Spark开发环境搭建和作业提交
Spark高可用集群搭建
- 在所有节点上下载或上传spark文件,解压缩安装,建立软连接
- 配置所有节点spark安装目录下的spark-evn.sh文件
- 配置slaves
- 配置spark-default.conf
- 配置所有节点的环境变量
spark-evn.sh
[root@node01 conf]# mv spark-env.sh.template spark-env.sh
[root@node01 conf]# vi spark-env.sh加入
export JAVA_HOME=/usr/local/jdk
#export SCALA_HOME=/software/scala-2.11.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#Spark历史服务分配的内存尺寸
#export SPARK_DAEMON_MEMORY=512m
#下面的这一项就是Spark的高可用配置,如果是配置master的高可用,master就必须有;如果是slave的高可用,slave就必须有;但是建议都配置。
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark" #当启用了Spark的高可用之后,下面的这一项应该被注释掉(即不能再被启用,后面通过提交应用时使用--master参数指定高可用集群节点)
#export SPARK_MASTER_IP=master01
#export SPARK_WORKER_MEMORY=1500m
#export SPARK_EXECUTOR_MEMORY=100m-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。就是说用zookeeper做了spark的HA配置,Master(Active)挂掉的话,Master(standby)要想变成Master(Active)的话,Master(Standby)就要像zookeeper读取整个集群状态信息,然后进行恢复所有Worker和Driver的状态信息,和所有的Application状态信息;
-Dspark.deploy.zookeeper.url=potter2:2181,potter3:2181,potter4:2181,potter5:2181#将所有配置了zookeeper,并且在这台机器上有可能做master(Active)的机器都配置进来;(我用了4台,就配置了4台)
-Dspark.deploy.zookeeper.dir=/spark
-Dspark.deploy.zookeeper.dir是保存spark的元数据,保存了spark的作业运行状态;
