大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeeper与hbase的部署与配置,常见hbase shell命令
选件版本选择:
选举机制:Zookeeper-3.4.12,部署3台,50、51、52
分布式列式数据库:HBase-1.4.9,主机50,从机51、52、53
安装配置Zookeeper集群
这里可以选择不安装Zookeeper,而使用HBase自带的Zookeeper,不过这里还是介绍一下Zookeeper的安装配置
上传Zookeeper

解压Zookeeper
tar -zxvf zookeeper-3.4.12.tar.gz -C /cloud/
配置zookeeper
cd /cloud/zookeeper-3.4.12/conf/
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
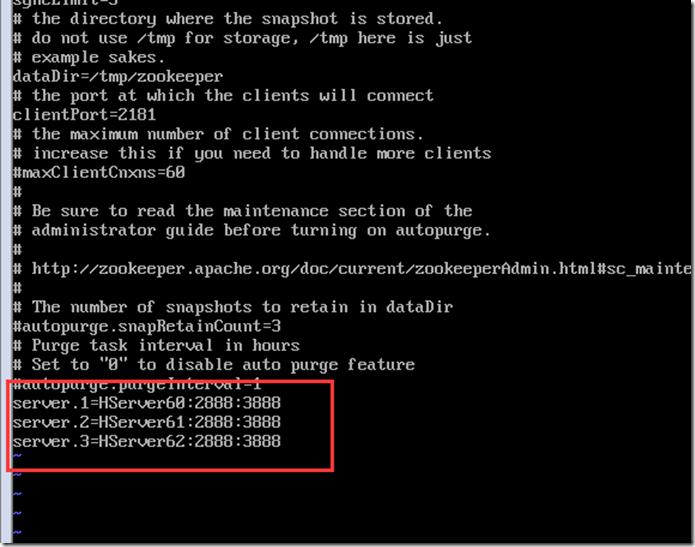
创建对应ID,在60上为1,61上为2,62为3
cd /cloud/zookeeper-3.4.12
mkdir tmp
vi tmp/myid
输入对应ID,保存,zookeeper配置完毕
安装配置HBase集群
上传解压hbase

tar -zxvf hbase-1.4.9-bin.tar.gz -C /cloud/
进入HBase配置文件目录
cd /cloud/hbase-1.4.9/conf/
配置hbase-env.sh
vi hbase-env.sh
设置jdk路径与hbase的配置路径
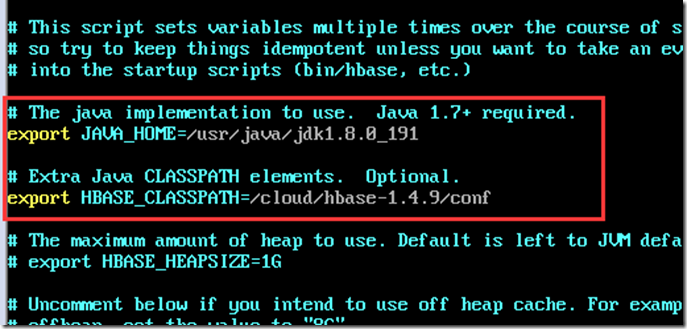
