从原理到应用,人人都懂的ChatGPT指南
作者:京东科技 何雨航
引言
如何充分发挥ChatGPT潜能,已是众多企业关注的焦点。但是,这种变化对员工来说未必是好事情。IBM计划用AI替代7800个工作岗位,游戏公司使用MidJourney削减原画师人数......此类新闻屡见不鲜。理解并应用这项新技术,对于职场人来说重要性与日俱增。
一、GPT模型原理
理解原理是有效应用的第一步。ChatGPT是基于GPT模型的AI聊天产品,后文均简称为GPT。
从技术上看,GPT是一种基于Transformer架构的大语言模型(LLM)。GPT这个名字,实际上是"Generative Pre-trained Transformer"的缩写,中文意为“生成式预训练变换器”。
1.大模型和传统AI的区别是什么?
传统AI模型针对特定目标训练,因此只能处理特定问题。例如,很会下棋的AlphaGO。
而自然语言处理(NLP)试图更进一步,解决用户更为通用的问题。可以分为两个关键步骤:自然语言理解(NLU)和自然语言生成(NLG)。
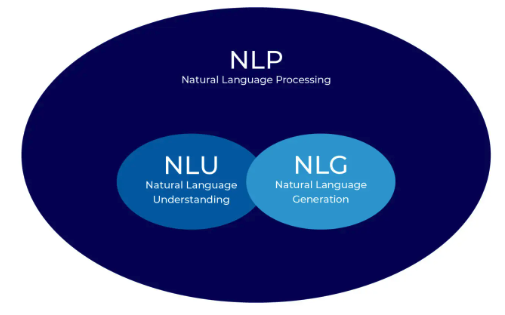
以SIRI为代表的人工智能助手统一了NLU层,用一个模型理解用户的需求,然后将需求分配给特定的AI模型进行处理,实现NLG并向用户反馈。然而,这种模式存在显著缺点。如微软官方图例所示,和传统AI一样,用户每遇到一个新的场景,都需要训练一个相应的模型,费用高昂且发展缓慢,NLG层亟需改变。
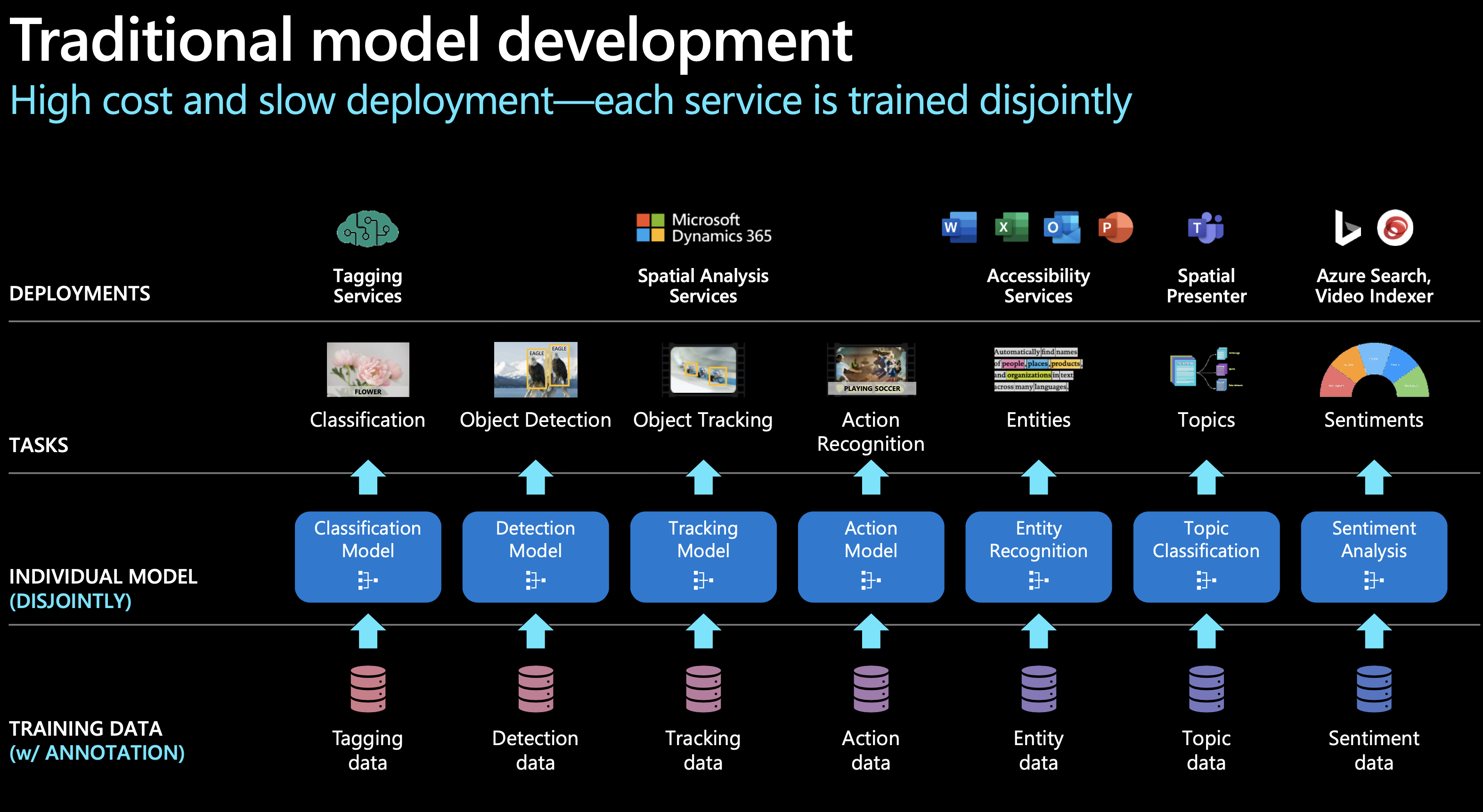
大型语言模型(如GPT)采用了一种截然不同的策略,实现了NLG层的统一。秉持着“大力出奇迹”的理念,将海量知识融入到一个统一的模型中,而不针对每个特定任务分别训练模型,使AI解决多类型问题的能力大大加强。
2.ChatGPT如何实现NLG?
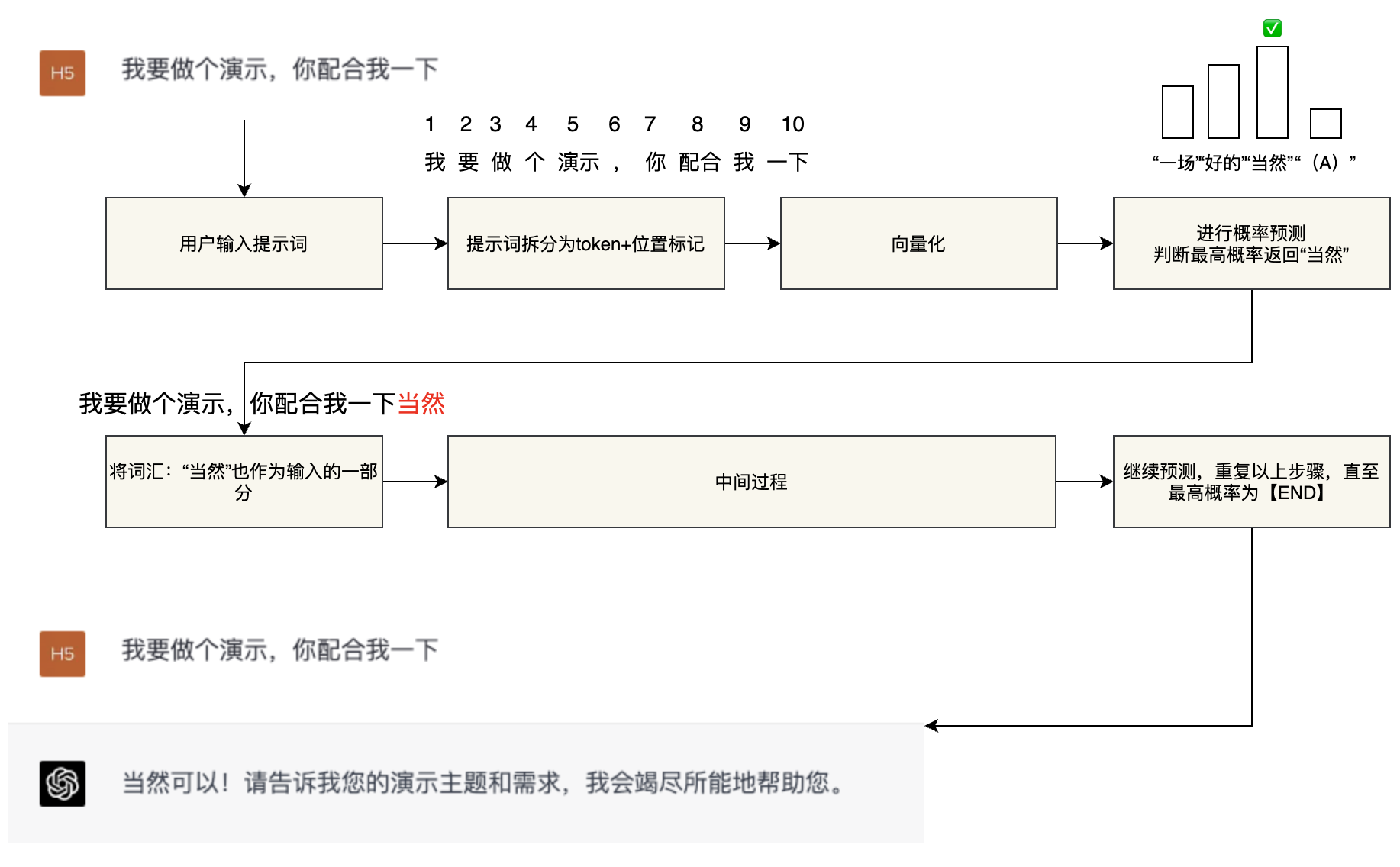
AI本质上就是个逆概率问题。GPT的自然语言生成实际上是一个基于概率的“文字接龙”游戏。我们可以将GPT模型简化为一个拥有千亿参数的“函数”。当用户输入“提示词(prompt)”时,模型按照以下步骤执行:
①将用户的“提示词”转换为token(准确地说是“符号”,近似为“词汇”,下同)+token的位置。
②将以上信息“向量化”,作为大模型“函数”的输入参数。
③大模型根据处理好的参数进行概率猜测,预测最适合回复用户的词汇,并进行回复。
④将回复的词汇(token)加入到输入参数中,重复上述步骤,直到最高概率的词汇是【END】,从而实现一次完整的回答。这种方法使得GPT模型能够根据用户的提示,生成连贯、合理的回复,从而实现自然语言处理任务。
3.上下文理解的关键技术
GPT不仅能理解用户当前的问题,还能基于前文理解问题背景。这得益于Transformer架构中的“自注意力机制(Self-attention)”。该机制使得GPT能够捕捉长文本中的依赖关系。通俗地说,GPT在进行文字接龙判断时,不仅基于用户刚输入的“提示”,还会将之前多轮对话中的“提示”和“回复”作为输入参数。然而,这个距离长度是有限的。对于GPT-3.5来说,其距离限制为4096个词汇(tokens);而对于GPT-4,这个距离已经大幅扩展至3.2万个tokens。
4.大模型为何惊艳?