zookeeper会保存spark集群的所有的状态信息,包括所有的Workers信息,所有的Applactions信息,所有的Driver信息,如果集群slaves
[root@node03 conf]# mv slaves.template slaves
[root@node03 conf]# vi slaves将localhost删掉,三个节点都加进去
node01
node02
node03配置环境变量
vi /etc/profile
添加
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile
配置spark-default.conf
spark默认本地模式
修改下面一项:
spark.master spark://node01:7077,node02:7077,node03:7077以上工作是在所有节点都要进行的
启动
zookeeper启动
hadoop启动
在一个节点上
/usr/local/spark/sbin/start-all.sh
在另外两个节点上单独启动master,实现高可用
/usr/local/spark/sbin/start-master.sh
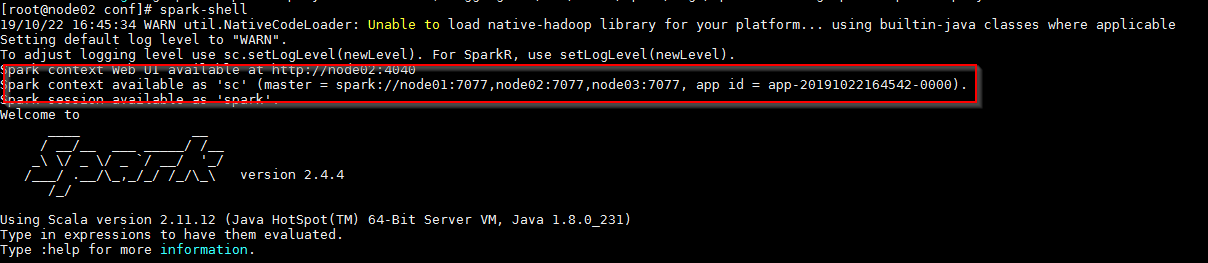
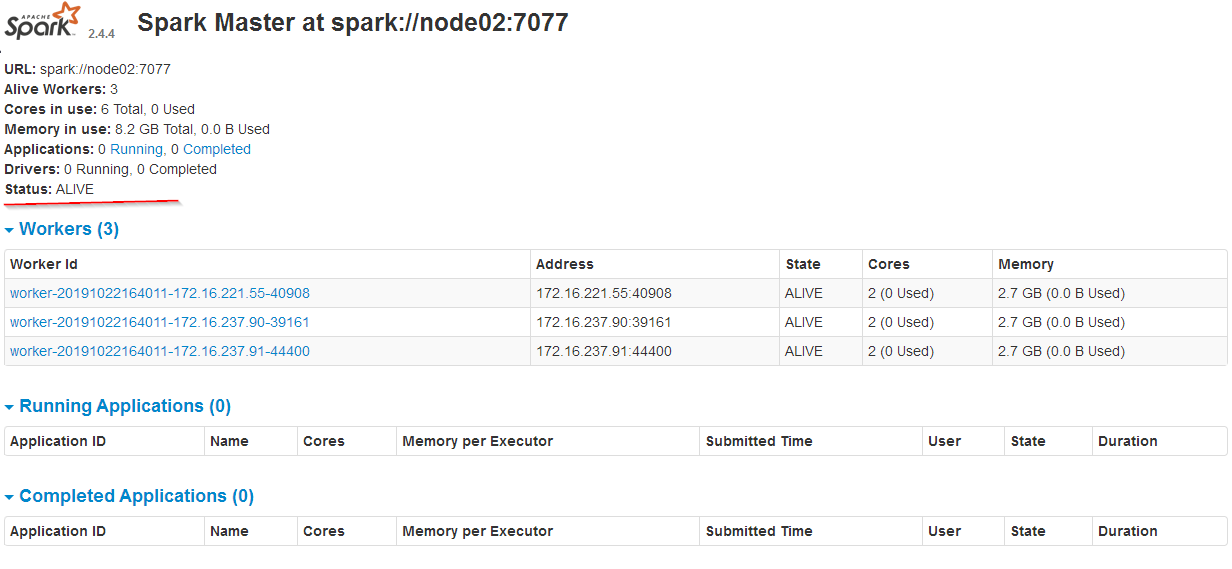
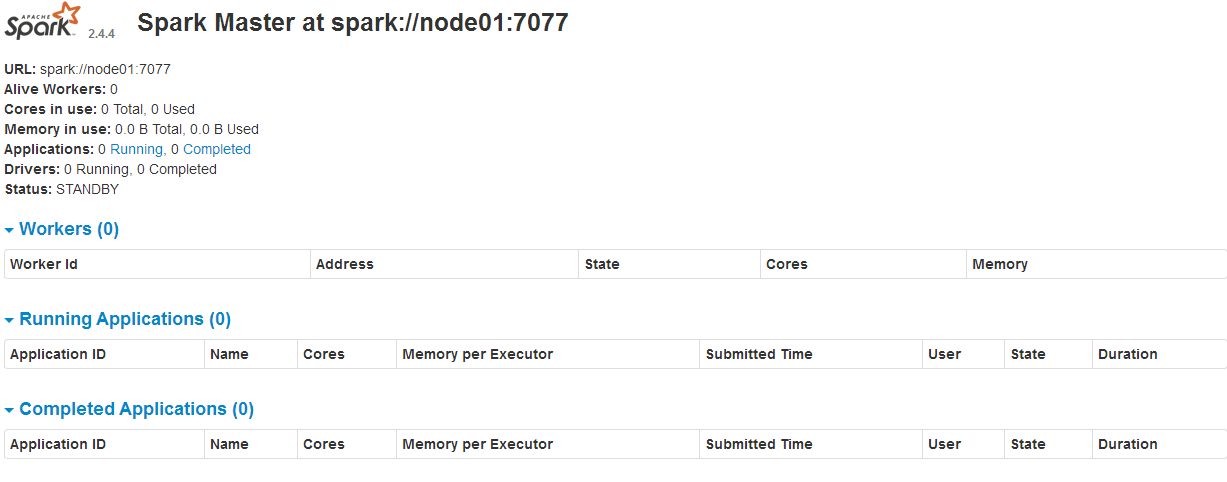
spark-shell命令可以启动shell
web界面
node01:8080
node02:8080
node03:8080
node03是active的,其他standby

本次实验要求
- JDK安装配置:1.8以上版本
- Scala安装配置:Scala 2.11
- Intellij IDEA:下载最新版本
参考链接:
Spark 开发环境|Spark开发指南 https://taoistwar.gitbooks.io/spark-developer-guide/spark_base/spark_dev_environment.html
IDEA中使用Maven开发Spark应用程序 https://blog.csdn.net/yu0_zhang0/article/details/80112846
使用IntelliJ IDEA配置Spark应用开发环境及源码阅读环境 https://blog.tomgou.xyz/shi-yong-intellij-ideapei-zhi-sparkying-yong-kai-fa-huan-jing-ji-yuan-ma-yue-du-huan-jing.html
IDEA导入一个已有的项目:
欢迎界面有Import Project,如果在项目中使用下面步骤,
1.File----->Close Project.
