大数据中HBase的Java接口封装
该文前提为已经搭建好的HBase集群环境,参见 HBase集群搭建与配置 ,本文主要是用Java编写一个Servlet接口,部署在Tomcat服务器上,用于提供http的接口供其他地方调用,接口中集成了一些简易HBase操作,有需要可以再继续扩展。
软件环境:
IntelliJ IDEA、Hadoop-2.9.2、HBase-1.4.9
Jar包引入
程序所需jar包,基本在HBase的lib目录下都能找到,该文因暂时没使用MapReduce,因此只需如下jar包
在File->Project Structure->Libraries中添加如下jar包
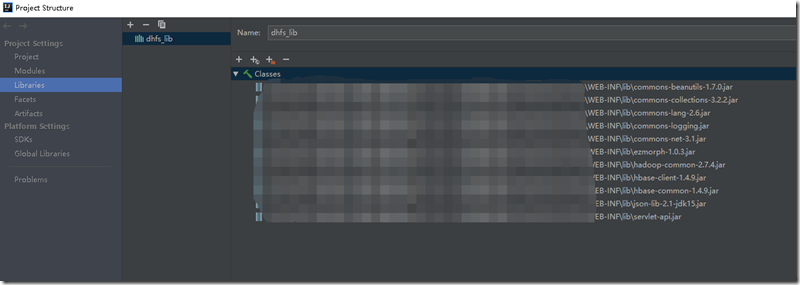
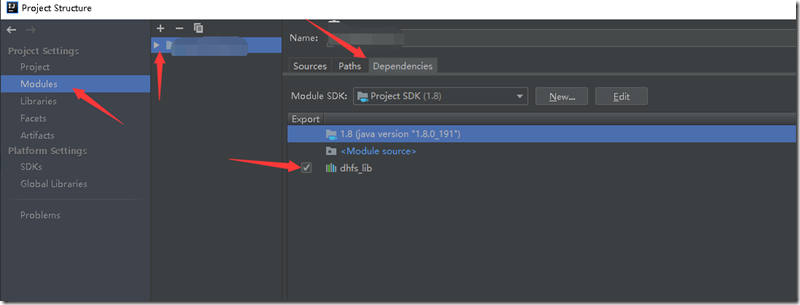
并在Modules中选中站点根目录,Dependencies页签,将lib加入项目
我直接继承的HttpServlet,重构了doGet与doPost函数,也可以直接继承Servlet自己来实现细节,Servlet创建方法请参照网上其他教程,这里自己封装了JsonResult,接口返回均使用json格式,实现了4种接口,具体如下
基础设施
这里创建了几个基础文件:hdfs.properties、HBaseProperties、HBaseHelper具体信息如下
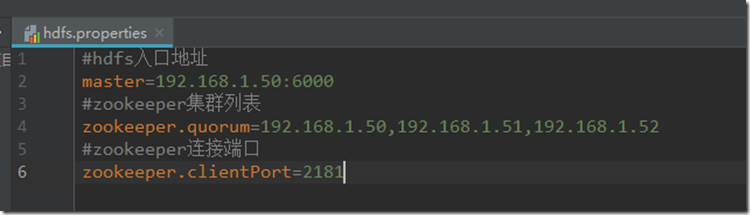