我们已经介绍了GPT的原理,那么他是如何达成这种神奇效果的呢?主要分三步:
①自监督学习:利用海量的文本进行自学,让GPT具备预测上下文概率的基本能力。
②监督学习:人类参与,帮助GPT理解人类喜好和期望的答案,本质为微调(fine-tune)。
③强化学习:根据用户使用时的反馈,持续优化和改进回答质量。
其中,自监督学习最关键。因为,大模型的魅力在于其“大”——大在两个方面:
①训练数据量大:
即训练大模型的数据规模,以GPT-3为例,其训练数据源为互联网的各种精选信息以及经典书籍,规模达到了45TB,相当于阅读了一亿本书。
②模型参数量大:
参数是神经网络中的一个术语,用于捕捉数据中的规律和特征。通常,宣称拥有百亿、千亿级别参数的大型模型,指的都是其参数量。
追求大型模型的参数量是为了利用其神奇的“涌现能力”,实现所谓的“量变引起质变”。举例来说,如果要求大模型根据emoji猜电影名称,如代表《海底总动员》。可以看到,当模型参数达到千亿级别时,匹配准确度大幅度提升。这表明模型参数量的增加对提高模型表现具有重要意义。
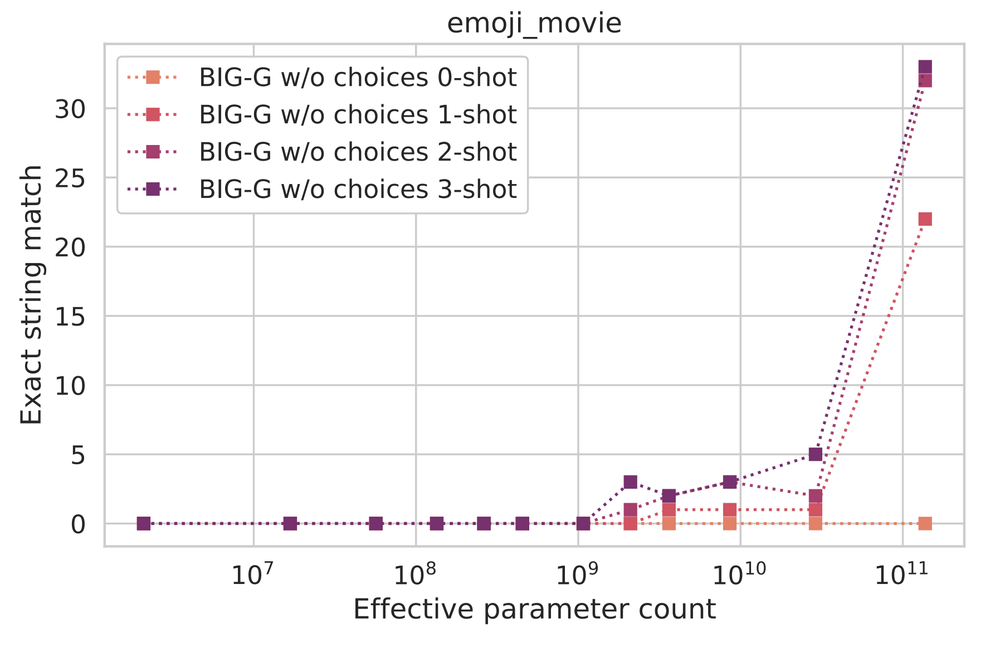
处理其他多类型任务时,也有类似的效果:
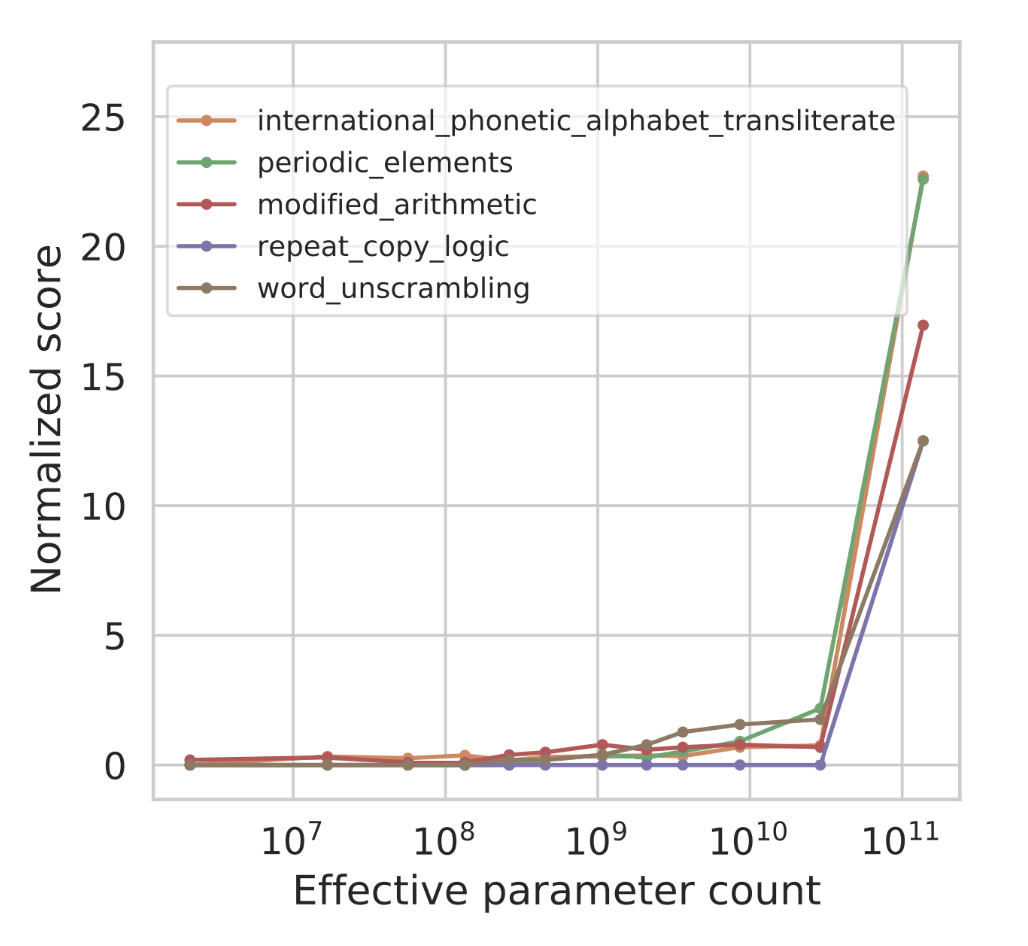
