多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式。 之前打算在sqlplus中用执行计划的,但是格式看起来有点乱,就用Toad 做了3个截图。

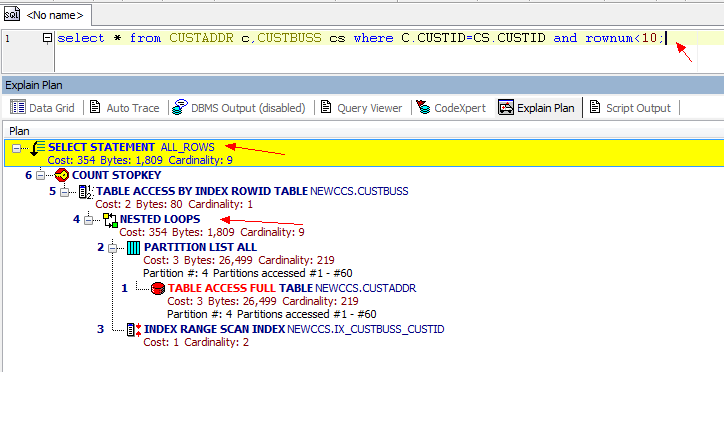
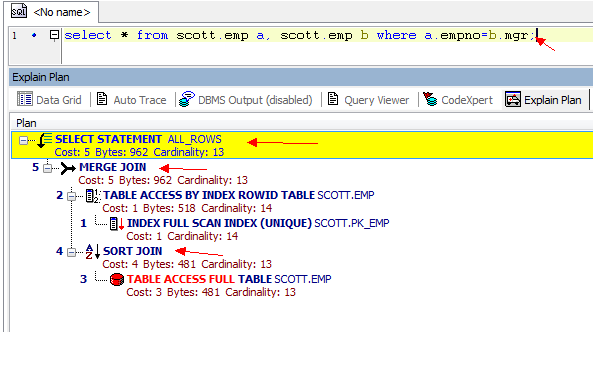
从3张图里我们看到了几点信息:
- CBO 使用的ALL_ROWS模式
Oracle Optimizer CBO RBO
http://blog.csdn.net/tianlesoftware/archive/2010/08/19/5824886.aspx
- 表之间的连接用了hash Join, Nested loops,Sort Merge Join
多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join. 下面来介绍三种不同连接的不同:
一. NESTED LOOP:
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表(CBO 默认外表是驱动表),而且在内表的连接字段上一定要有索引。当然也可以用ORDERED 提示来改变CBO默认的驱动表,使用USE_NL(table_name1 table_name2)可是强制CBO 执行嵌套循环连接。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候.
步骤:确定一个驱动表(outer table),另一个表为inner table,驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且inner表需要有有效的访问方法(Index)。需要注意的是:JOIN的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间是最快的。
cost = outer access cost + (inner access cost * outer cardinality)
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
| 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
| 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
EMPLOYEES为outer table, JOBS为inner table.
二. HASH JOIN :
散列连接是CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
也可以用USE_HASH(table_name1 table_name2)提示来强制使用散列连接。如果使用散列连接HASH_AREA_SIZE 初始化参数必须足够的大,如果是9i,Oracle建议使用SQL工作区自动管理,设置WORKAREA_SIZE_POLICY 为AUTO,然后调整PGA_AGGREGATE_TARGET 即可。
Hash join在两个表的数据量差别很大的时候.
步骤:将两个表中较小的一个在内存中构造一个HASH表(对JOIN KEY),扫描另一个表,同样对JOIN KEY进行HASH后探测是否可以JOIN。适用于记录集比较大的情况。需要注意的是:如果HASH表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘的temporary segment,则会多一个写的代价,会降低效率。
cost = (outer access cost * # of hash partitions) + inner access cost
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 665 | 13300 | 8 (25)|
| 1 | HASH JOIN | | 665 | 13300 | 8 (25)|
| 2 | TABLE ACCESS FULL | ORDERS | 105 | 840 | 4 (25)|
| 3 | TABLE ACCESS FULL | ORDER_ITEMS | 665 | 7980 | 4 (25)|
--------------------------------------------------------------------------
ORDERS为HASH TABLE,ORDER_ITEMS扫描
三.SORT MERGE JOIN
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。可以使用USE_MERGE(table_name1 table_name2)来强制使用排序合并连接.
Sort Merge join 用在没有索引,并且数据已经排序的情况.
cost = (outer access cost * # of hash partitions) + inner access cost
步骤:将两个表排序,然后将两个表合并。通常情况下,只有在以下情况发生时,才会使用此种JOIN方式:
1.RBO模式
2.不等价关联(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4.数据源已排序
四. 三种连接工作方式比较:
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能。
整理自网络
http://blog.csdn.net/tianlesoftware/article/details/5826546
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP的更多相关文章
- 多表连接的三种方式详解 hash join、merge join、 nested loop
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式.多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join.具体适用哪 ...