hdfs.properties配置文件用于配置HBase的连接参数
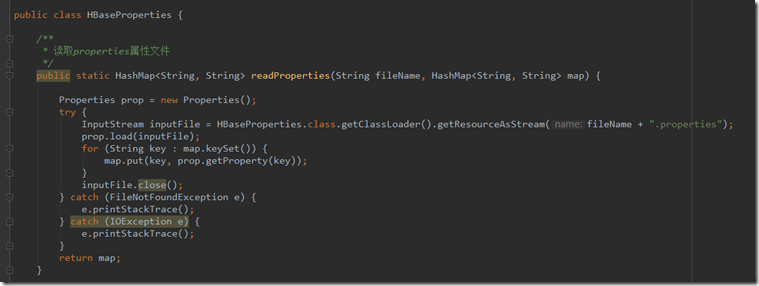
HBaseProperties类用于封装的获取配置文件的代理,获取配置信息,并返回map值
HBaseHelper封装的是HBase具体的操作,其中configuration是配置信息,从配置文件获取后写入,然后创建connection连接
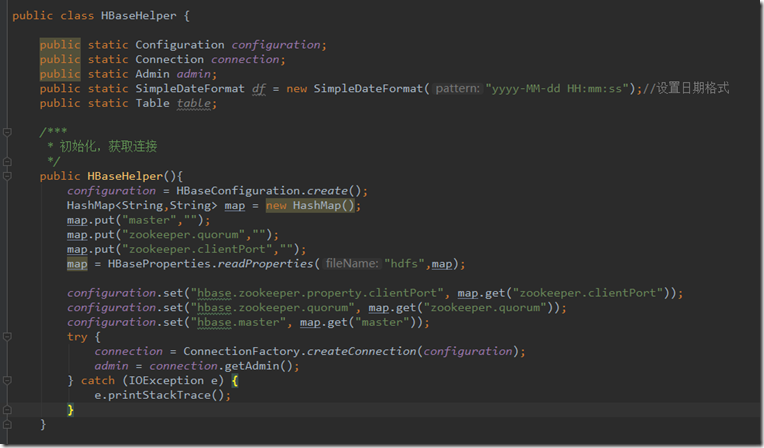
还有一点需要注意的是想运行并连接上集群,需要在部署Tomcat的服务器上配置环境变量HADOOP_HOME,指向hadoop的根目录,并将winutils.exe等相关文件拷贝到hadoop中bin目录下,具体文件如下

以上文件可以参考github中的开源代码自己生成所需版本 https://github.com/steveloughran/winutils
HBase创建表
这里参数tbName为要创建的表名,familylist为列簇的字符串数组
过程为判断表是否存在,不存在则遍历familylist,获取列簇名称添加到表描述中,最后创建改表

插入数据
插入数据一共写了3个
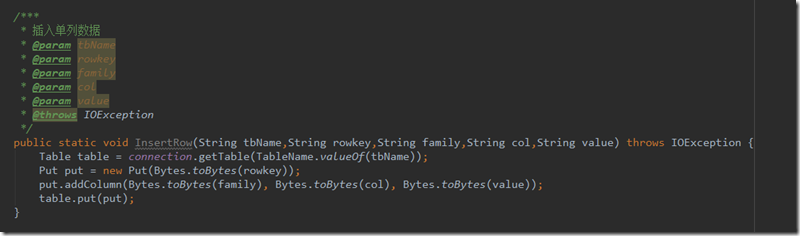
1.插入某行,某列簇,某列的数据,可以用于修改或者特殊插入,代码如下
参数分别是tbName表名、rowkey行名、family列簇名、col列名、value具体的值
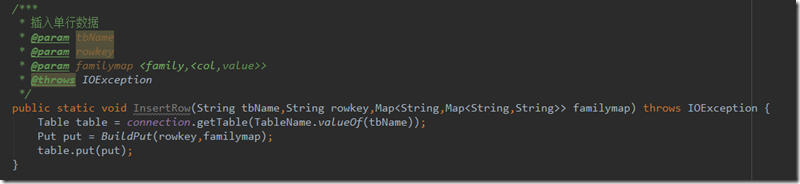
