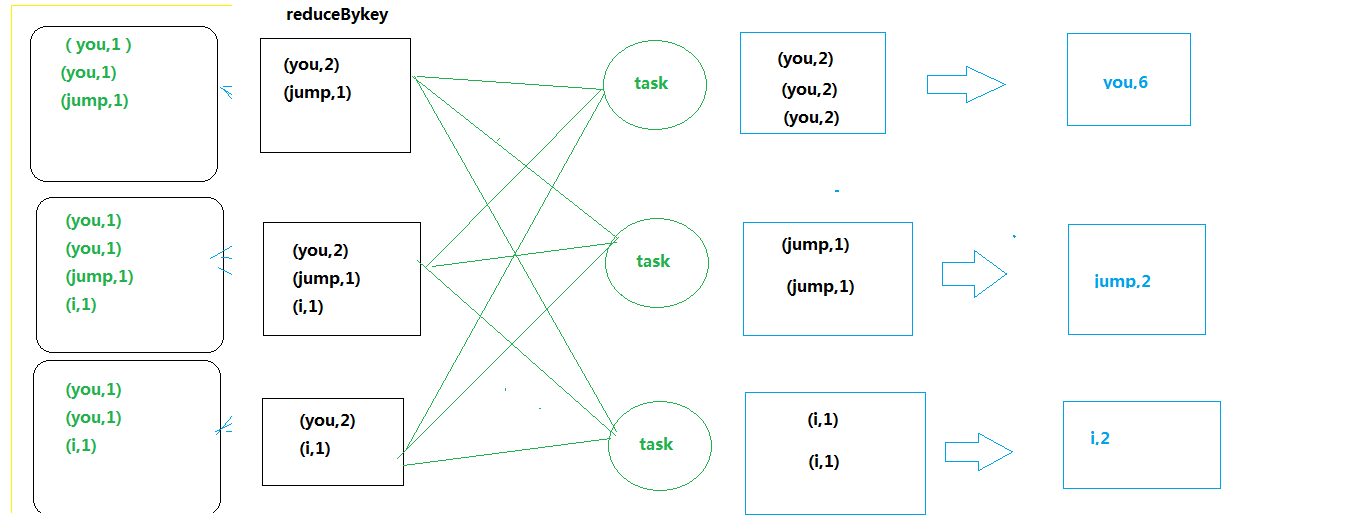
map侧预聚合,是指在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combine。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。shuffle时,节点间拉取其他节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。
对应到算子,建议使用reduceByKey或者aggregateByKey算子来代替groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对较差。
代码实践:https://github.com/wwcom614/Spark
- groupByKey

- reduceByKey
【Spark调优】:如果实在要shuffle,使用map侧预聚合的算子的更多相关文章
- Spark 调优之ShuffleManager、Shuffle
Shuffle 概述 影响Spark性能的大BOSS就是shuffle,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作. 因此,如果要让作业的性能更上一层楼,就有必要对 shuffle 过 ...
- 【Spark调优】:结合业务场景,优选高性能算子
聚合操作使用reduceByKey/aggregateByKey替代groupByKey 参见我的这篇博客说明 [Spark调优]:如果实在要shuffle,使用map侧预聚合的算子 内存充足前提下使 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- Spark调优秘诀——超详细
版权声明:本文为博主原创文章,转载请注明出处. Spark调优秘诀 1.诊断内存的消耗 在Spark应用程序中,内存都消耗在哪了? 1.每个Java对象都有一个包含该对象元数据的对象头,其大小是16个 ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- 【Spark调优】数据倾斜及排查
[数据倾斜及调优概述] 大数据分布式计算中一个常见的棘手问题——数据倾斜: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或j ...
- 【翻译】Spark 调优 (Tuning Spark) 中文版
由于Spark自己的调优guidance已经覆盖了很多很有价值的点,因此这里直接翻译一份过来.也作为一个积累. Spark 调优 (Tuning Spark) 由于大多数Spark计算任务是在内存中运 ...
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
随机推荐
- C++ 50学习 之提高对 C++的认识
转自Effective C++ 理解设计目标. 1.和 C 的兼容性. 2.效率. C++在效率上可以和 C 匹 敌 ---- 二者相差大约在 5%之内. 3.和传统开发工具及环境的兼容性. 4.解决 ...
- 从零开始搭建自己的VueJS2.0+ElementUI单页面网站(一、环境搭建)
原网址:https://blog.csdn.net/u012907049/article/details/72764151 前言 VueJS可以说是近些年来最火的前端框架之一,越来越多的网站开始使用v ...
- wiredtiger--初学数据恢复
启动mongodb是failed,日志如下 1.解压wirdtiger包 tar -vxf wiredtiger-3.1.0.tar.bz2 -C /home/wiredtiger/ 2.安装snap ...
- zabbix钉钉报警
我们在钉钉上建立群聊,然后在群聊上添加钉钉机器人: 编写,脚本需要放在zabbix 的alertscripts目录下(如果不知道该目录的位置,可以使用find命令查找) find / -iname a ...
- python中tolist()命令
- highcharts echarts比较
1,highcharts底层是svg echarts底层是canvas 2,svg和canvas的区别 canvas 依赖分辨率 不支持事件处理器 弱的文本渲染能力 能够以 .png 或 .jpg 格 ...
- Django跨域(前端跨域)
前情回顾 在说今天的问题之前先来回顾一下有关Ajax的相关内容 Ajax的优缺点 AJAX使用Javascript技术向服务器发送异步请求: AJAX无须刷新整个页面: 因为服务器响应内容不再是整个页 ...
- nginx配置备忘
一.本地测试环境配置 upstream gongsibao{ server ; server ; #fair; } server { listen ; server_name ubuntu00.xus ...
- 自动登录(过滤器filter的应用)
//反复实验的时候注意数据库数据的更新 //将数据存储到cookie里面 protected void doGet(HttpServletRequest request, HttpServletRes ...
- Python3实战系列之六(获取印度售后数据项目)
问题:续接上一篇.说干咱就干呀,勤勤恳恳写程序呀! 目标:此篇我们试着把python程序打包成.exe程序.这样就可以在服务器上运行了.实现首篇计划列表功能模块的第三步: 3..exe文件能在服务器上 ...