win10虚拟机搭建Hadoop集群(已完结)
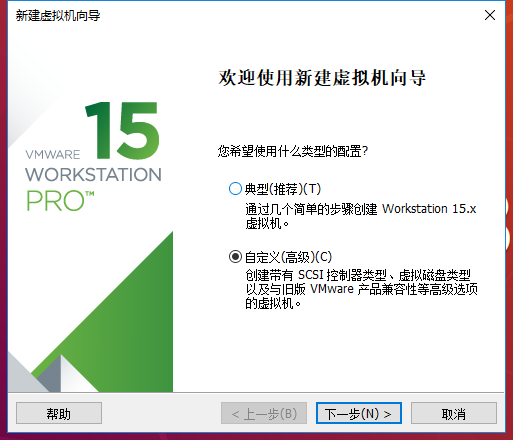
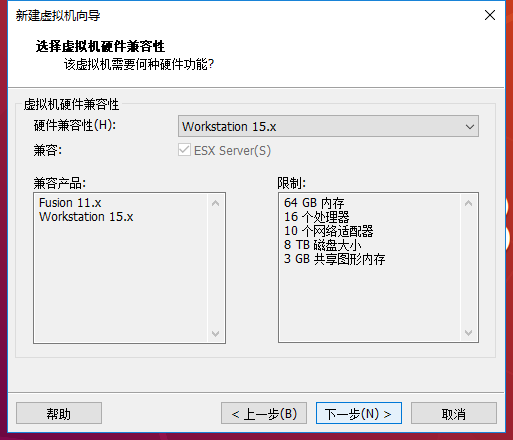
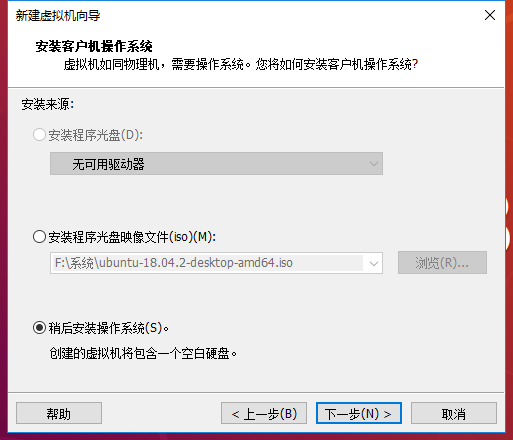
1 在虚拟机安装 Ubuntu

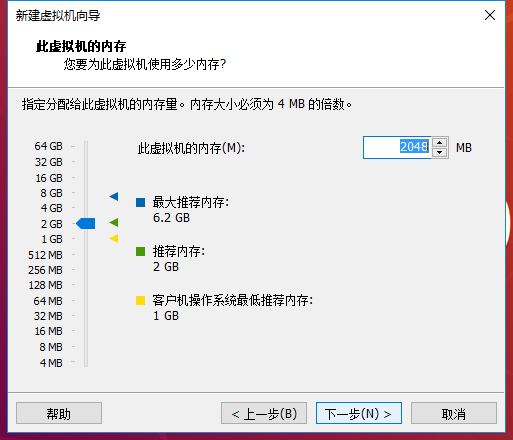
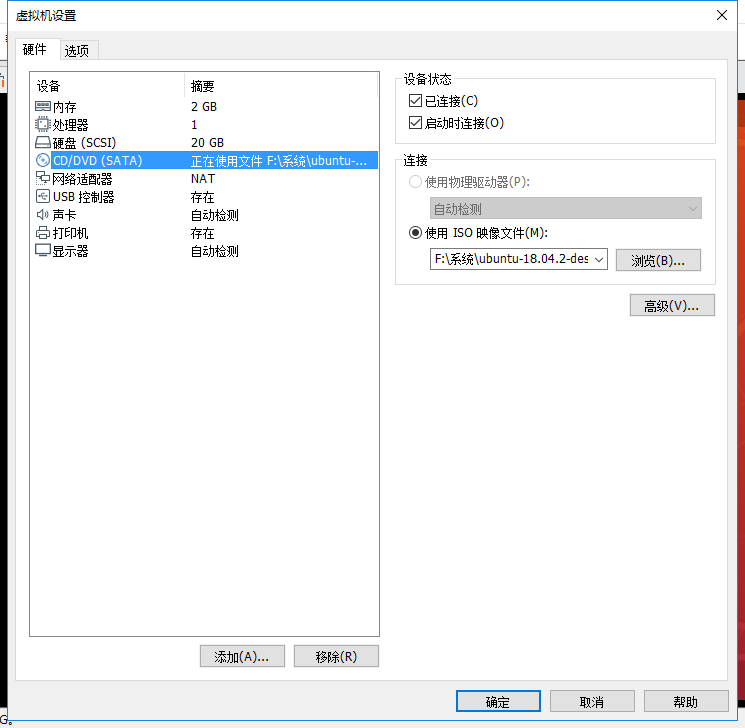
2 安装网络工具
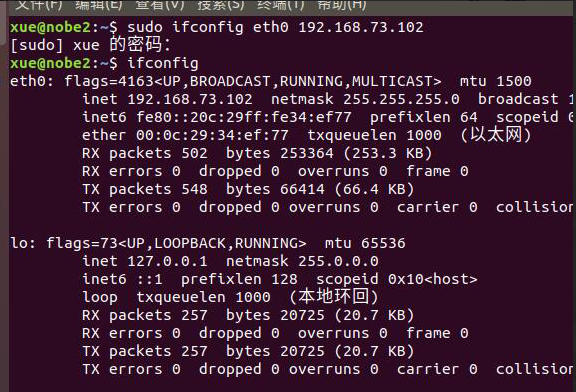
Ubuntu最小化安装没有 ifconfig命令
sudo apt-get install net-tools
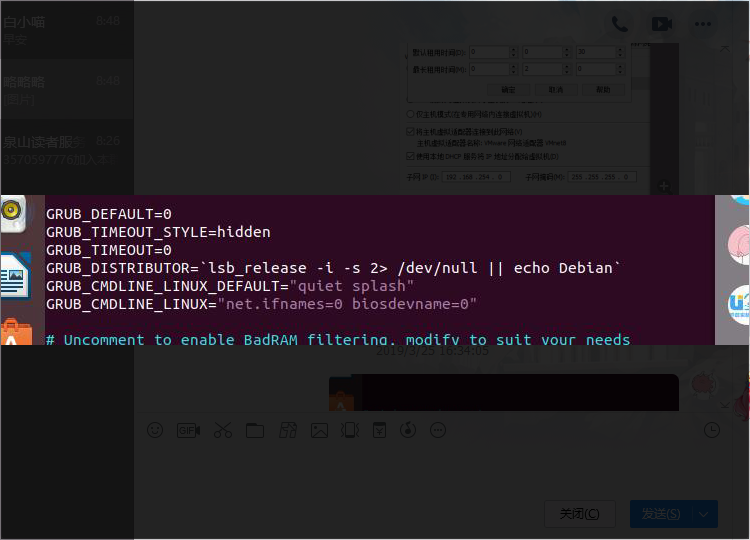
3 Ubuntu修改网卡名字
修改网卡名字为eth0
sudo vim /etc/network/interfaces
reboot
4 修改主机名
sudo vim /etc/hosts
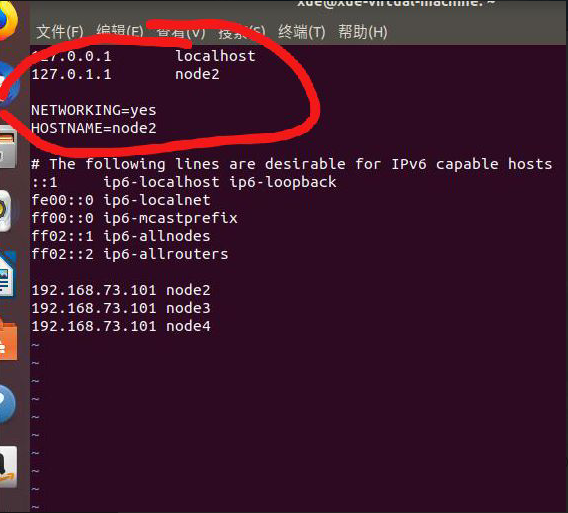
最后还要分别修改 /etc/hostname
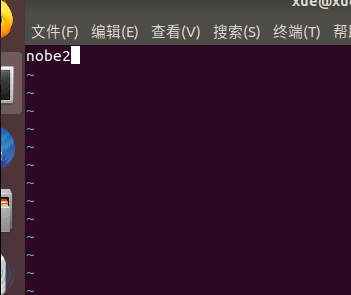