2.插入一行数据,代码如下
其中familymap是一个hashmap,key为列簇,value是一个键值对的map,这个map为该列簇下列名与数据的键值对
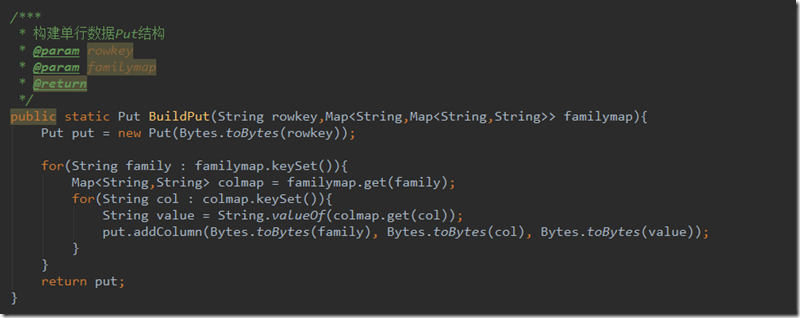
其中函数BuildPut构建put函数封装如下
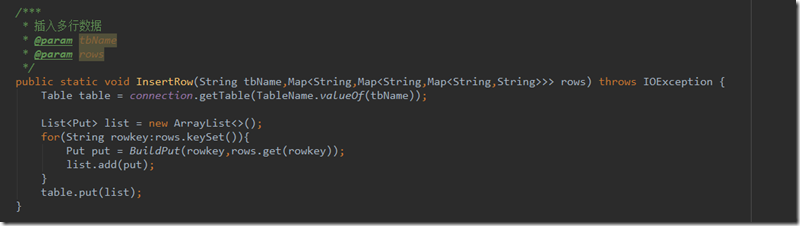
3.插入多行数据,也是使用最多的函数
其中rows是hashmap类型,key为rowkey,value为函数2中的familymap,遍历所有rowkey,通过BuildPut构建出来,加入table中,需要注意的是rowkey的设计,需要注意防止数据倾斜。业务上这里因为有大量设备周期性发送数据,因此我用的设备编号hash后,取前8位加上时间戳来作为rowkey
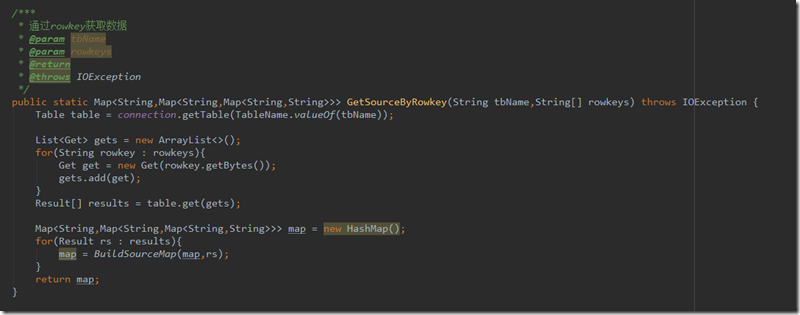
通过rowkey查询指定列
这里传入参数tbName为表名,rowkeys为rowkey的字符串数组,通过遍历rowkeys,生成Get并加入table查询,最后查询结果Result通过构建函数BuildSourceMap构建为之前那种map格式,最后通过json转换返回给调用接口
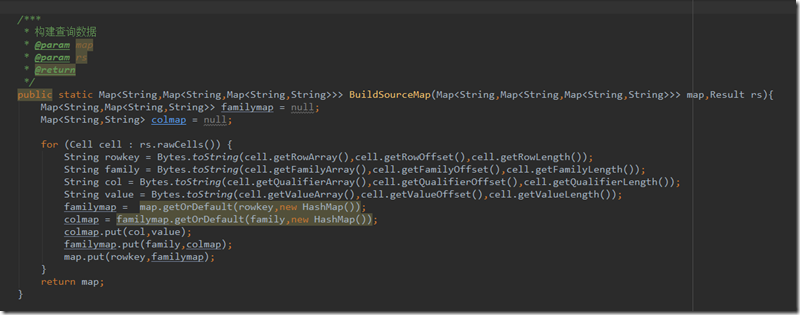
其中BuildSourceMap构建函数如下
将获取到的数据遍历,然后逐步加入列的map、列簇的map、最终的map并返回
