数据降维-LDA线性降维
1.什么是LDA?
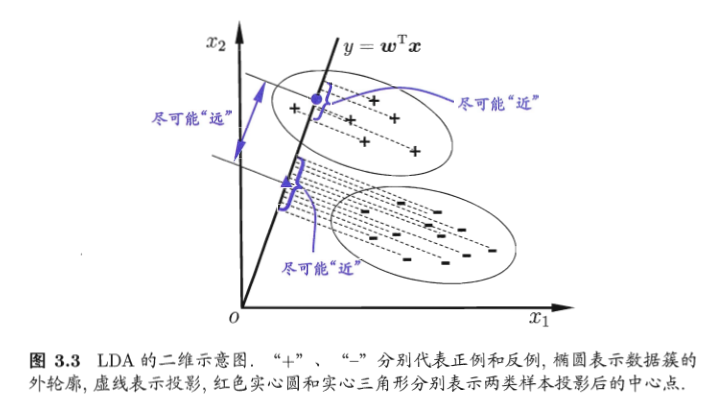
LDA线性判别分析也是一种经典的降维方法,LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“*投影后类内方差最小,类间方差最大*”。
什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
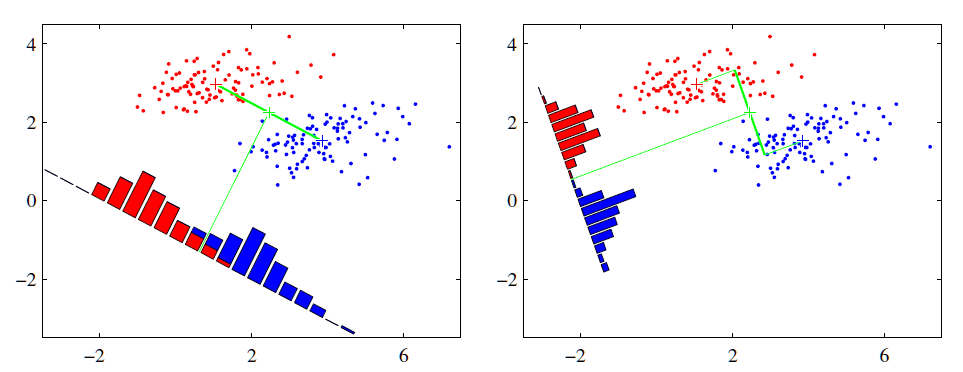
2.LDA原理
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets import warnings
warnings.filterwarnings('ignore') X,y=datasets.load_iris(True) # 特征值和特征向量
# solver是求解方法,svd表示奇异值分解
lda = LinearDiscriminantAnalysis(solver='svd',n_components=2)
X_lda = lda.fit_transform(X,y)
X_lda[:5]

# 1、总的散度矩阵
# 协方差
St = np.cov(X.T,bias = 1) # 2、类内的散度矩阵
# Scatter散点图,within(内)
Sw = np.full(shape = (4,4),fill_value=0,dtype=np.float64)
for i in range(3):
Sw += np.cov(X[y == i],rowvar = False,bias = 1)
Sw/=3 # 3、计算类间的散度矩阵
# Scatter between
Sb = St - Sw # 4、特征值,和特征向量
eigen,ev = linalg.eigh(Sb,Sw)
display(eigen,ev)
ev = ev[:, np.argsort(eigen)[::-1]] # 5、删选特征向量,进行矩阵运算
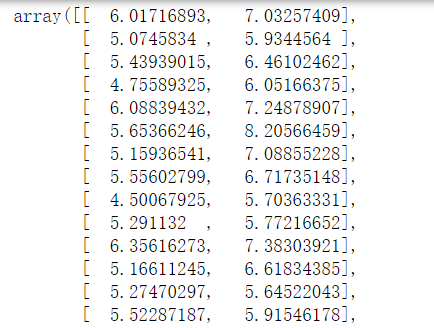
X.dot(ev)[:,:2]
计算得到的结果:
3.使用
使用和其他都一样,注意参数的含义
4.比较PCA和LDA
相同点:
1)两者均可以对数据进行降维。
2)两者在降维时均使用了矩阵特征分解的思想。
3)两者都假设数据符合高斯分布【正态分布】。
不同点:
1)LDA是有监督的降维方法,而PCA是无监督的降维方法
2)LDA降维最多降到类别数**k-1**的维数,而PCA没有这个限制。
3)LDA除了可以用于降维,还可以用于分类。
4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
5.机器学习中的监督学习和无监督学习
监督学习:
从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。
常见的有监督学习算法:回归分析和统计分类。最典型的算法是KNN和SVM。
无监督学习:
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
无监督学习的方法分为两大类:
(1)一类为基于概率密度函数估计的直接方法:指设法找到各类别在特征空间的分布参数,再进行分类。
(2)另一类是称为基于样本间相似性度量的简洁聚类方法:其原理是设法定出不同类别的核心或初始内核,然后依据样本与核心之间的相似性度量将样本聚集成不同的类别。
利用聚类结果,可以提取数据集中隐藏信息,对未来数据进行分类和预测。应用于数据挖掘,模式识别,图像处理等。
PCA和很多deep learning算法都属于无监督学习。
数据降维-LDA线性降维的更多相关文章
- LDA && NCA: 降维与度量学习
已迁移到我新博客,阅读体验更佳LDA && NCA: 降维与度量学习 代码实现放在我的github上:click me 一.Linear Discriminant Analysis(L ...
