理解HDFS
综述
当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上。HDFS是hadoop的主要分布式存储系统,一个HDFS集群主要包括NameNode用来管理文件系统的metadata,DataNode用来存储实际的数据。下面是HDFS的一些特点
- 1.Hadoop包括HDFS是一个分布式存储和分布式计算的架构,部署在商用硬件上面,它具有容错性、可扩展和容易扩大规模等特点。MapReduce作为Hadoop的一个组件常被用于处理大规模的分布式应用
- 2.HDFS的默认configuration能够适用于多数环境,除非是超大规模的集群可能是需要进行微调
- 3.Hadoop是由java语言开发,具有容易移植的特点
- 4.Hadoop可以通过shell来控制HDFS,NameNode和DataNode可以通过内置的web server来查看他们的运行状态
HDFS体系结构
HDFS采用master/slave架构。一个HDFS集群一般有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制

NameNode的工作机制
NameNode是整个系统的管理节点,它维护这整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求
维护文件包括:
- 1.fsimage:整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等
- 2.edits:hadoop对于任何对文件系统元数据产生修改的操作
- 3.fstime:保存最近一次checkpoint的时间
- 4.NN始终再内存中保存metadata,用于处理请求
- 5.当有"写"请求到来时,NN会首先写到edit log到磁盘(向edits文件中写日志)成功后返回后才会去修改内存,并向客户端返回
- 6.NN会维护一个fsimage文件,也就是metadata的
镜像,但是fsimage不会随时与NN内存中的metadata保持一致,而是每隔一段时间通过合并edits文件来更新内容(secondary NN是用来合并fsimage和edits文件来更新NN的metadata)
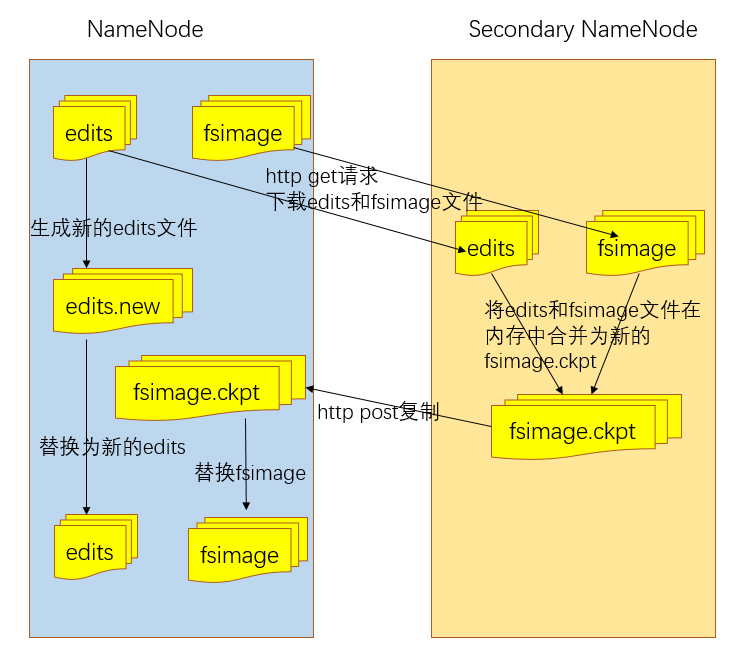
Secondary NameNode(伪分布式或者非HA)
当NameNode启动时,它首先需要从fsimage读取HDFS的状态,然后从edit log file读取edits的信息。NameNode再将新的HDFS的状态写入到fsimage和新建一个空的edits file。在启动阶段,NameNode需要合并fsimage和edits file,edits log file在一个忙碌的集群中文件大小会变得很大,这会导致在重启NameNode时候耗费较长的时间。
Secondary NameNode定期的合并fsimage和edits log 并保持edits log文件在一个适度的大小,它往往运行在不同的机器上面。在启动Secondary NameNode上checkpoint过程主要收到两个参数的 影响
dfs.namenode.checkpoint.period:默认的是1 hour,两次连续的checkpoint的最大时间间隔dfs.namenode.checkpoint.period:默认为1 million 超过这个大小就督促进行checkpointed transactions,即使时间间隔还没到
HDFS读取文件过程
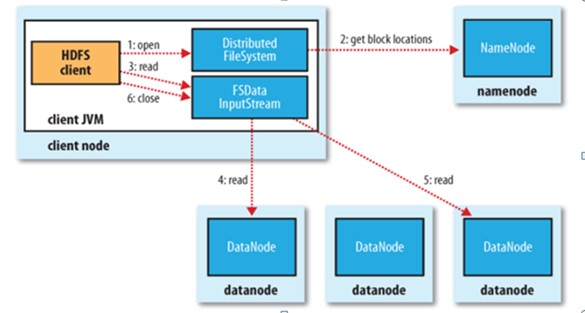
- 1.初始化FileSystem,然后客户端(client)使用FileSystem的open()函数打开文件
- 2.FileSystem用RPC调用元数据节点,得到文件的数据块信息,即知道数据块被存储在哪几个DataNode上
- 3.DistributedFileSystem返回一个FSDataInputStream对象给客户端,以便读取数据,客户端对这个输入流调用 read()方法
