【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一、写在前面
之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验。所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对IP的检测。本文介绍的是利用Redis数据库实现的分布式爬虫,Redis是一种常用的菲关系型数据库,常用数据类型包括String、Hash、Set、List和Sorted Set,重要的是Redis支持主从复制,主机能将数据同步到从机,也就能够实现读写分离。因此我们可以利用Redis的特性,借助requests模块发送请求,再解析网页和提取数据,实现一个简单的分布式爬虫。
二、基本环境
Python版本:Python3
Redis版本:5.0
IDE: Pycharm
三、环境配置
由于Windows下的安装配置比较简单,所以这里只说Linux环境下安装和配置Redis(以Ubuntu为例)。
1.安装Redis
1)apt安装:
$ sudo apt-get install redis-server
2)编译安装:
$ wget http://download.redis.io/releases/redis-5.0.0.tar.gz
$ tar -xzvf redis-5.0.0.tar.gz
$ cd redis-5.0.0
$ make
$ make install
2.配置Redis
首先找到redis.conf文件,然后输入命令sudo vi redis.conf,进行如下操作:
注释掉bind 127.0.0.1 # 为了远程连接,这一步还可以将bind 127.0.0.1改为bind 0.0.0.0
protected-mode yes 改为 protected-mode no
daemonized no 改为 daemonized yes
如果6379端口被占用,还需要改一下端口号。除此之外,要远程连接还需要关闭防火墙。
chkconfig firewalld off # 关闭防火墙
systemctl status firewalld # 检查防火墙状态
3.远程连接Redis
使用的命令为redis-cli -h <IP地址> -p <端口号>
注:Windows查看IP地址用ipconfig,Linux查看IP地址用ifconfig。
四、基本思路
这次我爬取的网站为:http://www.shu800.com/,在这个网站的首页里有五大分类,分别是性感美女、清纯可爱、明星模特、动漫美女和丝袜美腿,所以要做的第一件事就是获取这几个分类的URL。然后,对每个分类下的网页进行爬取,通过查看网页元素可以发现如下信息:

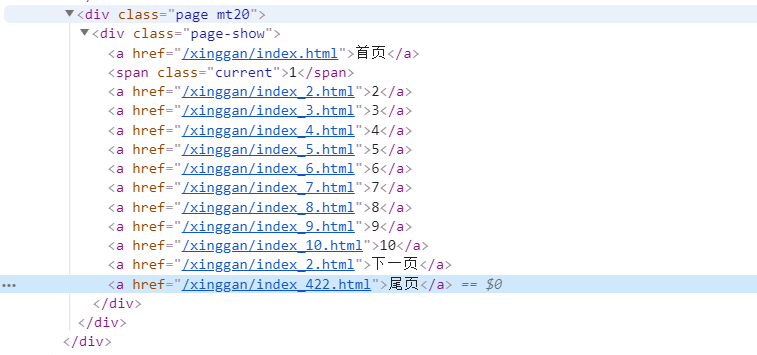
可以很明显地看到每一页的URL都是符合一定规律的,只要获取到了尾页的URL,将其中的页数提取出来,也就能构造每一页的URL了,这就比每次去获取下一页的URL简单多了。而对于每一个图集下的图片,也是用同样的方法得到每一页图片的URL。最后要做的就是从图片网页中将图片的URL提取出来,然后下载保存到本地。
这次分布式爬虫我使用了两台电脑,一台作为主机master,另一台作为从机slave。主机开启Redis服务,爬取每一页图片的URL,并将爬取到的URL保存到Redis的集合中,从机远程连接主机的Redis,监听Redis中是否有URL,如果有URL则提取出来进行下载图片,直至所有URL都被提取和下载。
五、主要代码
1.第一段代码是爬取每个页面里的美女图集的URL,并且把这些URL保存到数据库中,这里使用的是Redis中的集合,通过使用集合能够达到URL去重的目的,代码如下:
1 def get_page(url):
2 """
3 爬取每个页面下的美女图集的URL
4 :param url: 页面URL
5 :return:
6 """
7 try:
8 r = Redis(host="localhost", port=6379, db=1) # 连接Redis
9 time.sleep(random.random())
10 res = requests.get(url, headers=headers)
11 res.encoding = "utf-8"
12 et = etree.HTML(res.text)
13 href_list = et.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/ul/li/a/@href')
14 for href in href_list:
15 href = "http://www.shu800.com" + href
16 r.sadd("href", href) # 保存到数据库中
17 except requests.exceptions:
18 headers["User-Agent"] = ua.random
19 get_page(url)
2.第二段代码是从机监听Redis中是否有URL的代码,如果没有URL,等待五秒钟再运行,因为如果不稍作等待就直接运行,很容易超过Python的递归深度,所以我设置了一个等待五秒钟再运行。反之,如果有URL被添加到Redis中,就要将URL提取出来进行爬取,使用的方法是redis模块里的spop()方法,该方法会从Redis的集合中返回一个元素。需要注意的是,URL被提取出来后要先转成str。
1 def get_urls():
2 """
3 监听Redis中是否有URL,如果没有就一直运行,如果有就提取出来进行爬取
4 :return:
5 """
6 if b"href" in r.keys():
7 while True:
8 try:
9 url = r.spop("href")
10 url = url.decode("utf-8") # unicode转str
11 print("Crawling URL: ", url)
12 get_image(url)
13 get_img_page(url)
14 except:
15 if b"href" not in r.keys(): # 爬取结束,退出程序
16 break
17 else:
18 continue
19 else:
20 time.sleep(5)
21 get_urls()
六、运行结果
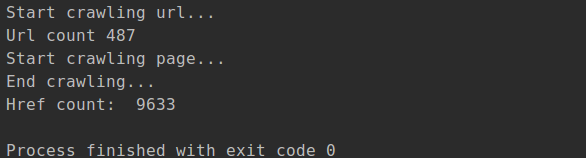
下图是在主机master上运行的截图,这里爬取到的图集总共有9633个:
从机slave会不断地从Redis数据库中提取URL来爬取,下图是运行时的截图:
打开文件夹看看爬下来的图片都有什么(都是这种标题,有点难顶啊...):
完整代码已上传到GitHub!