reboot
5 修改IP地址
在虚拟机的虚拟机编辑选项->虚拟网络网络编辑器->nat模式->更改设置->根据自己主机的网络改子网
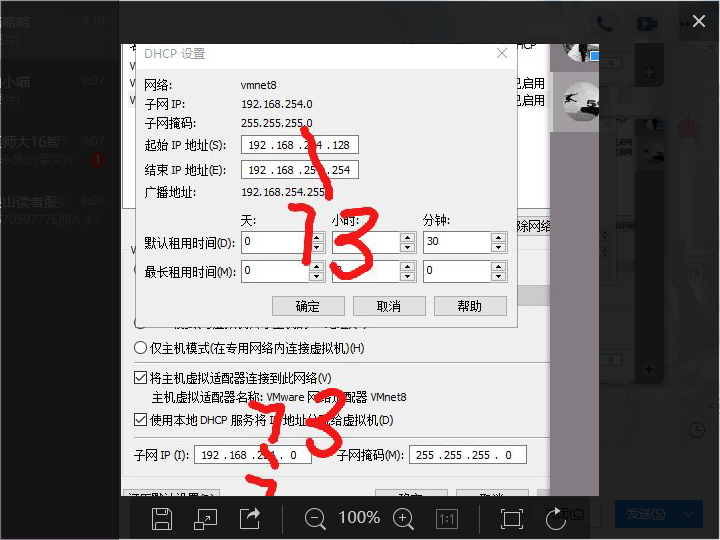
reboot
6 设置 DNS 解析
不需解析
7 修改 hosts 文件
sudo vim /etc/hosts
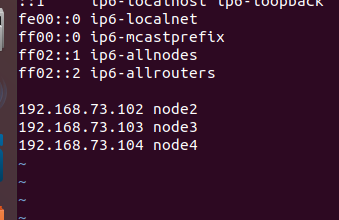
8 将yum源改为阿里云
8.1先备份

8.2打开文件设置
sudo vim /etc/apt/sources.list
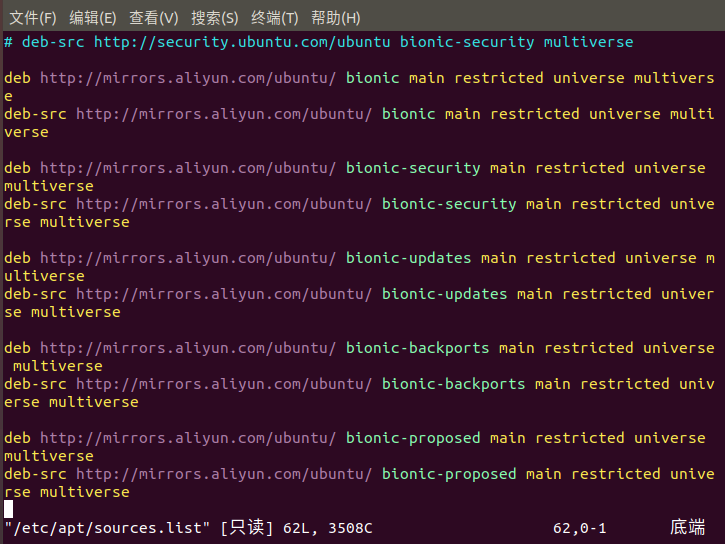
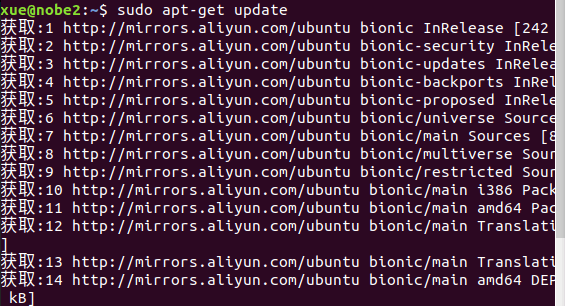
8.3更新
sudo apt-get update
9 安装配置JDK
9.1 检查是否已经安装
下载JDK,将JDK拉到桌面

9.2 安装JDK包到下列文件
alien -ivh --prefix=/usr/apps jdk-8u201-linux-x64.rpm
9.3配置环境变量
sudo vim /etc/profile

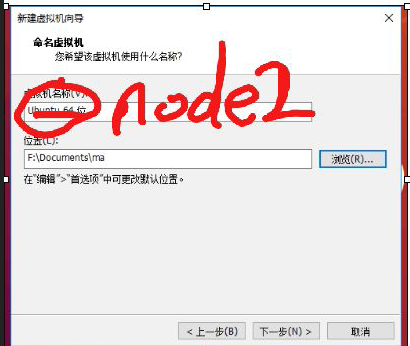
10 克隆节点

如下图克隆出nobe3和nobe4

