第十篇:Map/Reduce 工作机制分析 - 数据的流向分析
前言
在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议。
接下来,数据被会被送往一个个Map节点中去,这也无异议。
下面问题来了:数据在被Map节点处理完后,再何去何从呢?
这就是本文探讨的话题。
Shuffle
在Map进行完计算后,将会让数据经过一个名为Shuffle的过程交给Reduce节点;
然后Reduce节点在收到了数据并完成了自己的计算后,会将结果输出到Hdfs。
那么,什么是Shuffle阶段,它具体做什么事情?
需要知道,这可是Hadoop最为核心的所在,也是号称“奇迹出现的地方“ = =#
Shuffle具体分析
首先,给出官方对于Shuffle流程的示意图:
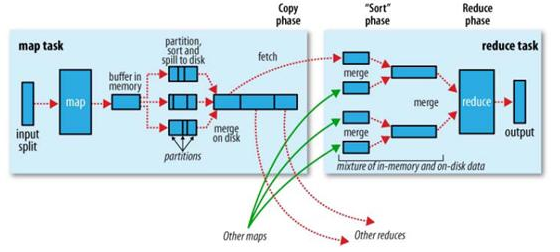
Shuffle过程植入于Map端和Reduce端两边
1. Map端工作:
a. 分区:根据键值对的Key值,选定键值对所属的Partition区间(与Reduce节点对应)。
b. 排序:对各分区内的键值对根据键进行排序。
c. 分割:Map端的结果先是存放在缓冲区内的,如果超出,自然就要执行分割的处理,将一部分数据发往硬盘。
d. 合并:对于要发送往同一个节点的键值对,我们需要对它进行合并。(这一步很可能针对硬盘,对于海量数据处理,缓冲区溢出是很正常的事情)
2. Reduce端工作:
a. Copy:以HTTP的方式从指定的Map端拉数据,注意是Map端的本地磁盘。
b. 合并:一个Reduce节点有可能从多个Map节点获取数据,获取到之后
c. 排序:对各分区内的键值对根据键进行排序。和Map端操作一样。
小结
对于这部分的内容,以后有机会做Hadoop性能方面的工作时,会继续学习研究。
第十篇:Map/Reduce 工作机制分析 - 数据的流向分析的更多相关文章
- 第九篇:Map/Reduce 工作机制分析 - 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce 工作机制分析 --- 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- 第十一篇:Map/Reduce 工作机制分析 - 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- Map/Reduce 工作机制分析 --- 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- 机器学习等知识--- map/reduce, python 读json数据。。。
map/ reduce 了解: 简单介绍map/reduce 模式: http://www.csdn.net/article/2013-01-07/2813477-confused-about-map ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- 2014年2月5日 Oracle ORACLE的工作机制[转]
网上看到一篇描写ORACLE工作机制的文章,觉得很不错!特摘录了下来. ORACLE的工作机制-1 (by xyf_tck) 我们从一个用户请求开始讲,ORACLE的简要的工作机制是怎样的,首 ...
- DataNode的工作机制
DataNode的工作机制 一个数据块在DataNode以文件的形式在磁盘上保存,分为两个文件,一个是数据本身, 一个是元数据信息(包括数据的长度,校验和,时间戳) 1.DataNode启动后,向Na ...
随机推荐
- 📉 Draggable Curve Control (English)
Conmajia 2012 Updated on Feb. 18, 2018 In Photoshop, there is a very powerful feature called Curve A ...
- PLECS_晶闸管调速系统_9w
3. 直流电机开环调压调速系统模型搭建 (1)电路图 (2)仿真 当 α = pi / 2.7 的时候,直流电机的稳定转速大约保持很低的速度. 随着α的减少,直流电机的速度逐渐增大.当α = pi / ...
- LNMP搭建02 -- 编译安装Nginx
[编译安装Nginx] 为了顺利安装Nginx,先安装下面这些: [CentOS 编译 nginx 前要做的事情] yum install gcc gcc-c++ kernel-devel yum ...
- 通过实例介绍Android App自动化测试框架--Unittest
1.为什么需要使用框架实现自动化测试 作为测试工程师,可能在代码能力上相比开发工程师要弱一点,所以我们在写脚本的时候就会相对容易的碰到更多的问题,如果有一个成熟的框架供给我们使用的话,可以帮助我们避免 ...
- .NET平台开源项目速览(20)Newlife.Core中简单灵活的配置文件
记得5年前开始拼命翻读X组件的源码,特别是XCode,但对Newlife.Core 的东西了解很少,最多只是会用用,而且用到的只是九牛一毛.里面好用的东西太多了. 最近一年时间,零零散散又学了很多,也 ...
- Centos下快速安装Nginx
1.准备工作 选首先安装这几个软件:GCC,PCRE(Perl Compatible Regular Expression),zlib,OpenSSL. Nginx是C写的,需要用GCC编译:Ngin ...
- DLL文件修复
当你在Windows计算机中安装非操作系统的软件时,往往会覆盖或改写系统共享文件, 如动态链接库(.dll文件)和可执行文件(.exe文件). * 对于Windows系统来说,当用户操作不当(如非正常 ...
- UVa 11988破损的键盘
这题是很好的学习用数组实现链表的例子. 原题链接 UVa11988 题意 输入一段文本,字符'['表示Home键,']'表示End键.输出屏幕上面的结果. 思路 难点在于在字符串的头和尾插入字符,如果 ...
- jstree树形菜单
final 用于声明属性.方法和类,分别表示属性不可变,方法不可重写,类不可继承.其实可以参考用easyui的tree 和 ztree参考: https://www.jstree.com/demo/ ...
- 关于本地化(localization)
关于本地化(localization) 我们都知道,如果不需要做国际化版本的App.我们只需要在info.plist 里修改CFBundleDisplayName就可以了,其实做国际化也就是在不同的国 ...