聚类(一)——Kmeans
Clustering
聚类K-means
聚类是机器学习和数据挖掘领域的主要研究方向之一,它是一种无监督学习算法,小编研究生时期的主要研究方向是“数据流自适应聚类算法”,所以对聚类算法有比较深刻的理解,于是决定开一个专题来写聚类算法,希望可以为入门及研究聚类相关算法的读者带来帮助。聚类可以作为一个单独的任务,用于寻找数据内在分布结构,也经常作为其他学习任务的前驱过程,应用十分广泛。今天,小编就带你探索聚类算法的奥秘,并介绍第一个聚类算法Kmeans。
Q:什么是聚类?
A:聚类是按照某一种特定的标准(相似性度量,如欧式距离等),把一个数据集分割成不同的类,使得同一个类中的数据对象的相似性尽可能大,不同类之间的差异性也尽可能大,如下图是一个聚类结果的可视化:
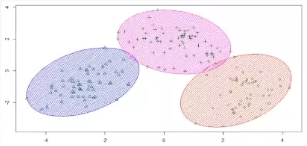
聚类有非常广泛的应用,比如根据消费记录发现不同的客户群,对基因表达进行聚类可以研究不同种群中的基因特征,对文本进行聚类可以快速找出相关主题的文章等。
Q:如何度量相似性?
A:常用的相似性度量方式主要有以下几种:
欧式距离:
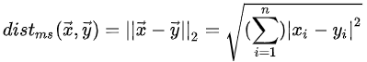
Minkowoski距离:
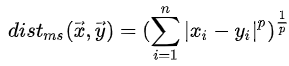
曼哈顿距离:
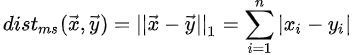
余弦距离:
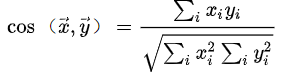
Jaccard相似系数:
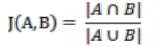
相关系数:
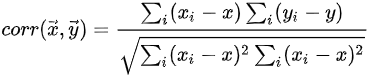
Q:常用的聚类算法有哪些?
A:
基于划分的聚类:k-means,mean shift
层次聚类:BIRCH
密度聚类:DBSCAN
基于模型的聚类:GMM
Affinity propagation
谱聚类
上面的这些算法只是简单的引入聚类的概念,在接下来的专题中,我们将具体探讨经典的聚类算法,研究它们的原理,分析优缺点,应用场景等。今天,我们就来学习最经典的一个聚类算法Kmeans
K-means
Kmeans聚类原理
Kmeans算法的思想很简单,根据给定样本集中样本间距离的大小将样本集划分为k个簇(类),使得每个点都属于距离它最近的那个聚类中心(即均值means)对应的类。之所以叫kmenas是因为它可以发现k(用户指定)个簇且簇中心用属于该簇的数据的均值来表示。
Kmeans聚类算法
数据集合X={x1,...xn}中每个样本都是d维无标签数据,kmeans聚类的目标是将这n个点分到k个簇使得簇内点到簇中心点(均值)的距离平方和最小,即求下列目标函数的最优解
其中μi就是簇Si中点的均值。
然而解上式并不是一个简单的问题,因为它是一个NP难问题,所以kmeans算法采用一种启发式的迭代求解方法:
首先随机选择k个对象作为初始的聚类中心,然后计算每个样本到各个聚类中心的距离,并分配给距离它最近的聚类中心。一旦对象全都被分配了,重新计算每个簇的中心(均值)作为下一次迭代的新的中心点。这一过程将重复进行直到满足下列任一条件:
没有对象被重新分配给新的类;
聚类中心不再发生变化;
误差平方和局部最小。
Tips:
k值的选择:一般来说我们可以根据数据的先验选择一个合适的k,如果不行,则可以通过交叉验证选择合适的k;
初始化k个中心点:可以随机选择,也可以每次选择距离其他中心点尽可能远的点作为中心;
Kmeans++算法
前面我们也提到了K个初始化中心的选择对聚类算法的运行结果和时间有很大影响,Kmeans++算法提出了对随机化初始化聚类中心的优化:
从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1;
对于数据集中的每一个点xi,计算它与已选择的聚类中心最近的一个的距离D(xi);
选择D(xi)较大的点作为新的聚类中心;
重复b,c直到找出k个聚类中心;
Kmeans算法小结
优点:
原理简单,实现简单,收敛速度快;
聚类效果比较好;
可解释性强,直观;
只有一个参数k;
缺点:
k的选择对聚类效果影响较大;
对于不是凸的数据集比较难收敛;
类别不均衡数据集聚类效果不好;
结果局部最优;
对噪声点敏感;
聚类结果是球形。
小结:
今天是聚类算法学习的第一部分,内容虽然简单但是很重要,kmeans算法常常作为其他算法的基础,如之前的半监督学习以及之后会讲的谱聚类算法都会用到。相信今天的学习你一定也有了收获,聚类专题的下一篇内容是谱聚类,敬请期待!

