决策树(基于增益率)之python实现
如图,为使用到的公式,信息熵表明样本的混乱程度,增益表示熵减少了,即样本开始分类,增益率是为了平衡增益准则对可取值较多的属性的偏好,同时增益率带来了对可取值偏小的属性的偏好,实际中,先用增益进行筛选,选取大于增益平均值的,然后再选取其中增益率最高的。
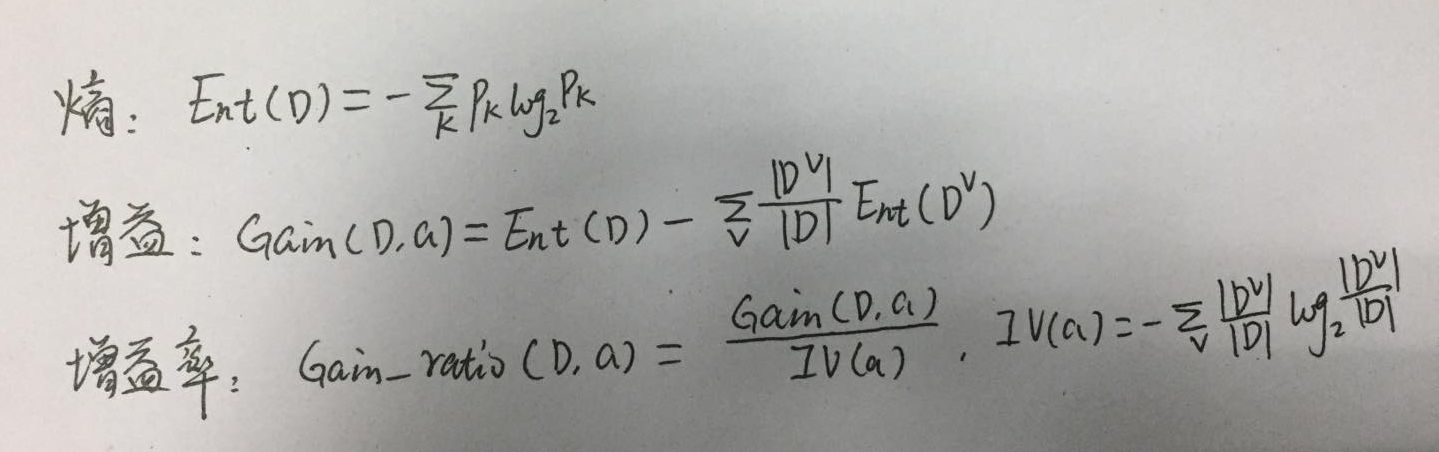
以下代码纯粹手写,未参考其他人代码,如果问题,请不吝赐教。
1,计算信息熵的函数
import numpy as np
# 计算信息熵
# data:like np.array
# data.shape=(num_data,data_features+1) 即属性与label放一起了
def entropy(data,num_class):
class_set=list(set(data[:,-1]))
result=0
length=len(data)
# 这里修改一下,不使用num_class
for i in range(len(class_set)):
l=len(data[data[:,-1]==class_set[i]])
p=l/length
result-=p*np.log2(p)
return result
2,计算增益及属性a的固有值(IV)
# 计算不同属性的信息增益
# detail_features:特征构成的list,每个特征的可取值构成list元素,即也是list
def calculate_gain(data,detail_features,num_class):
'''返回各属性对应的信息增益及平均值'''
result=[]
ent_data=entropy(data,num_class)
for i in range(len(detail_features)):
res=ent_data
for j in range(len(detail_features[i])):
part_data=data[data[:,i]==detail_features[i][j]]
length=len(part_data)
res-=length*entropy(part_data,num_class)/len(data)
result.append(res)
return result,np.array(result).mean()
# 计算某个属性的固有值
def IVa(data,attr_index):
attr_values=list(set(data[:,attr_index]))
v=len(attr_values)
res=0
for i in range(v):
part_data=data[data[:,attr_index]==attr_values[i]]
p=len(part_data)/len(data)
res-=p*np.log2(p)
return res
3,构建节点类,以便构建树
class Node:
def __init__(self,key,childs):
self.childs=[]
self.key=key
def add_node(self,node):
self.childs.append(node)
4,构建树
# 判断数据是否在所有属性的取值都一样,以致无法划分
def same_data(data,attrs):
for i in range(len(attrs)):
if len(set(data[:,i]))>1:
return False
return True # attrs:属性的具体形式
def create_tree(data,attrs,num_class,root):
# 注意这里3个退出条件
# 1,如果数据为空,不能划分,此时这个叶节点不知标记为哪个分类了
if len(data)==0:
return
# 2,如果属性集为空,或所有样本在所有属性的取值相同,无法划分,返回样本最多的类别
if len(attrs)==0 or same_data(data,attrs):
class_set=list(set(data[:,-1]))
max_len=0
index=0
for i in range(len(class_set)):
if len(data[data[:,-1]==class_set[i]])>max_len:
max_len=len(data[data[:,-1]==class_set[i]])
index=i
root.key=root.key+class_set[index]
return
# 3,如果当前节点包含同一类的样本,无需划分
if len(set(data[:,-1]))==1:
root.key=root.key+data[0,-1]
return
ent=entropy(data,num_class)
gain_result,mean=calculate_gain(data,attrs,num_class)
max=0
max_index=-1
# 求增益率最大
for i in range(len(gain_result)):
if gain_result[i]>=mean:
iva=IVa(data,i)
if gain_result[i]/iva>max:
max=gain_result[i]/iva
max_index=i
for j in range(len(attrs[max_index])):
part_data=data[data[:,max_index]==attrs[max_index][j]]
# 删除该列特征
part_data=np.delete(part_data,max_index,axis=1)
# 添加节点
root.add_node(Node(key=attrs[max_index][j],childs=[]))
# 删除某一类已判断属性
new_attrs=attrs[0:max_index]
new_attrs.extend(attrs[max_index+1:])
create_tree(part_data,new_attrs,num_class,root.childs[j])
5,使用西瓜数据集2.0测试,数据这里就手写了,比较少
def createDataSet():
"""
创建测试的数据集
:return:
"""
dataSet = [
#
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
#
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
#
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
#
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
#
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'], # ----------------------------------------------------
#
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
#
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
#
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