2.在欢迎界面点击Import Project.
Spark-shell的使用
本地运行,bin目录下
./spark-shell
一、企业开发Spark作业方式
1.Spark开发测试
- IDEA通过Spark Local模式开发(不能远程提交到集群)
- Spark Shell交互式分析(可以远程连接集群)
2.Spark生产环境运行
- 打成assembly jar
- 使用bin/spark-submit.sh提交
二、通过已有项目搭建Spark开发环境
1.配置JDK,Scala,IDEA
1)下载JDK
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

选择自己需要的版本下载
2)下载Scala
https://www.scala-lang.org/download/2.11.12.html

选择自己需要的版本下载
3)下载IDEA
IDEA选择最新版本下载即可
4)安装IDEA插件
IDEA搜索安装Scala插件、Maven Integration插件
File--->Settings--->搜索框输入Plugins搜索
2.在工程模板基础上修改
打开已经创建好的工程模板,在IDEA中直接创建见下一小节(三、通过IDEA直接创建)。
更新相应的pom.xml依赖 设置自动导入Maven依赖 https://blog.csdn.net/Gnd15732625435/article/details/81062381
开发
三、通过IDEA直接创建
1.DEA创建一个新的maven项目
File--->New--->Project--->Maven
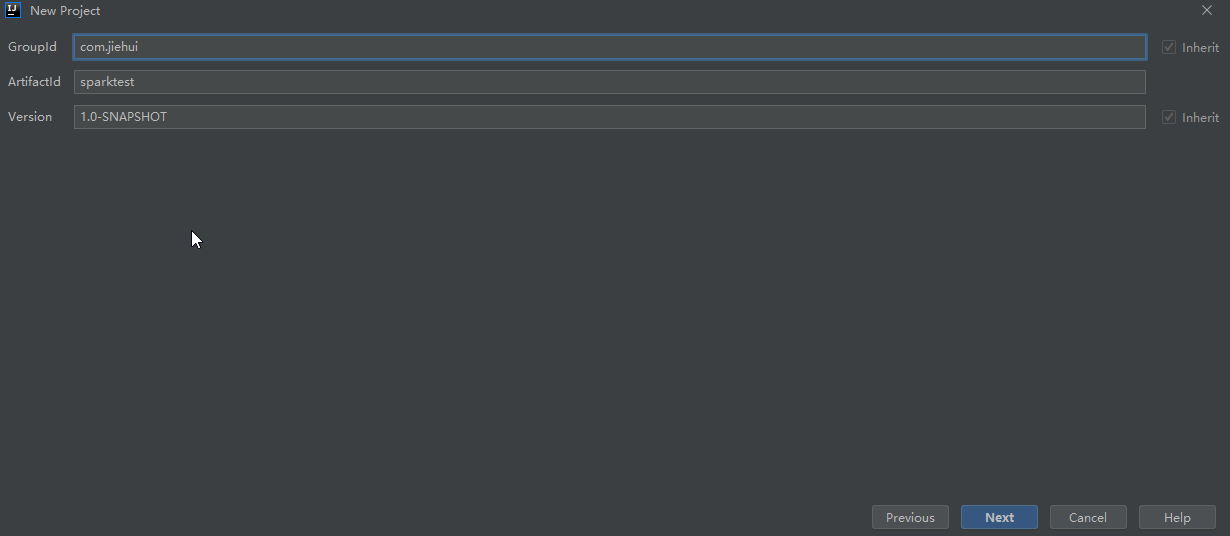
2.填充和修改依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.jiehui</groupId>
<artifactId>sparktest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.4.0</spark.version>
<fastjson.version>1.2.14</fastjson.version>
<scala.version>2.11.8</scala.version>
<java.version>1.8</java.version>
</properties> <repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scalap</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin> <plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<recompileMode>incremental</recompileMode>
<useZincServer>true</useZincServer>
<args>
<arg>-unchecked</arg>
<arg>-deprecation</arg>
<arg>-feature</arg>
</args>
<jvmArgs>
<jvmArg>-Xms1024m</jvmArg>
<jvmArg>-Xmx1024m</jvmArg>
</jvmArgs>
<javacArgs>