- 4.FSDataInputStream连接距离最近的datanode,反复调用read方法,将数据返回到客户端
- 5.读取结束。客户端直接从DataNode上读取文件,在此过程中NN不参与文件的传输slave通过RPC请求master,master的方法会被调用
HDFS写文件过程
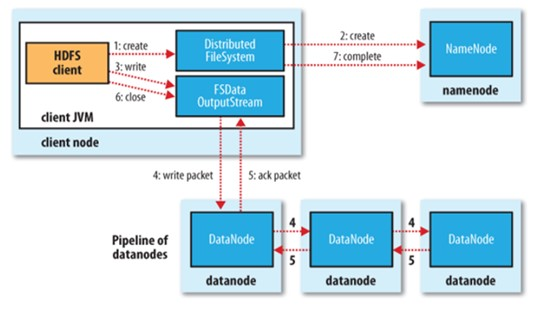
- 1.上传文件test.log为例子,client向NN发起写的请求,通过RPC与NN建立连接
- 2.NN会根据文件大小和文件块配置情况,返回给它所管理的DataNode的信息
- 3.Client将文件划分成多个文件块,根据DataNode的地址信息将数据写入到DataNode中,假设副本数目为3,Hadoop的默认分布策略是:
- a.在运行客户端的节点上放1个副本,如果客户端是在集群之外就随机选择一个节点
- b.第二个副本放在与第一个不同的机架上
- c.第三个副本与第二个副本放在同一个机架上,且随机选择的另一个节点上。
下图是数据块的分布
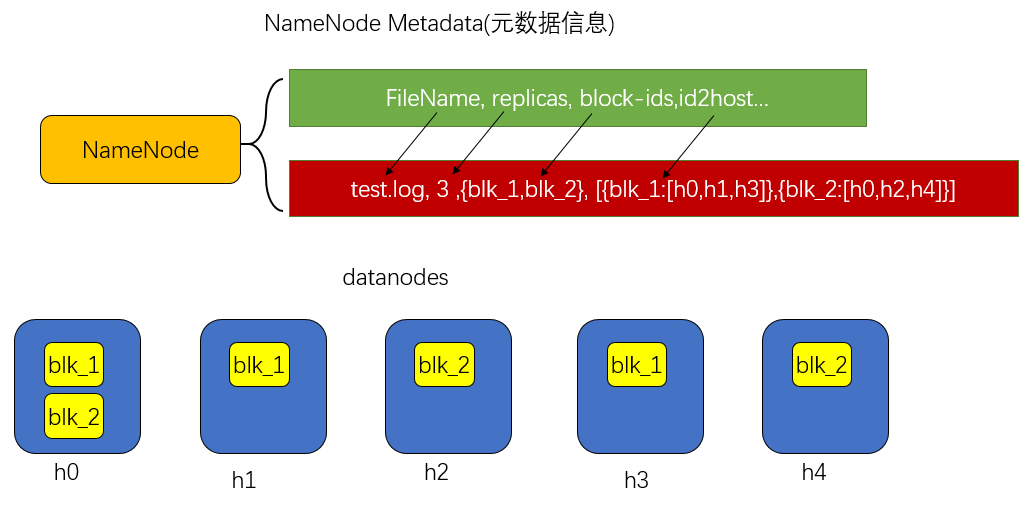
上传成功后NN始终在内存中保存metadata,用于处理读请求,metadata主要存储文件的名称FileName,副本数量replicas,分多少block存储block-ids,分别存储在哪几个节点上id2host。
Hadoop中的RPC机制
上面讲了那么多不同角色之间的交互,这些进程间的交互都是通过RPC(Remote Procdure Call,远程过程调用)来进行的,它允许一个进程去访问另一个进程的方法,这些对于用户都是透明的,可以说Hadoop的运行是建立在RPC基础之上的,在了解RPC之前我们需要先了解一项技术动态代理,动态代理可以提供对另一个对象的访问,同时隐藏实际对象的具体事实,代理对象对客户隐藏了实际对象。在Hadoop中DataNode端是通过获得NameNode的代理,通过该代理和NameNode进行通信的,为了更好的分析hadoop的RPC机制我想先分析一下动态代理是怎么实现。
目前Java开发包中提供了对动态代理的支持,但现在只支持对接口的实现,我们需要定义一个接口。
interface DynamicService {
public void show();
}
当实现动态代理的时候,需要实现InvocationHandler类,并且覆写其Invoker方法
class ClassA implements DynamicService {
@Override
public void show() {
System.out.println("this is class A");
}
}
class ClassB implements DynamicService {
@Override
public void show() {
System.out.println("this is class B");
}
}
class Invoker implements InvocationHandler {
DynamicService ds;
public Invoker(DynamicService ds) {
this.ds = ds;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
//add some dynamic methods here
method.invoke(ds, args);
//after
return null;
}
}
下面是例子的测试
public static void main(String[] args) {
Invoker inv1 = new Invoker(new ClassA());
DynamicService ds = (DynamicService) Proxy.newProxyInstance(DynamicService.class.getClassLoader(),