#
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
#
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
#
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
#
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
#
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
#
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
] # 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感'] # 特征对应的所有可能的情况
labels_full = [] for i in range(len(labels)):
items=[item[i] for item in dataSet]
uniqueLabel = set(items)
labels_full.append(list(uniqueLabel))
return np.array(dataSet), labels, labels_full
6,开始构建树
dataset,labels,labels_full=createDataSet()
root=Node('',[])
create_tree(dataset, labels_full, 2, root)
7,打印树结构
def print_root(n,root):print(n,root.key)
for node in root.childs:
print_root(n+1,node)
print_root(0,root)
打印结果为:数字表示层次
0
1 模糊坏瓜
1 稍糊
2 硬滑坏瓜
2 软粘好瓜
1 清晰
2 硬滑好瓜
2 软粘
3 青绿
4 稍蜷好瓜
4 蜷缩
4 硬挺坏瓜
3 乌黑坏瓜
3 浅白
8,绘制树形结构,这里我就手动绘制了。图中有2个叶节点为空白,即模型不知道该推测其为好瓜还是坏瓜。这里我暂时没有好的思路解决,只能随机处理?

9,总结
首先,暂时没有添加predict函数。其次,这是个简陋版的实现,有很多待优化的地方,如连续值处理、缺失值处理、剪枝防止过拟合,树的创建使用的是递归(样本大导致栈溢出,改成队列实现较好),也有基于基尼指数的实现,还有多变量决策树(可实现复杂的分类边界)。
决策树(基于增益率)之python实现的更多相关文章
- (数据科学学习手札23)决策树分类原理详解&Python与R实现
作为机器学习中可解释性非常好的一种算法,决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- windows下使用pycharm开发基于ansible api的python程序
Window下python安装ansible,基于ansible api开发python程序 在windows下使用pycharm开发基于ansible api的python程序时,发现ansible ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- 数据结构:二叉树 基于list实现(python版)
基于python的list实现二叉树 #!/usr/bin/env python # -*- coding:utf-8 -*- class BinTreeValueError(ValueError): ...
- 决策树之ID3算法实现(python)
决策树的概念其实不难理解,下面一张图是某女生相亲时用到的决策树: 基本上可以理解为:一堆数据,附带若干属性,每一条记录最后都有一个分类(见或者不见),然后根据每种属性可以进行划分(比如年龄是>3 ...
- 基于微博数据用 Python 打造一颗“心”
一年一度的虐狗节刚过去不久,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“ ...
- 基于协程的Python网络库gevent
import gevent def test1(): print 12 gevent.sleep(0) print 34 def test2(): print 56 gevent.sleep(0) p ...
随机推荐
- python 06 深浅拷贝
目录 1. 小数据池 1.1 代码块 1.2 小数据池 1.3 执行顺序 (代码块--小数据池) 1.4 "=="和 "is" 2. 深浅拷贝 2.1 赋值 2 ...
- jvm系列(四):jvm调优-命令篇
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole.大名鼎鼎的VisualVM,IBM的Memory Analyzer ...
- Linux shell脚本判断服务器网络是否可以上网
Linux shell脚本判断网络畅通 介绍 在编写shell脚本时,有的功能需要确保服务器网络是可以上网才可以往下执行,那么此时就需要有个函数来判断服务器网络状态 我们可以通过curl来访问 www ...
- LeetCode刷题 - (01)两数之和
题目描述 给定一个整数数组nums和一个目标值target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中同样的元 ...
- Codeforces 948D Perfect Security
Perfect Security 题意:给你一个A[i]数组, 再给你一个B[i]数组, 现在用选取 B[i] 数组中的一个 去和 A[i] 数组里的一个元素去进行异或操作, B[i]数组的元素只能用 ...
- lightoj 1044 - Palindrome Partitioning(需要优化的区间dp)
题目链接:http://lightoj.com/volume_showproblem.php?problem=1044 题意:求给出的字符串最少能分成多少串回文串. 一般会想到用区间dp暴力3个for ...
- 数论 线性同余方程的应用 poj2891
Strange Way to Express Integers Time Limit: 1000MS Memory Limit: 131072K Total Submissions: 17321 ...
- 企查猫app数据解密
通过最近几天的对企查猫的研究,目前已经成功将企查猫的数据加密和响应数据加密完成解密. 和之前对启信宝APP的数据解密操作基本一样,不过企查猫对请求和响应都使用aes加密了,抓包的时候可以看到,具体可以 ...
- 降维和PCA
简介 要理解什么是降维,书上给出了一个很好但是有点抽象的例子. 说,看电视的时候屏幕上有成百上千万的像素点,那么其实每个画面都是一个上千万维度的数据:但是我们在观看的时候大脑自动把电视里面的场景放在我 ...
- Docker版本与centos和ubuntu环境下docker安装介绍
# Docker版本与安装介绍 * Docker-CE 和 Docker-EE * Centos 上安装 Docker-CE * Ubuntu 上安装 Docker-CE ## Docker-CE和D ...