<javacArg>-source</javacArg>
<javacArg>${java.version}</javacArg>
<javacArg>-target</javacArg>
<javacArg>${java.version}</javacArg>
<javacArg>-Xlint:all,-serial,-path</javacArg>
</javacArgs>
</configuration>
</plugin> </plugins>
</build>
</project>
注意scala版本,maven中的版本要和IDEA中设置的版本相一致,如果不一致,编译会报错
比如,maven中设置了2.11.8
IDEA中File--->Project Structure--->Libraries,点+按钮,出现如下的Scala版本,系统安装的是2.12.8,但我们应选择最下面的2.11.8

3.编写spark程序
在src目录下创建scala文件夹,创建com.jiehui.test包
编写Spark测试程序
package com.jiehui.test
import org.apache.spark._
object SparkTest {
def main(args: Array[String]): Unit = {
val master = if (args.length > 0) args(0).toString else "local"
val conf = new SparkConf().setMaster(master).setAppName("test")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Seq(1,2,3)).foreach(println(_))
}
}
4.运行
四、作业提交
1.集群配置
因为使用Yarn,因此需要安装好Hadoop,Hadoop需要安装zookeeper,由于工程使用Maven构建,还需要安装Maven。
本实验相关配置:
Zookeeper:3.4.10
Hadoop:2.8.4
Maven:3.6.1
Yarn和Maven的环境变量已经配置好
下载spark二进制包 http://spark.apache.org/downloads.html
选择相应版本,点击3进入下载地址
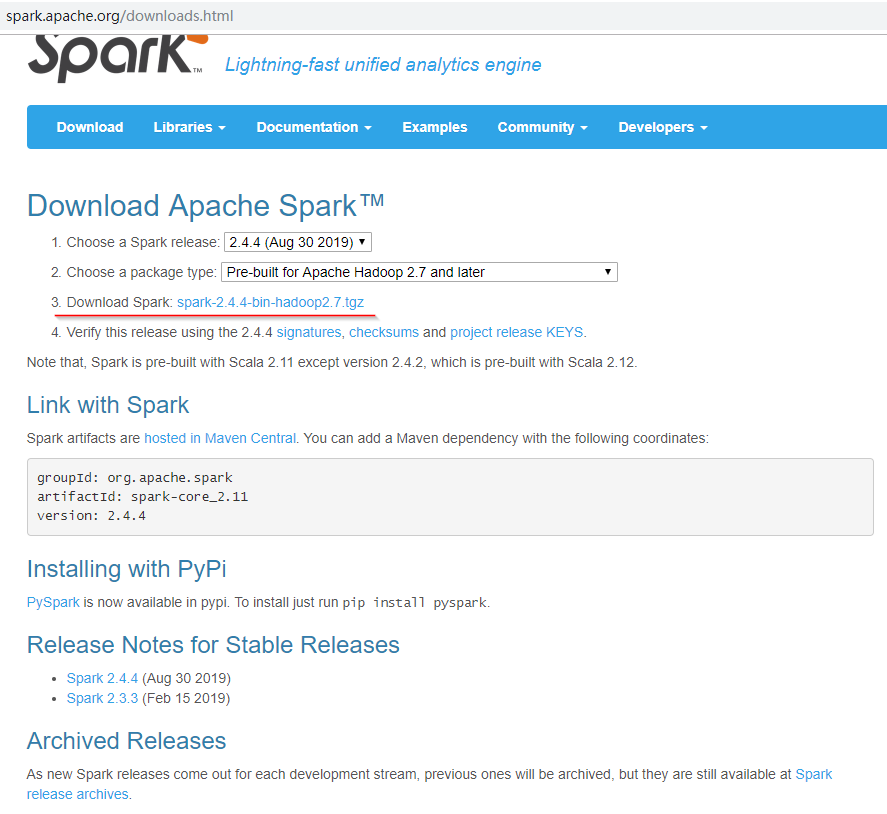
复制镜像链接,在服务器中下载并解压
[root@node01 bigdata]# wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
[root@node01 bigdata]# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
2.作业上传并打包
文件比较小可以直接上传到服务器,文件大打包一下
进入项目目录,用maven打包
[root@node01 project]# cd sparktest/
[root@node01 sparktest]#mvn package
打包好后,target目录下有打好的jar包
[root@node01 sparktest]# ll target
总用量
drwxr-xr-x. root root 9月 : archive-tmp
drwxr-xr-x. root root 9月 : classes