设置是否使用hbase自带的zookeeper

配置从机节点
vi regionservers
配置为从机的HServer51、HServer52、HServer53

配置hbase-site.xml
vi hbase-site.xml
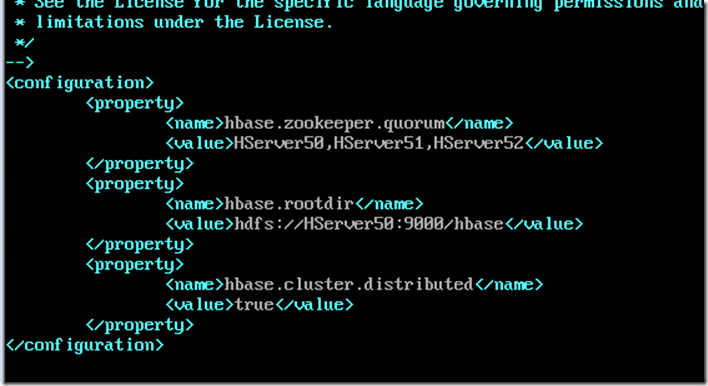
可以将配置好的hbase通过scp命令复制到其他从机上,整个hbase配置完毕,测试hbase是否成功
hbase的运行命令在hbase/bin目录下,可以将该路径加入/etc/profile中
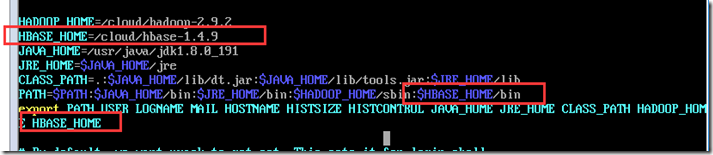
启动hbase
start-hbase.sh
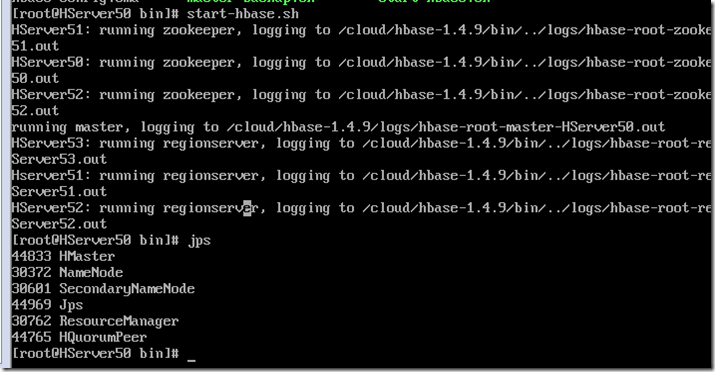
主机上jps可以看到HMaster
从机上可以看到HRegionServer
配置了zookeeper节点的可以看到HQuorumPeer
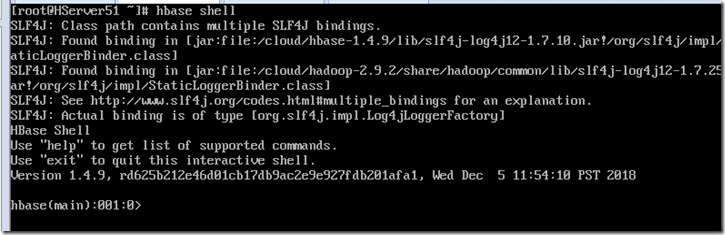
HBase Shell
从机上通过hbase shell初步尝试使用hbase
hbase shell
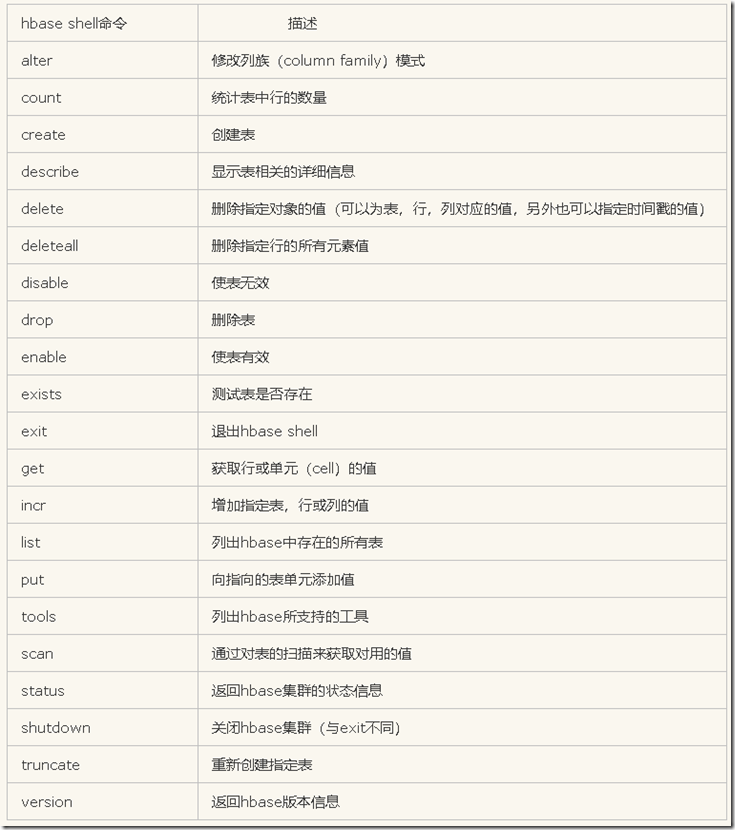
常用命令如下:
大数据中HBase集群搭建与配置的更多相关文章
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
- 大数据-hadoop HA集群搭建
一.安装hadoop.HA及配置journalnode 实现namenode HA 实现resourcemanager HA namenode节点之间通过journalnode同步元数据 首先下载需要 ...