10.1修改新节点的IP
根据步骤七修改
10.2修改主机名
步骤四
10.3其他节点进行类似操作
11 配置免密登录
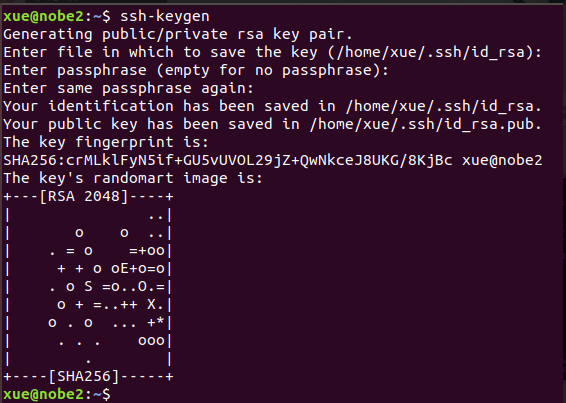
11.1 生成密钥对
ssh-keygen
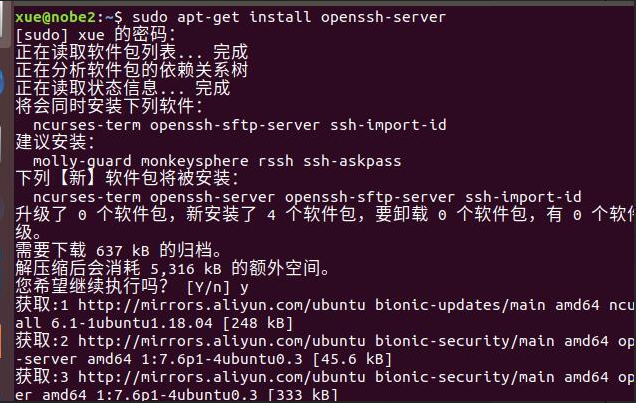
11.2下载openssh-server
sudo apt-get install openssh-server
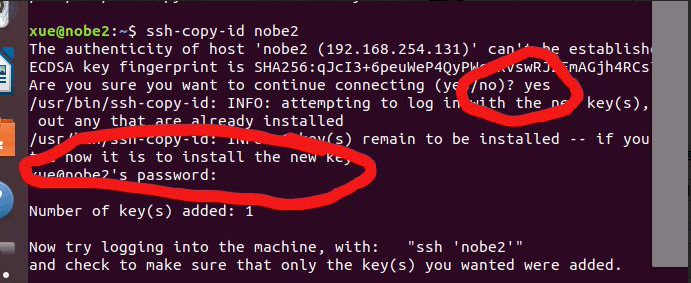
11.3将密钥对配置到node2 node3 和node4
12 添加Hadoop 用户
四个节点同时操作
sudo useradd hadoop
vsudo passwd hadoop
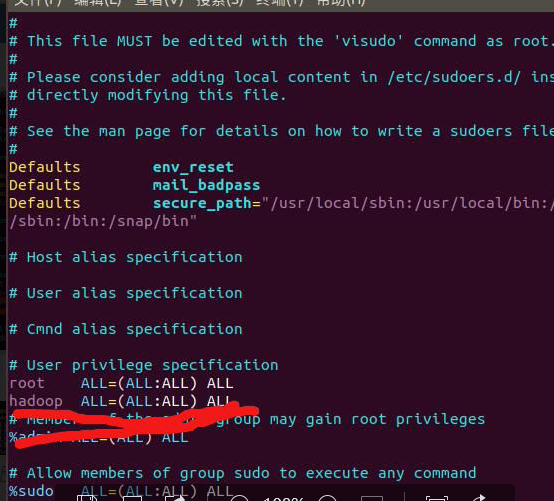
12.1为Hadoop用户添加sudo 权限
sudo vim /etc/sudoers
13 配置Hadoop
13.1安装文件上传工具
yum - y install lrzsz
13.2 在 /home /xue目录下新建apps文件夹,将源码压缩包上传到apps文件里
/xue目录下新建apps文件夹,将源码压缩包上传到apps文件里
sudo mkdir /home/xue/apps