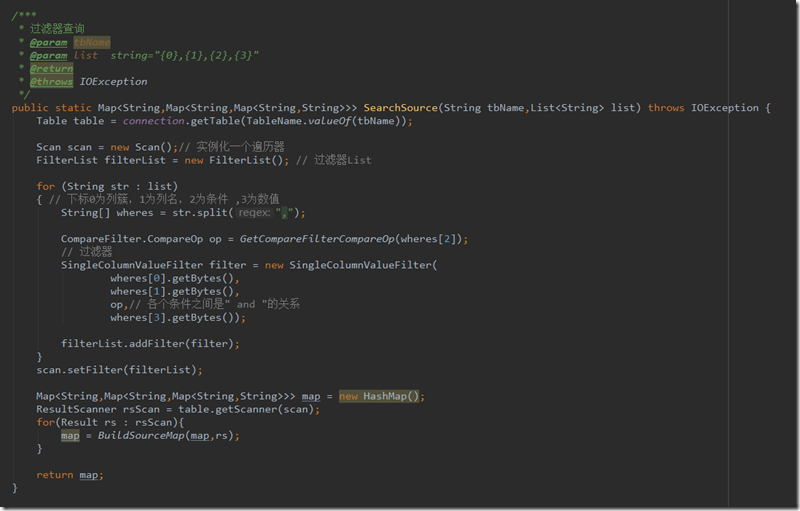
通过Scan模糊匹配查询
一共封装了2种模糊匹配,一种是带了列簇名称,一种是未带,没有带列簇的将会遍历所有列簇,并加入过滤条件中
1.带了列簇信息,其中list过滤条件中格式规定如下
string="{0},{1},{2},{3}"
其中0为列簇名称,1为列名称,2为匹配操作符,3为匹配的值
查询到的结果通过函数BuildSourceMap构建为map返回,操作符匹配CompareOp的函数如下
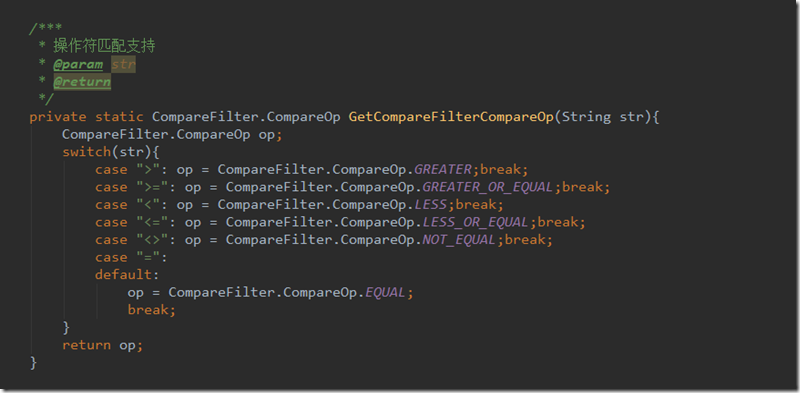
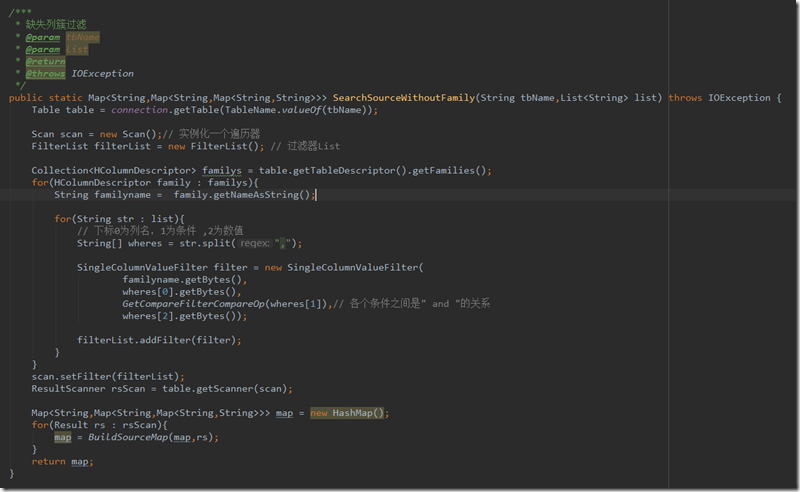
2.不带列簇信息,其中list过滤条件中格式规定如下
string="{0},{1},{2}"
其中0为列名称,1为匹配操作符,2为匹配的值
至此HBase的一些常用操作就封装完毕了,只需要打包发布部署上就可以使用了,后续还会写一篇C#封装的用于提供C#后端调用,而底层对接该接口的类库,这样就可以串起来用了
大数据中HBase的Java接口封装的更多相关文章
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据之HBase
大数据之HBase数据插入优化之多线程并行插入实测案例 一.引言: 上篇文章提起关于HBase插入性能优化设计到的五个参数,从参数配置的角度给大家提供了一个性能测试环境的实验代码.根据网友的反馈,基于 ...
- Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考. 1. 建 ...
- 学大数据一定要会Java开发吗?
Java是目前使用广泛的编程语言之一,具有的众多特性,特别适合作为大数据应用的开发语言.Java语言功能强大和简单易用,不仅吸收了C++语言的各种优点还摒弃了C++里难以理解的多继承.指针等概念. J ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- NoSQL在大数据中的应用
一.序言 NoSQL是Not Only SQL的缩写,而不是Not SQL,指的是非关系型的数据库,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准.ACID属性.表结构等等.相比传统数据库 ...
- 大数据开发--Hbase协处理器案例
大数据开发--Hbase协处理器案例 1. 需求描述 在社交网站,社交APP上会存储有大量的用户数据以及用户之间的关系数据,比如A用户的好友列表会展示出他所有的好友,现有一张Hbase表,存储就是当前 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- 大数据学习——Hbase
1. Hbase基础 1.1 hbase数据库介绍 1.简介 hbase是bigtable的开源java版本.是建立在hdfs之上,提供高可靠性.高性能.列存储.可伸缩.实时读写nosql的数据库系统 ...
随机推荐
- LVS 原理(调度算法、四种模式、四层负载均衡和七层 的区别)
参考文档:http://blog.csdn.net/ioy84737634/article/details/44916241 目录 lvs的调度算法 lvs的四种模式 四层均衡负载和七层的区别 1.l ...
- September 20th 2017 Week 38th Wednesday
All our dreams can come true if we have the courage to pursue them. 如果我们有勇气去追求梦想,我们的梦想一定可以成为现实. If y ...
- Django 通过APNS推送消息
最近手上一个项目需要通过APNS向app推送消息,由于后端采用drf框架,在github上找了好多模块,最终发现pzanitti大神的推送模块 django-push-notifications 比较 ...
- Java Classloader机制解析
做Java开发,对于ClassLoader的机制是必须要熟悉的基础知识,本文针对Java ClassLoader的机制做一个简要的总结.因为不同的JVM的实现不同,本文所描述的内容均只限于Hotspo ...
- shell批量远程连接mysql的方法
一.配置mysql服务器ip列表如下,可自定义: S1 1.1.1.1 3306 user passwd11 dbname_s1S2 2.2.2.2 3306 u ...
- [JLOI2009]二叉树问题
嘟嘟嘟 对于求深度和宽度都很好维护.深度dfs时维护就行,宽度统计同一个深度的节点有多少个,然后取max. 对于求距离,我刚开始以为是要走到根节点在回来,然后固输了(dep[u] - 1) * 2 + ...
- virtualbox+vagrant学习-2(command cli)-11-vagrant PowerShell命令
PowerShell 格式: vagrant powershell [-- extra powershell args] 这将在主机上打开PowerShell提示符,进入正在运行的vagrant机器. ...
- 多线程之并发容器ConcurrentHashMap(JDK1.6)
简介 ConcurrentHashMap 是 util.concurrent 包的重要成员.本文将结合 Java 内存模型,分析 JDK 源代码,探索 ConcurrentHashMap 高并发的具体 ...
- 关于 MFRC522引脚功能图
MFRC522是属于13.56mhz芯片.另外SI522也是13.56mhz芯片,SI522 PIN对PIN完全兼容MFRC522,并且软硬件兼容,且引脚功能图都是一样的,功能方面比MFRC522多A ...
- 再起航,我的学习笔记之JavaScript设计模式07(抽象工厂模式)
我的学习笔记是根据我的学习情况来定期更新的,预计2-3天更新一章,主要是给大家分享一下,我所学到的知识,如果有什么错误请在评论中指点出来,我一定虚心接受,那么废话不多说开始我们今天的学习分享吧! 前两 ...