随机推荐
- 一、TCL事务控制语言 二、MySQL中的约束 三、多表查询(重点) 四、用户的创建和授权 五、MySQL中的索引
一.TCL事务控制语言###<1>事务的概念 事务是访问并可能更新数据库中各种数据项的执行单元. 事务是一条SQL语句,一组SQL语句,或者整个程序. 事务是恢复和并发控制的基本单位. 事 ...
- python模拟老师授课下课情景
# -*- coding:utf-8 -*- import time class Person(object): ''' 定义父类:人 属性:姓名,年龄 方法:走路(打印:姓名+“正在走路”) ''' ...
- Istio 1.1尝鲜记
近几天Istio1.1的发布引起了技术界巨大的反响,为了让更多技术爱好者能够亲自体验Istio1.1,公司的技术大佬赶出了这篇尝鲜教程,其中包括环境.安装.可能遇到的问题及解决方式等,希望对大家有所帮 ...
- Android混合式开发(Hybrid)
安卓混合式开发(Hybrid) 1 环境搭建 1.1 首先,下载 Android Studio (Intellij Idea) 下载地址:http://www.android-studio.org/ ...
- 缓冲区溢出基础实践(一)——shellcode 与 ret2libc
最近结合软件安全课程上学习的理论知识和网络资料,对缓冲区溢出漏洞的简单原理和利用技巧进行了一定的了解.这里主要记录笔者通过简单的示例程序实现缓冲区溢出漏洞利用的步骤,按由简至繁的顺序,依次描述简单的 ...
- [转]IE9.0或者360下js(JavaScript、jQuery)不能正确执行(加载),按F12后执行正常;Firefox下ajax的success返回数据data(json、string)无法获取
兼容问题1: 页面的分享等插件加载不全,并无法点击. 兼容问题2: IE下页面选择器(#id..class.etc.)绑定click事件无法访问到,后台springmvc方法,也无法获取ajax的su ...
- 20145203盖泽双 《Java程序设计》第五周学习总结
20145203盖泽双 <Java程序设计>第五周学习总结 教材学习内容总结 1.Java中所有错误都会被打包为对象,运用try.catch,可以在错误发生时显示友好的错误信息,还可以在捕 ...
- robotframwork的WEB功能测试(二)—登录
小结一下截止到目前,我接触的系统的登录模拟. 1. 带token的session:这种用抓包工具很容易抓到,使用这个链接就可以模拟已登录. 2. 使用cookie:有的系统是判断cookie来判断是否 ...
- JQuery Validate插件与实现
菜鸟拙见,望请纠正 一:效果展示:以下是两个注册表单验证,左边使用Jquery validate插件实现,右边是自己用JQuery实现,效果差不多,但个人推荐用插件,毕竟前人栽了树而且长大了后人当然好 ...
- transform CSS3 2D知识点汇总
transform转换属性的5个值: 1. translate(x值,y值) 移动效果. 2.rotate(45deg) 旋转效果. 3.scale(x轴倍数,y轴倍数) 缩放效果. 4.ske ...