new Class[] {DynamicService.class}, inv1);
ds.show();
//添加另外一个
Invoker inv2 = new Invoker(new ClassB());
DynamicService dss = (DynamicService) Proxy.newProxyInstance(DynamicService.class.getClassLoader(),
new Class[] {DynamicService.class}, inv2);
dss.show();
}
现在我们就需要去实现Hadoop RPC,主要分为以下几步
- 1.定义RPC协议:RPC是客户端与服务器通信接口,它定义了服务器对对外提供的服务接口
- 2.实现RPC协议:Hadoop RPC通常方式一个Java 接口,用户需要自己去实现接口
- 3.构造和启动器哦那个RPC服务:使用静态类Builder构造一个RPC Server,并通过start()方法启动该server
- 4.构造RPC Client 并发送请求:使用RPC.getProxy()构造客户端代理对象,通过代理对象访问远程端的方法
有了上面的几步,我们现在就可以自己写一个RPC小程序了
定义一个接口
public interface RPCService {
public static final long versionID = 10010L;//版本号,不同版本号的RPC Client和Server之间不能相互通信
public String sayHi(String name);
}
实现接口并构造RPC Server服务
public class RPCServer implements RPCService {
@Override
public String sayHi(String name) {
return "server response"+name;
}
public static void main(String[] args) throws HadoopIllegalArgumentException, IOException {
Configuration conf = new Configuration();
Server server = new RPC.Builder(conf)//
.setProtocol(RPCService.class)//
.setBindAddress("10.30.100.11")// 服务器地址
.setPort(1234)//端口
.setInstance(new RPCServer())// 设置托管对象
.build();
server.start();
}
}
启动服务器之后,服务器就在指定端口监听客户端的请求。服务器就处于监听状态等待客户端请求到达。
构造RPC Client并发出请求
public class RPCClient {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//接口类型,就可以调用接口中的方法.在客户端获取代理对象,有了代理对象就可以调用目标对象(RPCServer)的方法了
RPCService proxy = RPC.getProxy(RPCService.class,
10010, new InetSocketAddress("10.30.100.11", 1234), conf);//server的代理对象,server必须实现这个接口
String result = proxy.sayHi("boyaa");
System.out.println(result);
RPC.stopProxy(proxy);
}
}
理解HDFS的更多相关文章
- 再理解HDFS的存储机制
再理解HDFS的存储机制 1. HDFS开创性地设计出一套文件存储方式.即对文件切割后分别存放: 2. HDFS将要存储的大文件进行切割,切割后存放在既定的存储块(Block)中,并通过预先设定的优化 ...