- 多表连接的三种方式 HASH MERGE NESTED
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP------------------------------------------------------20 ...
- Spring依赖注入三种方式详解
在讲解Spring依赖注入之前的准备工作: 下载包含Spring的工具jar包的压缩包 解压缩下载下来的Spring压缩包文件 解压缩之后我们会看到libs文件夹下有许多jar包,而我们只需要其中的c ...
- React中使用 react-router-dom 路由传参的三种方式详解【含V5.x、V6.x】!!!
路由传值的三种方式(v5.x) params参数 //路由链接(携带参数): <Link to='/demo/test/tom/18'}>详情</Link> //或 <L ...
- springmvc 异常统一处理的三种方式详解
1 描述 在J2EE项目的开发中,不管是对底层的数据库操作过程,还是业务层的处理过程,还是控制层的处理过程,都不可避免会遇到各种可预知的.不可预知的异常需要处理.每个过程都单独处理异常,系统的代码耦 ...
- Mysql 删除数据表的三种方式详解
用法: 1.当你不再需要该表时, 用 drop; 2.当你仍要保留该表,但要删除所有记录时, 用 truncate; 3.当你要删除部分记录或者有可能会后悔的话, 用 delete. 删除强度:dro ...
- mysql备份的三种方式详解
一.备份的目的 做灾难恢复:对损坏的数据进行恢复和还原需求改变:因需求改变而需要把数据还原到改变以前测试:测试新功能是否可用 二.备份需要考虑的问题 可以容忍丢失多长时间的数据:恢复数据要在多长时间内 ...
- 【基于初学者的SSH】struts02 数据封装的三种方式详解
struts的数据封装共有3中方式,属性封装,模型驱动封装和表达式封装,其中表达式封装为常用 一:属性封装: 属性封装其实就是自己定义变量,注意变量名要和表单的name属性名一致,然后生成get和se ...
- 基于JavaScript 声明全局变量的三种方式详解
原文地址:http://www.jb51.net/article/36548.htm JS中声明全局变量主要分为显式声明或者隐式声明下面分别介绍. 声明方式一: 使用var(关键字)+变量名(标识符) ...
随机推荐
- swipe js bug
最近因为要写新的mobile site页面,有好几个页面上面必须用到photo slider. 使用插件: /* * Swipe 2.0 * * Brad Birdsall * Copyright 2 ...
- php连接微软MSSQL(sql server)完全攻略
http://www.jb51.net/article/98364.htm php连接微软MSSQL(sql server)完全攻略 作者:吵吵 字体:[增加 减小] 类型:转载 时间:2016-11 ...
- TFS Training for Kunlun bank (http://www.klb.cn/) 微软研发流程(ALM)管理培训会议(昆仑银行) 2016.09.21
银行一直是微软技术的伤心地,由于历史原因,微软技术和产品一直很难进入到银行业务的核心区域,但是微软今年来的进步不少,在开发工具和平台方面已经连续攻克了几个典型的金融企业,例如农业银行,中国人保等. 应 ...
- kylin的配置账号密码的加密方法
kylin的配置账号密码的加密方法 kylin安装过程中,配置账户,其中密码是加密的.生成密码对应密文的 方法如下: import java.io.PrintStream; import org.sp ...
- 在AbpZero中hangfire后台作业的使用——开启hangfire
AbpZero框架已经集成了hangfire,但它默认是关闭的,我们可以在运行站点下的Startup.cs文件中把这行代码注释取消就行了,代码如下: //Hangfire (Enable to ...
- js 利用数组实现类似于asp中的数据字典
---恢复内容开始--- 首先声明一个数组 var dictNew=new Array; var key; var value; for (var i = 0; i <50; i++) { // ...
- C#扩展一个现有的类
做个记录,写个示例 using System; class Rubbish { public void Say() { Console.Write("Hello"); } } st ...
- 使用Spring Boot,Spring Cloud和Docker实现微服务架构
https://github.com/sqshq/PiggyMetrics Microservice Architecture with Spring Boot, Spring Cloud a ...
- Day 11 作业题
1.整理装饰器的形成过程,背诵装饰器的固定格式 固定格式 def wrapper(func): def inner(*args, **kwargs): #执行函数前进行的操作 ret = func(* ...
- OI动态规划&&优化 简单学习笔记
持续更新!! DP的难点主要分为两类,一类以状态设计为难点,一类以转移的优化为难点. DP的类型 序列DP [例题]BZOJ2298 problem a 数位DP 常用来统计或者查找一个区间满足条件的 ...