- 数据分析--降维--LDA和PCA
一.因子分析 因子分析是将具有错综复杂关系的变量(或样本)综合为少数几个因子,以再现原始变量和因子之间的相互关系,探讨多个能够直接测量,并且具有一定相关性的实测指标是如何受少数几个内在的独立因子所支配 ...
- LDA 线性判别分析
LDA, Linear Discriminant Analysis,线性判别分析.注意与LDA(Latent Dirichlet Allocation,主题生成模型)的区别. 1.引入 上文介绍的PC ...
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- LDA线性判别分析原理及python应用(葡萄酒案例分析)
目录 线性判别分析(LDA)数据降维及案例实战 一.LDA是什么 二.计算散布矩阵 三.线性判别式及特征选择 四.样本数据降维投影 五.完整代码 结语 一.LDA是什么 LDA概念及与PCA区别 LD ...
- LDA线性判别分析
LDA线性判别分析 给定训练集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能的近,异类样例点尽可能的远,对新样本进行分类的时候,将新样本同样的投影,再根据投影得到的位置进行判断,这个新样本的 ...
- 无监督学习:Linear Dimension Reduction(线性降维)
一 Unsupervised Learning 把Unsupervised Learning分为两大类: 化繁为简:有很多种input,进行抽象化处理,只有input没有output 无中生有:随机给 ...
- LDA线性判别分析(转)
线性判别分析LDA详解 1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2 ...
- LDA线性分析推广到多分类
感谢皮果提的文章: http://blog.csdn.net/itplus/article/details/12038441 http://blog.csdn.net/itplus/article 皮 ...
随机推荐
- Vue躬行记(5)——组件通信
组件之间除了保持独立之外,还需要相互通信,本章将介绍几种通信的方式. 一.直接访问 Vue提供了三个实例属性,可直接访问父组件.子组件和根实例,如下所列. (1)$parent:父组件. (2)$ro ...
- MySQL数据库的安装与配置(windows)
MySQL是目前最为流行的开放源码的数据库,是完全网络化的跨平台的关系型数据库系统,它是由瑞典MySQLAB公司开发,目前属于Oracle公司.任何人都能从Internet下载MySQL软件,而无需支 ...
- 使用asp.net core 3.0 搭建智能小车1
跟随.net core 3.0 一起发布的System.Device.Gpio 1.0已经可以让我们用熟悉的C#原汁原味的开发莓派上面的GPIO了.并且在 Iot.Device.Bindings这个包 ...
- 子树问题(DP)
这题显然是DP 首先,\(dp[i][j]\)表示树深度小于等于i,树的大小为j的有根树的数量$ 可以循环枚举根节点编号次大的子树的大小k. \(dp[i][j]=\sum^{j-1}_{k=1}dp ...
- 【 格式化时间(SimpleDateFormat)用法】
将特定字符串转换成Date格式 可以通过 new 一个 SimpleDateFormat 对象,通过对象调用parse方法实现 示例代码: String time = "2019-11-09 ...
- Python3 下的输出字符控制
最近在使用 python3 进行爬虫的时候,出现了令人窒息的,只会在 python2 中遇到的,没想到在 python3 还能碰见的输出编码问题,报错如下: UnicodeEncodeError: ' ...
- python实现清屏
往常都是用os.system("cls")清屏,但是发现每次执行完这个命令后都会出现一个空白字符 尝试了一下午,网上也没解决的办法 最后: os.system("cls& ...
- csp-s模拟测试101的T3代码+注释
因为题目过于大神所以单独拿出来说.而且既然下发std了颓代码貌似也不算可耻233 很难讲啊,所以还是写在代码注释里面吧 因为比较认真的写了不少注释,所以建议缩放到80%观看,或者拿到gedit上 1 ...
- CSPS模拟 89
- F#周报2019年第45期
新闻 邀请博客主们:2019年的F# Advent日历 宣告ML.NET 1.4 .NET Core与Jupyter笔记本 在Jupyter笔记本中使用ML.NET 用于Windows桌面的.NET ...