- 深入理解HDFS分布式文件系统
深入理解HDFS:Hadoop分布式文件系统: https://blog.csdn.net/bingduanlbd/article/details/51914550
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- 理解HDFS高可用性架构
在Hadoop1.x版本的时候,Namenode存在着单点失效的问题.如果namenode失效了,那么所有的基于HDFS的客户端——包括MapReduce作业均无法读,写或列文件,因为namenode ...
- 深入理解HDFS的架构和原理
(一) HDFS主要是用于做什么的? HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处 ...
- Hadoop HDFS (3) JAVA訪问HDFS之二 文件分布式读写策略
先把上节未完毕的部分补全,再剖析一下HDFS读写文件的内部原理 列举文件 FileSystem(org.apache.hadoop.fs.FileSystem)的listStatus()方法能够列出一 ...
- 从一般分布式设计看HDFS设计思想与架构
要想深入学习HDFS就要先了解其设计思想和架构,这样才能继续深入使用HDFS或者深入研究源代码.懂得了"所以然"才能在实际使用中灵活运用.快速解决遇到的问题.下面这篇博文我们就先 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
随机推荐
- vxworks下硬盘测速程序
void speed(int buflen,int mod){/*int mod = 0;*/ int len=50; FILE *fp; unsigned int i=0,j=0,tmp,tmp2; ...
- CAN控制器-配置过滤器
首先简单介绍一下CAN总线,关于CAN总线是谁发明的,CAN总线的历史,CAN总线的发展,CAN总线的应用场合,这些,通通不说.这里只是以我个人理解,简单说说CAN通信.CAN总线的端点没有地址(除非 ...
- PyCharm运行报编码错误
运行报如下错误: SyntaxError: Non-ASCII character '\xe8' in file /home/ubuntu/code/201803091253-text.py on l ...
- 分类导航菜单的制作(附源码)--HTML
不多说,直接贴代码哈!有疑问,可追加评论哈! demo.html: <!DOCTYPE html><html> <head> <title>分类导航菜单 ...
- Metrics.net + influxdb + grafana 构建WebAPI的自动化监控和预警
前言 这次主要分享通过Metrics.net + influxdb + grafana 构建WebAPI的自动化监控和预警方案.通过执行耗时,定位哪些接口拖累了服务的性能:通过请求频次,设置适当的限流 ...
- R语言-来自拍拍贷的数据探索
案例分析:拍拍贷是中国的一家在线借贷平台,网站撮合了一些有闲钱的人和一些急用钱的人.用户若有贷款需求,可在网站上选择借款金额. 本项目拟通过该数据集的探索,结合自己的理解进行分析,最终目的的是初步预测 ...
- PHPStorm 最新版 去掉参数提示 parameter name hints
最新的phpstorm有个默认开启的参数名和类型提示功能, 这对于开发有很大的帮助,但是对于有些同学来说,刚开始可鞥不是很习惯,所以就需要把他给关闭. 在 配置面板中搜索 parameter name ...
- webapi下的web请求
先看webapi提供的服务: [HttpPost] public ResultBaseModel SiteList(SiteModel param) { ResultBaseModel resultM ...
- c# 多线程同步之Mutex
说起Mutex,它的中文名字叫互斥体.它是WaitHandle家族成员之一,前面有一篇介绍过WaitHandle的家族成员构成.那么Mutex有什么作用呢?它是怎么使用的? 我们先来看看它的使用场景一 ...
- C++学习-4
1.一个类重写了operator(),可以f()-相当于匿名对象-f()()相当于调用operator()函数 把对象名当成函数名来使用--伪函数 2.通过成员函数创建多线程 a) 可以用成员函 ...