13.3解压
/xue/apps/hadoop-2.7.7.tar.gz13.4 配置Hadoop环境变量
sudo vim /etc/profile
export HADOOP_HOME=/home/xu
e/apps/hadoop-2.7.7export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
13.5 将配置文件拷贝到node3,node4中
sudo scp /etc/profile node3:/etc/

13.6 同时操作所有节点,重新加载配置文件
source /etc/profile
13.7 配置各类 xml 文件
配置文件在所在目录 /home/xue/apps/hadoop-2.7.7/etc/hadoop
13.7.1 配置hadoop-env.sh
添加 JAVA_HOME=/usr/apps/javajdk1.8.0_181-amd64
13.7.2 配置 core-site.xml


13.7.3 配置 hdfs-site.xml
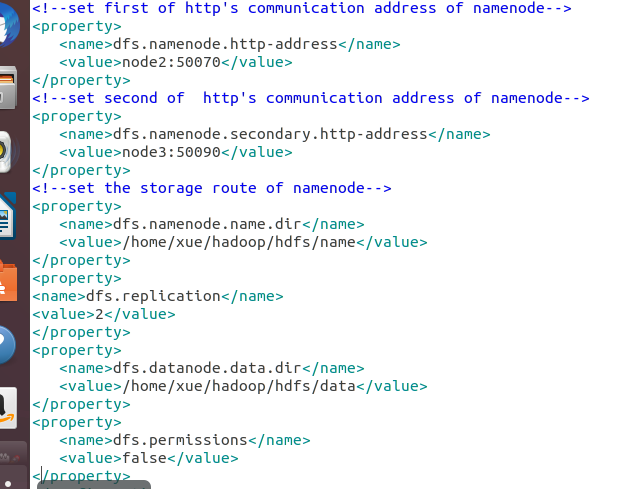
13.7.4 配置 mapred-site.xml.template
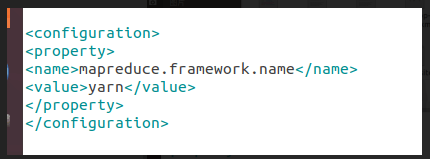
将 mapred-site.xml.template 修改 为 mapred-site.xml
13.7.5 配置 yarn-site.xml

13.7.6 修改slaves文件
13.8 把配置文件分发到各个节点
/xue/13.9 格式化 NameNode
hdfs namenode -format
13.10 测试安装
13.10.1 将hadoop主目录授权给当前用户(各节点都操作一次)
/xue/hadoop13.10.2 启动 HDFS
start-dfs.sh
13.10.3 启动 YARN
start-yarn.sh
14 完成最后步骤
14.1 网页管理界面
将node1,node2,node3,node4的IP地址添加到 windows 的 hosts 文件
14.2 登陆
在浏览器上登陆HDFS ,http://node2:50070
win10虚拟机搭建Hadoop集群(已完结)的更多相关文章
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 虚拟机搭建Hadoop集群
安装包准备 操作系统:ubuntu-16.04.3-desktop-amd64.iso 软件包:VirtualBox 安装包:hadoop-3.0.0.tar.gz,jdk-8u161-linux-x ...