drwxr-xr-x. root root 9月 : generated-sources
drwxr-xr-x. root root 9月 : maven-archiver
drwxr-xr-x. root root 9月 : maven-status
-rw-r--r--. root root 9月 : sparktest-1.0-SNAPSHOT.jar
-rw-r--r--. root root 9月 : sparktest-1.0-SNAPSHOT-jar-with-dependencies.jar
3.执行作业
进入spark的bin目录
[root@node01 bigdata]# cd spark-2.2.-bin-hadoop2.
[root@node01 spark-2.2.-bin-hadoop2.]# cd bin [root@node01 bin]# ll
总用量
-rwxr-xr-x. hadoop hadoop 7月 beeline
-rw-r--r--. hadoop hadoop 7月 beeline.cmd
-rw-r--r--. root root 6月 : derby.log
-rwxr-xr-x. hadoop hadoop 7月 find-spark-home
-rw-r--r--. hadoop hadoop 7月 load-spark-env.cmd
-rw-r--r--. hadoop hadoop 7月 load-spark-env.sh
drwxr-xr-x. root root 6月 : metastore_db
-rwxr-xr-x. hadoop hadoop 7月 pyspark
-rw-r--r--. hadoop hadoop 7月 pyspark2.cmd
-rw-r--r--. hadoop hadoop 7月 pyspark.cmd
-rwxr-xr-x. hadoop hadoop 7月 run-example
-rw-r--r--. hadoop hadoop 7月 run-example.cmd
-rwxr-xr-x. hadoop hadoop 7月 spark-class
-rw-r--r--. hadoop hadoop 7月 spark-class2.cmd
-rw-r--r--. hadoop hadoop 7月 spark-class.cmd
-rwxr-xr-x. hadoop hadoop 7月 sparkR
-rw-r--r--. hadoop hadoop 7月 sparkR2.cmd
-rw-r--r--. hadoop hadoop 7月 sparkR.cmd
-rwxr-xr-x. hadoop hadoop 7月 spark-shell
-rw-r--r--. hadoop hadoop 7月 spark-shell2.cmd
-rw-r--r--. hadoop hadoop 7月 spark-shell.cmd
-rwxr-xr-x. hadoop hadoop 7月 spark-sql
-rwxr-xr-x. hadoop hadoop 7月 spark-submit
-rw-r--r--. hadoop hadoop 7月 spark-submit2.cmd
-rw-r--r--. hadoop hadoop 7月 spark-submit.cmd
[root@node01 bin]# cd ..
