BVLC CaffeNet可视化及类别预测
一、介绍
bvlc_reference_caffenet网络模型是由AlexNet的网络模型改写的,输入图片尺寸大小为227x227x3,输出的为该图片对应1000个分类的概率值。
介绍参考:caffe/models/bvlc_reference_caffenet at master · BVLC/caffe · GitHub https://github.com/BVLC/caffe/tree/master/models/bvlc_reference_caffenet
二、利用pycaffe可视化网络结构
caffe/python$ python draw_net.py ../models/bvlc_reference_caffenet/deploy.prototxt deploy.png
网络结构:

大图下载地址:链接:https://pan.baidu.com/s/1ggeKlLstZQrOklvnZ03L5A 密码:x7r8
三、matlab可视化
1、网络权值可视化:https://www.cnblogs.com/smbx-ztbz/p/9343874.html
2、特征图可视化
(1)visualize_feature_maps.m
function [] = visualize_feature_maps(w, s)
h = max(size(w, 1), size(w, 2));
g = h + s;
c = size(w, 3);
cv = ceil(sqrt(c));%按长宽相等方式排布,ceil向上取整
W = zeros(g*cv, g*cv); for u = 1:cv
for v = 1:cv
tw = zeros(h, h);
if (((u-1)*cv + v) <= c)
tw = w(:, :, (u-1)*cv+v, 1)';%只对第四维度为1进行可视化,即第一个样本进行可视化
tw = tw - min(min(tw));
tw = tw / max(max(tw))*255;
end
W(g*(u-1) + (1:h), g*(v-1) + (1:h)) = tw;
end
end
W = uint8(W);
figure, imshow(W);
(2)fm_visual.m
clear;
clc;
close all;
addpath('matlab')
caffe.set_mode_cpu();
sprintf(['Caffe Version = ', caffe.version(), '\n']);
net = caffe.Net('models/bvlc_reference_caffenet/deploy.prototxt',...
'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel', 'test'); sprintf('Load net done. Net layers: ');
net.layer_names sprintf('Net blobs: ');
net.blob_names sprintf('Now preparing data...\n');
im = imread('examples/images/cat.jpg');
figure;imshow(im);title('Original Image');
d = load('matlab/+caffe/imagenet/ilsvrc_2012_mean.mat');
mean_data = d.mean_data;%256x256x3
IMAGE_DIM = 256;
CROPPED_DIM = 227; %Convert an fimage returned by Matlab's imread to im_data in caffe's data
%format: W x H x C with BGR channels
im_data = im(:, :, [3, 2, 1]); %permute channels from RGB to BGR
im_data = permute(im_data, [2, 1, 3]); %flip width and height
im_data = single(im_data); %convert from uint8 to single
im_data = imresize(im_data, [IMAGE_DIM IMAGE_DIM], 'bilinear'); %resize im_data 使得跟mean_data尺寸一致
im_data = im_data - mean_data; % subtract mean_data (already in W x H x C, BGR)
im = imresize(im_data, [CROPPED_DIM CROPPED_DIM], 'bilinear'); %resize im_data
km = cat(4, im, im, im, im, im);%在第四个维度往后叠加,第三维度为1。 227x227x3x5
pm = cat(4, km, km);%在第四个维度往后叠加。 227x227x3x10
input_data = {pm};%输入的数据为输入图片拷贝10份 scores = net.forward(input_data);%cell 1000x10,输入的样本个数为10 scores = scores{1};%指向第一个cell,转换为矩阵
scores = mean(scores, 2); %take average scores over 10 crops,对10个样本求均值 [~, maxlabel] = max(scores);%获取概率均值最大的索引 282 maxlabel %显示所属类别概率最大的下标
figure; plot(scores); fm_data = net.blob_vec(1);%输入数据
d1 = fm_data.get_data();
sprintf('Data size = ');
size(d1) %227x227x3x10
visualize_feature_maps(d1, 1); fm_conv1 = net.blob_vec(2);
f1 = fm_conv1.get_data();
sprintf('Feature map conv1 size = ');
%kernel_size: 11, stride: 4, pad: 0 (pad为0表示不对边界进行扩展)
size(f1)%55x55x96x10
visualize_feature_maps(f1, 1); fm_conv2 = net.blob_vec(5);
f2 = fm_conv2.get_data();
sprintf('Feature map conv2 size = ');
%kernel_size: 5, stride: 1, pad: 2 (步进应该为2?)
size(f2) %27 27 256 10
visualize_feature_maps(f2, 1); fm_conv3 = net.blob_vec(8);
f3 = fm_conv3.get_data();
sprintf('Feature map conv3 size = ');
%kernel_size: 3, stride: 1, pad: 1 (步进应该为2?)