- Mac上使用虚拟机搭建Hadoop集群
一. mini安装一台centos到虚拟机上 安装过程参考这篇博客http://www.linuxdown.net/install/setup/2015/0906/4053.html 二. 修改网络配 ...
- 配置ssh免密登录遇到的问题——使用VMware多虚拟机搭建Hadoop集群
搭建环境: 虚拟机 VMware12Pro 操作系统 centos6.8 hadoop 1.2.1 1.导入镜像文件,添加java环境 1.查看当前系统中安装的java,ls ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
随机推荐
- 系列教程 之 Android开发之旅
工作室持续推出Android开发系列教程与案例,供广大朋友分享交流技术经验,帮助喜欢Android的朋友们学习进步: 1. Android开发之旅(1) 之 Android 开发环境搭建 代码之间工作 ...
- 基于Netty的四层和七层代理性能方面的一些压力测试
本文我们主要是想测试和研究几点: 基于Netty写的最简单的转发HTTP请求的程序,四层和七层性能的差异 三种代理线程模型性能的差异,下文会详细解释三种线程模型 池和非池化ByteBuffer性能的差 ...
- Spring Boot2(四):使用Spring Boot多数据源实现读写分离
前言 实际业务场景中,不可能只有一个库,所以就有了分库分表,多数据源的出现.实现了读写分离,主库负责增改删,从库负责查询.这篇文章将实现Spring Boot如何实现多数据源,动态数据源切换,读写分离 ...
- net开发框架never
[一] 摘要 never是纯c#语言开发的一个框架,同时可在netcore下运行. 该框架github地址:https://github.com/shelldudu/never 同时,配合never_ ...
- never下的easysql
什么是EasySql 在我们早期写的代码中,想实现组装灵活的sql语句与参数,我们可以去翻阅早期自己写的代码 var @sb = new StringBuilder(); sb.Append(&quo ...
- 【记录】Mysql数据库更新主键自增
语法:id从1000开始自增: ALTER TABLE 表名 AUTO_INCREMENT = 1000;
- Java学习笔记——设计模式之六.原型模式(浅克隆和深克隆)
That there's some good in this world, Mr. Frodo. And it's worth fighting for. 原型模式(prototype),用原型实例指 ...
- Django框架rest_framework中APIView的as_view()源码解析、认证、权限、频率控制
在上篇我们对Django原生View源码进行了局部解析:https://www.cnblogs.com/dongxixi/p/11130976.html 在前后端分离项目中前面我们也提到了各种认证需要 ...
- 对比Hashtable,HashMap,TreeMap,谈谈对HashMap的理解
都实现了Map接口,存储的内容是基于key-value的键值对映射,一个映射不能有重复的键,一个键最多只能映射一个值. 1.初始化的时候:HashTable在不指定容量的情况下的默认容量是11,且不要 ...
- Codeforces 730B:Minimum and Maximum(交互式问题)
http://codeforces.com/problemset/problem/730/B 题意:一个交互式问题,给出一个n代表有n个数字,你可以问下标为x和y的数的大小,会给出"> ...