[root@node01 spark-2.2.0-bin-hadoop2.7]# ./bin/spark-submit --class com.jiehui.test.SpakTest --master yarn --deploy-mode cluster /root/project/sparktest/target/sparktest-1.0-SNAPSHOT-jar-with-dependencies.jar yarn
使用sprk-submit提交作业
| 执行的类 | --class com.jiehui.test.SparkTest |
| 使用yarn |
--master yarn |
| 部署方式是集群 | --deploy-mode cluster |
| jar包的路径 | /root/project/sparktest/target/sparktest-1.0-SNAPSHOT-jar-with-dependencies.jar |
| 参数 |
yarn是参数 |
提交作业的namenode状态必须是active的,如果是standby就会报错:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyExceptio
- 查看namenode状态
hdfs haadmin -getServiceState nn1
- 激活namenode
hdfs haadmin -transitionToActive --forcemanual nn1
我们在命令中输入的是com.jiehui.test.SpakTest,由于我们输错了类的名字,因此程序不能正常运行
报错 Container exited with a non-zero exit code 10
client token: N/A
diagnostics: Application application_1567500736308_0001 failed times due to AM Container for appattempt_1567500736308_0001_000002 exited w
Failing this attempt.Diagnostics: Exception from container-launch.
Container id: container_1567500736308_0001_02_000001
Exit code:
Stack trace: ExitCodeException exitCode=:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:)
at org.apache.hadoop.util.Shell.run(Shell.java:)
... Container exited with a non-zero exit code
For more detailed output, check the application tracking page: http://node01:8088/cluster/app/application_1567500736308_0001 Then click on links to l
. Failing the application.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: default
start time:
final status: FAILED
tracking URL: http://node01:8088/cluster/app/application_1567500736308_0001
user: root
Exception in thread "main" org.apache.spark.SparkException: Application application_1567500736308_0001 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:)
at org.apache.spark.deploy.yarn.Client$.main(Client.scala:)
...// :: INFO util.ShutdownHookManager: Shutdown hook called
// :: INFO util.ShutdownHookManager: Deleting directory /tmp/spark--7dc4-4bc3--dbb3335025f8
通过上面的说明无法判断错误出在哪里,必须使用yarn命令查看作业日志
通过查看日志发现错误:
// :: ERROR yarn.ApplicationMaster: Uncaught exception:
java.lang.ClassNotFoundException: com.jiehui.test.SpakTest