size(f3)%13 13 384 10
visualize_feature_maps(f3, 1); fm_conv4 = net.blob_vec(9);
f4 = fm_conv4.get_data();
sprintf('Feature map conv4 size = ');
%kernel_size: 3, stride: 1, pad: 1
size(f4)%13 13 384 10
visualize_feature_maps(f4, 1); fm_conv5 = net.blob_vec(10);
f5 = fm_conv5.get_data();
sprintf('Feature map conv5 size = ');
%kernel_size: 3, stride: 1, pad: 1
size(f5)%13 13 256 10
visualize_feature_maps(f5, 1);
(3)说明
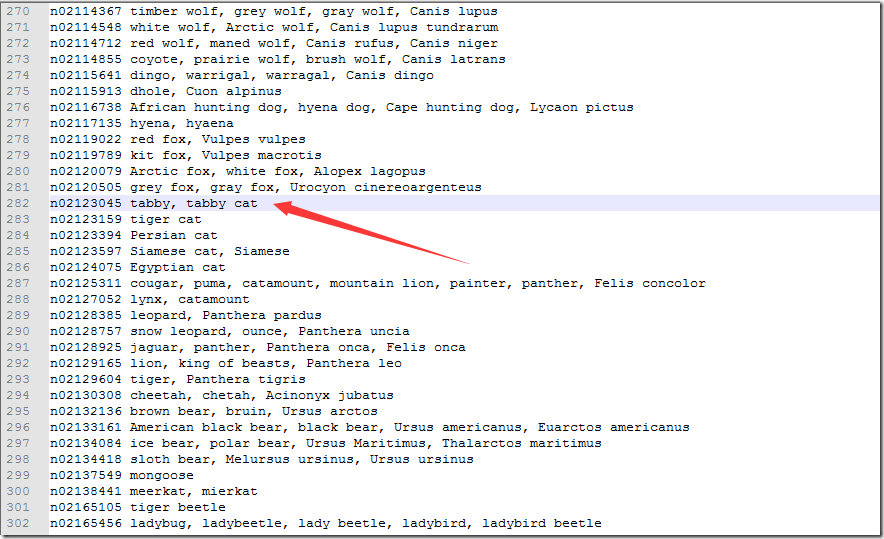
a、scores为输入图片对应1000个类别的概率值,maxlabel为对应最大概率值的下标,及所输入图像被分为哪一类,得到该图片的最大概率对应的索引为282。
b、类别索引和名称对应表可通过data/ilsvrc12/get_ilsvrc_aux.sh 下载解压,在synset_words.txt文件中,根据行号,来找对应的类别。
四、对输入图片进行类别预测
clear;
clc;
close all;
addpath('matlab')
caffe.set_mode_cpu();
sprintf(['Caffe Version = ', caffe.version(), '\n']);
net = caffe.Net('models/bvlc_reference_caffenet/deploy.prototxt',...
'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel', 'test'); im = imread('examples/images/cat.jpg');
% figure;imshow(im);title('Original Image');
d = load('matlab/+caffe/imagenet/ilsvrc_2012_mean.mat');
mean_data = d.mean_data;%256x256x3
IMAGE_DIM = 256;
CROPPED_DIM = 227; %Convert an fimage returned by Matlab's imread to im_data in caffe's data
%format: W x H x C with BGR channels
im_data = im(:, :, [3, 2, 1]); %permute channels from RGB to BGR
im_data = permute(im_data, [2, 1, 3]); %flip width and height
im_data = single(im_data); %convert from uint8 to single
im_data = imresize(im_data, [IMAGE_DIM IMAGE_DIM], 'bilinear'); %resize im_data 使得跟mean_data尺寸一致
im_data = im_data - mean_data; % subtract mean_data (already in W x H x C, BGR)
im = imresize(im_data, [CROPPED_DIM CROPPED_DIM], 'bilinear'); %resize im_data
km = cat(4, im, im, im, im, im);%在第四个维度往后叠加,第三维度为1。 227x227x3x5
pm = cat(4, km, km);%在第四个维度往后叠加。 227x227x3x10
input_data = {pm};%输入的数据为输入图片拷贝10份 scores = net.forward(input_data);%cell 1000x10,输入的样本个数为10 scores = scores{1};%指向第一个cell,转换为矩阵
scores = mean(scores, 2); %take average scores over 10 crops,对10个样本求均值 [~, maxlabel] = max(scores);%获取概率均值最大的索引 maxlabel %显示所属类别概率最大的下标
figure; plot(scores); %打印出对应的label字符串
ffid = fopen('data/ilsvrc12/synset_words.txt','r');
for i = 1:1000
tline = fgetl(ffid);
if(i == maxlabel)
% tline
break;
end
end
label_string = tline(11:size(tline, 2));
sprintf('predict value is: %s\n', label_string)
sprintf('probability is: %f\n', scores(maxlabel))
输出:
maxlabel = 282 ans = predict value is: tabby, tabby cat ans = probability is: 0.288967
可用其他图片进行测试,例如网上下载个熊猫图片进行测试。
参考:
caffe中pad的作用 - CSDN博客 https://blog.csdn.net/xunan003/article/details/79110253
与AlexNet对比:Caffe学习笔记(二)——AlexNet模型 - CSDN博客 https://blog.csdn.net/hong__fang/article/details/52080280
【AlexNet】模型训练与测试导读 - CSDN博客 https://blog.csdn.net/xiequnyi/article/details/52276240?locationNum=5
Caffe下自己的数据训练和测试 - CSDN博客 https://blog.csdn.net/qqlu_did/article/details/47131549
end
BVLC CaffeNet可视化及类别预测的更多相关文章
- pytorch中网络特征图(feture map)、卷积核权重、卷积核最匹配样本、类别激活图(Class Activation Map/CAM)、网络结构的可视化方法
目录 0,可视化的重要性: 1,特征图(feture map) 2,卷积核权重 3,卷积核最匹配样本 4,类别激活图(Class Activation Map/CAM) 5,网络结构的可视化 0,可视 ...