扫码关注
获取有趣的算法知识


聚类(一)——Kmeans的更多相关文章
- [聚类算法] K-means 算法
聚类 和 k-means简单概括. 聚类是一种 无监督学习 问题,它的目标就是基于 相似度 将相似的子集聚合在一起. k-means算法是聚类分析中使用最广泛的算法之一.它把n个对象根据它们的属性分为 ...
- 机器学习(二)——K-均值聚类(K-means)算法
最近在看<机器学习实战>这本书,因为自己本身很想深入的了解机器学习算法,加之想学python,就在朋友的推荐之下选择了这本书进行学习,在写这篇文章之前对FCM有过一定的了解,所以对K均值算 ...
- R与数据分析旧笔记(十四) 动态聚类:K-means
动态聚类:K-means方法 动态聚类:K-means方法 算法 选择K个点作为初始质心 将每个点指派到最近的质心,形成K个簇(聚类) 重新计算每个簇的质心 重复2-3直至质心不发生变化 kmeans ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- K-均值聚类(K-means)算法
https://www.cnblogs.com/ybjourney/p/4714870.html 最近在看<机器学习实战>这本书,因为自己本身很想深入的了解机器学习算法,加之想学pytho ...
- 【数据挖掘】聚类之k-means(转载)
[数据挖掘]聚类之k-means 1.算法简述 分类是指分类器(classifier)根据已标注类别的训练集,通过训练可以对未知类别的样本进行分类.分类被称为监督学习(supervised learn ...
- ML.NET技术研究系列-2聚类算法KMeans
上一篇博文我们介绍了ML.NET 的入门: ML.NET技术研究系列1-入门篇 本文我们继续,研究分享一下聚类算法k-means. 一.k-means算法简介 k-means算法是一种聚类算法,所谓聚 ...
- 【机器学习】聚类算法:层次聚类、K-means聚类
聚类算法实践(一)--层次聚类.K-means聚类 摘要: 所谓聚类,就是将相似的事物聚集在一 起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段.比如古典生物学之中,人们通 ...
- 【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了.短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数 ...
- 机器学习——详解经典聚类算法Kmeans
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第12篇文章,我们一起来看下Kmeans聚类算法. 在上一篇文章当中我们讨论了KNN算法,KNN算法非常形象,通过距离公 ...
随机推荐
- 使用XAMPP配置Apache服务器反向代理
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时 ...
- 如何将腾讯视频的qlv格式转换为mp4格式
基本上每个视频app都会有自己固有的视频播放格式,比如优酷的KUX.爱奇艺的QSV和腾讯的QLV等.而今天我们重点介绍腾讯的QLV格式如何转换为MP4格式,小便也是经过多次的摸索多次的软件试用,发现的 ...
- 【HIVE】各种时间格式处理
yyyy-MM-dd与yyyyMMdd000000转换的三种方法 方法一:date_format(只支持yyyy-MM-dd -> yyyyMMdd000000) select date_for ...
- Android_布局
<该文章参考各大博客以及书籍总结而来,如有问题欢迎指出^ ^> 一.五大传统布局+新布局 线性布局——LinearLayout 相对布局——RelativeLayout 帧布局——Fram ...
- 常用注解@Controller、@Service、@Autowired
@Controller.@Service在spring-context-5.1.10.RELEASE.jar包下,所在包如下 @Autowired在spring-beans-5.1.10.RELEAS ...
- 网页布局——table布局
table 的特性决定了它非常适合用来做布局,并且表格中的内容可以自动居中,这是之前用的特别多的一种布局方式 而且也加入了 display:table;dispaly:table-cell 来支持 t ...
- SVN部署(基于Linux)
第一步:通过yum命令安装svnserve,命令如下: yum -y install subversion 此命令会全自动安装svn服务器相关服务和依赖,安装完成会自动停止命令运行 若需查看svn安装 ...
- oracle数据库的安全测试
Oracle Database,又名Oracle RDBMS,或简称Oracle.是甲骨文公司的一款关系数据库管理系统.它是在数据库领域一直处于领先地位的产品.可以说Oracle数据库系统是目前世界上 ...
- AWD攻防工具脚本汇总(二)
情景五:批量修改ssh密码 拿到官方靶机第一件事改自己机器的ssh密码,当然也可以改别人的密码~ import paramiko import sys ssh_clients = [] timeout ...
- Circle Problem From 3Blue1Brown (分圆问题)
Background\text{Background}Background Last night, lots of students from primary school came to our c ...