【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验的更多相关文章
- C#开发学习人工智能的第一步
前言 作为一个软件开发者,我们除了要学会复制,黏贴,还要学会调用API和优秀的开源类库. 也许,有人说C#做不了人工智能,如果你相信了,那只能说明你的思想还是狭隘的. 做不了人工智能的不是C#这种语言 ...
- VSTO学习笔记(十五)Office 2013 初体验
原文:VSTO学习笔记(十五)Office 2013 初体验 Office 2013 近期发布了首个面向消费者的预览版本,我也于第一时间进行了更新试用.从此开始VSTO系列全面转向Office 201 ...
- [EntLib]微软企业库5.0 学习之路——第一步、基本入门
话说在大学的时候帮老师做项目的时候就已经接触过企业库了但是当初一直没明白为什么要用这个,只觉得好麻烦啊,竟然有那么多的乱七八糟的配置(原来我不知道有配置工具可以进行配置,请原谅我的小白). 直到去年在 ...
- (大数据工程师学习路径)第一步 Linux 基础入门----文件系统操作与磁盘管理
介绍 本节的文件系统操作的内容十分简单,只会包含几个命令的几个参数的讲解,但掌握这些也将对你在学习后续其他内容的过程中有极大帮助. 因为本课程的定位为入门基础,尽快上手,故没有打算涉及太多理论内容,前 ...
- 学习Nodejs的第一步
最近看了几本关于Node.js的书,本来个人技术分享网站http://yuanbo88.com/是打算用Node.js作为服务器端语言来处理后台的,后来又改成了PHP(也是自己研究,毕竟网上DEMO多 ...
- fourinone分布式缓存研究和Redis分布式缓存研究
最近在写一个天气数据推送的项目,准备用缓存来存储数据.下面分别介绍一下fourinone分布式缓存和Redis分布式缓存,然后对二者进行对比,以供大家参考. 1 fourinone分布式缓存特性 1 ...
- 【docker Elasticsearch】Rest风格的分布式开源搜索和分析引擎Elasticsearch初体验
概述: Elasticsearch 是一个分布式.可扩展.实时的搜索与数据分析引擎. 它能从项目一开始就赋予你的数据以搜索.分析和探索的能力,这是通常没有预料到的. 它存在还因为原始数据如果只是躺在磁 ...
- Python爬虫学习==>第三章:Redis环境配置
学习目的: 学习非关系型数据库环境安装,为后续的分布式爬虫做基建 正式步骤 Step1:安装Redis 打开http://www.runoob.com/,搜索redis安装 打开搜索的内容,得到red ...
- 学习任务,阅读一下Redis分布式锁的官方文档
地址: https://redis.io/topics/distlock 这是一篇质疑RedLock的论文:https://martin.kleppmann.com/2016/02/08/how-to ...
随机推荐
- java字符串的替换replace、replaceAll、replaceFirst的区别
看代码: String s = "my.test.txt"; System.out.println(s.replace(".", "#")) ...
- NOIP 2017 惊魂记
考完了NOIP三周后才开始补……然后又补了一周…… DAY -1: 晚上吃了一顿送行宴散伙饭,然后默默地看了一遍之前所有考试后写的题解,再读了几遍板子,然后和QTY一起和达哥又一次在外面谈了一个小时, ...
- java学习笔记(基础篇)—数组模拟实现栈
栈的概念 先进后出策略(LIFO) 是一种基本数据结构 栈的分类有两种:1.静态栈(数组实现) 2.动态栈(链表实现) 栈的模型图如下: 需求分析 在编写代码之前,我习惯先对要实现的程序进行需求分析, ...
- form 利用BeginCollectionItem提交集合List<T>数据 以及提交的集合中含有集合的数据类型 如List<List<T>> 数据的解决方案
例子: public class IssArgs { public List<IssTabArgs> Tabs { get; set; } } public class IssTabArg ...
- C++小游戏——井字棋
#include<cstdio> #include<windows.h> #include<ctime> int main() { srand(time(NULL) ...
- Excel催化剂开源第42波-与金融大数据TuShare对接实现零门槛零代码获取数据
在金融大数据功能中,使用了TuShare的数据接口,其所有接口都采用WebAPI的方式提供,本来还在纠结着应该搬那些数据接口给用户使用,后来发现,所有数据接口都有其通用性,结合Excel灵活友好的输入 ...
- 2019暑假集训 BLO
题目描述 Byteotia城市有n个 towns m条双向roads. 每条 road 连接 两个不同的 towns ,没有重复的road. 所有towns连通. 输入 输入n<=100000 ...
- linux初学者-DNS集群篇
linux初学者-DNS集群篇 DNS服务器一般在使用时,为了缓解服务器的压力,多使用一个主DNS服务器,多个副DNS服务器,这些DNS服务器就组成了一个DNS集群. 在DNS主服务器配置好后,需要另 ...
- Codeforces1144D(D题)Equalize Them All
D. Equalize Them All You are given an array aa consisting of nn integers. You can perform the follow ...
- HTTP_5_通信数据转发程序:代理、网关、隧道
HTTP通信时,除客户端和服务器之外,还有一些用于通信数据转发的应用程序,例如代理,网关,隧道.配合服务器工作. 代理 转发功能,客户端与服务器之间可有多个代理, 缓存代理:减少服务器压力,透明代理: ...