找不到我们指定的类,经过观察发现名字出错,改正命令
./bin/spark-submit --class com.jiehui.test.SparkTest --master yarn --deploy-mode cluster /root/project/sparktest/target/sparktest-1.0-SNAPSHOT-jar-with-dependencies.jar yarn
程序成功运行,运行成功截图如下:
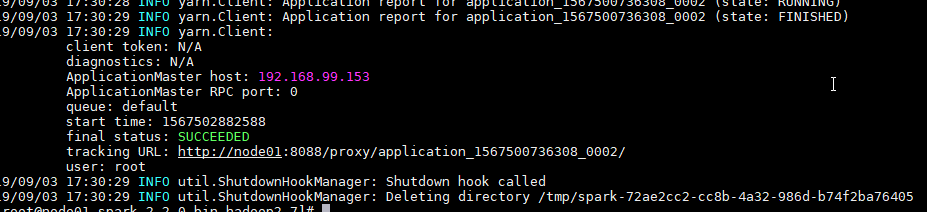
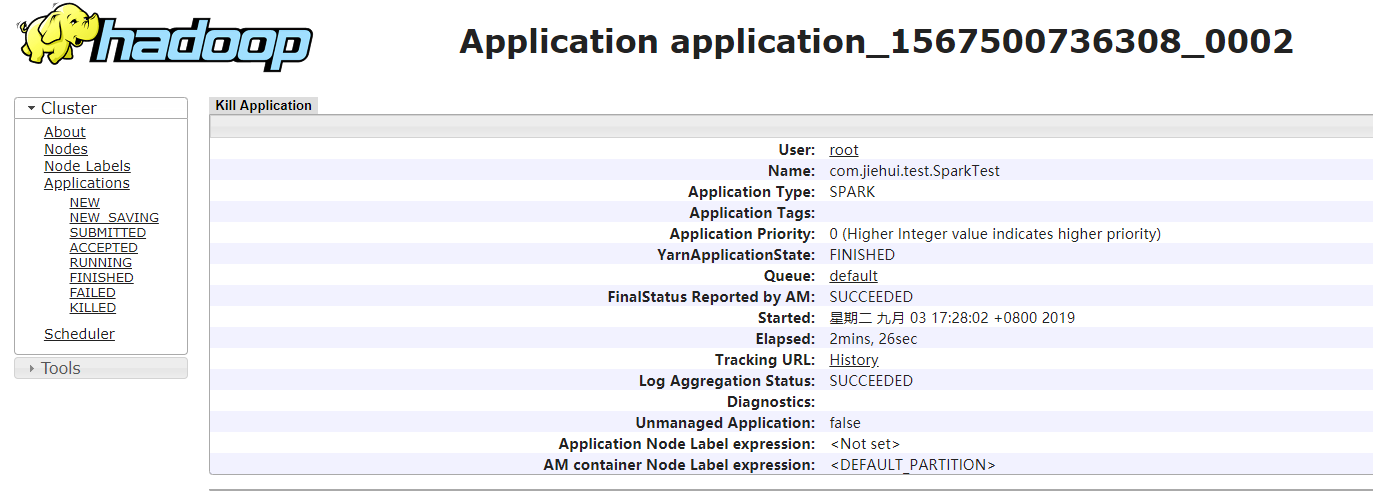
我们的Spark环境搭建成功了。
Spark开发环境搭建和作业提交的更多相关文章
- Spark 开发环境搭建
原文见 http://xiguada.org/spark-develop/ 本文基于Spark 0.9.0,由于它基于Scala 2.10,因此必须安装Scala 2.10,否则将无法运行Spar ...
- Spark编译及spark开发环境搭建
最近需要将生产环境的spark1.3版本升级到spark1.6(尽管spark2.0已经发布一段时间了,稳定可靠起见,还是选择了spark1.6),同时需要基于spark开发一些中间件,因此需要搭建一 ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- HBase、Hive、MapReduce、Hadoop、Spark 开发环境搭建后的一些步骤(export导出jar包方式 或 Ant 方式)
步骤一 若是,不会HBase开发环境搭建的博文们,见我下面的这篇博客. HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 步骤一里的,需要补充的.如下: 在项目名,右键, ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
- Spark 系列(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- Spark开发环境搭建(IDEA、Scala、SVN、SBT)
软件版本 软件信息 软件名称 版本 下载地址 备注 Java 1.8 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-dow ...
随机推荐
- centos 6.5 查看 IP
ip 和 ifconfig 两个命令都可以,但现在推荐使用 ip ip addr ifconfig
- Web核心之最简单最简单最简单的登录页面
需求分析: 在登录页面提交用户名和密码 在Servlet中接收提交的参数,封装为User对象,然后调用DAO中的方法进行登录验证 在DAO中进行数据库查询操作,根据参数判断是否有对象的用户存在 在Se ...
- cocos2D-X 线程注意事项
{ 在子线程种是无法创建纹理的,也就是精灵 }
- Appium环境搭建(Appium库的安装)
Appium环境搭建 谷歌驱动和对照:注意:64位向下兼容,直接下载32位的就可以啦,亲测可用. https://blog.csdn.net/allthewayforward/article/deta ...
- Linux基础优化(二)
Linux基础优化(二) 一操作系统字符优化 避免出现中文乱码,UTF-8支持中文GBK-Xx支持中文 (一)查看默认编码 [root@centos7 ~]# echo $LANG en_US.UTF ...
- Maven开始
1:加入Maven插件: 这句话的意思是: 从本地仓库找到相应的jar包 <localRepository>F:\RepMaven</localRepository 2:创建一个Ma ...
- java 标准输入输出流,打印流,数据流
1 package stream; import static org.junit.Assert.assertNotNull; import java.io.BufferedReader; impor ...
- C#操作xml完整类文件
C#操作xml完整类文件 xml_oper.cs using ...System; using System.Data; using System.Web; using System.Xml; /** ...
- Laex/Delphi-OpenCV
https://github.com/Laex/Delphi-OpenCV 66 Star119 Fork75 Laex/Delphi-OpenCV CodeIssues 3Pull requests ...
- javascript标签放置位置
首先:放置位置哪里都能放 但是js代码很有可能不起作用:例如:往id为span的标签中定时插入数字 var time=document.getElementById("span") ...