- CaffeNet用于Flickr Style数据集上的风格识别
转自 http://blog.csdn.net/liumaolincycle/article/details/48501423 微调是基于已经学习好的模型的,通过修改结构,从已学习好的模型权重中继续训 ...
- 深度学习与计算机视觉教程(15) | 视觉模型可视化与可解释性(CV通关指南·完结)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 4-Spark高级数据分析-第四章 用决策树算法预测森林植被
预测是非常困难的,更别提预测未来. 4.1 回归简介 随着现代机器学习和数据科学的出现,我们依旧把从“某些值”预测“另外某个值”的思想称为回归.回归是预测一个数值型数量,比如大小.收入和温度,而分类则 ...
- SVM:SVM之Classification根据已有大量数据集案例,输入已有病例的特征向量实现乳腺癌诊断高准确率预测—Jason niu
load BreastTissue_data.mat n = randperm(size(matrix,1)); train_matrix = matrix(n(1:80),:); train_lab ...
- chapter02 K近邻分类器对Iris数据进行分类预测
寻找与待分类的样本在特征空间中距离最近的K个已知样本作为参考,来帮助进行分类决策. 与其他模型最大的不同在于:该模型没有参数训练过程.无参模型,高计算复杂度和内存消耗. #coding=utf8 # ...
- chapter02 朴素贝叶斯分类器对新闻文本数据进行类型预测
基本数学假设:各个维度上的特征被分类的条件概率之间是相互独立的.所以在特征关联性较强的分类任务上的性能表现不佳. #coding=utf8 # 从sklearn.datasets里导入新闻数据抓取器f ...
- 时间序列深度学习:状态 LSTM 模型预测太阳黑子
目录 时间序列深度学习:状态 LSTM 模型预测太阳黑子 教程概览 商业应用 长短期记忆(LSTM)模型 太阳黑子数据集 构建 LSTM 模型预测太阳黑子 1 若干相关包 2 数据 3 探索性数据分析 ...
- Python之机器学习-波斯顿房价预测
目录 波士顿房价预测 导入模块 获取数据 打印数据 特征选择 散点图矩阵 关联矩阵 训练模型 可视化 波士顿房价预测 导入模块 import pandas as pd import numpy as ...
随机推荐
- HashMap 和 HashTable差别
代码版本 JDK每一版本都在改进.本文讨论的HashMap和HashTable基于JDK 1.7.0_67.源码见这里 1. 时间 HashTable产生于JDK 1.1,而HashMap产生于JDK ...
- Python自学:第三章 索引从0开始而不是从1
#返回最后一个,和倒数第二个元素 bicycles = ['trek','cannondale','redline','specialized'] print(bicycles[-1]) print( ...
- oracle导出大数据
Sqluldr是什么:是一个oracle数据导出小工具. Sqluldr作用介绍:Sqluldr可以快速导出oracle数据库中的数据.该小工具可以将数据库中的数据,导出多种不同的格式(如.txt.. ...
- Ubuntu用android-ndk-r15c编译boost_1_65_1
方法一(最简单的): 下载:android-ndk-r16-beta1 然后下载Boost-for-Android:https://github.com/moritz-wundke/Boost-for ...
- day050 django第一天 自定义框架
1.简单的web框架 1. 创建一个简单的python文件: import socket sever=socket.socket() sever.bind(('127.0.0.1',8001)) se ...
- Linux之expr命令详解
expr命令: expr命令是一个手工命令行计数器,用于在UNIX/LINUX下求表达式变量的值,一般用于整数值,也可用于字符串. –格式为: expr Expression(命令读入Expressi ...
- 长字符串换行word-break
word-break: break-all,每个字符换行 word-break: break-word按照单词换行,长字符之间换行
- 第一个java程序以及java的运行机制
课堂要点: 编写第一个java程序以及理解java的运行机制. 1.基本命令介绍: javac命令: 编译java文件得到.class字节码文件 -encoding 参数:指定编译的编码 java命令 ...
- 莫烦tensorflow(5)-训练二次函数模型并用matplotlib可视化
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt def add_layer(inputs,in_siz ...
- JDBC ---获取数据字段 -- 转成map
getConn = JdbcDataBaseUtil.getConnection(user,pwd,serverUrl,mysqDriver); //建立一个结果集,用来保存查询出来的结果 Resul ...