如实验所揭示的,只有当模型参数达到千亿级别,大模型的优势才得以凸显。GPT之外的其他大模型,也有类似的表现。
为什么?
目前主流观点认为,要完整完成一个任务,实际上需要经过很多子步骤。当模型大小不足时,大语言模型无法理解或执行所有步骤,导致最终结果不正确,达到千亿级参数时,其解决问题的全链路能力已经足够。人们以最终结果的正误作为评判标准,导致认为是一种“涌现”。
在“涌现”问题上,人与猩猩的比喻很有趣。人类的大脑容量比猩猩大3倍,这种差异使得人类能够进行更复杂的思考、沟通和创造。两者的结构没有显著差异,这不也是“涌现”吗?
GPT-3.5正是千亿模型,参数达到了1750亿。相较于GPT-3,GPT-3.5主要针对模型参数进行了微调,使其在问答时更符合人类的习惯。据悉,GPT-4的模型参数量甚至达到了GPT-3.5的五倍之多,这也解释了为何GPT-4表现得如此聪明(体验过的人应该都能理解)。下面是GPT模型演进历史:

二、GPT的局限性
综上,GPT模型具有明显的、突破性的优势。典型的优势包括:①强大的语言理解能力;②极为广泛的知识储备;③学习能力与推理能力等等。这些能力让人们感觉人工智能真正拥有了“脑子”,想象着使用GPT解决一切问题。
然而,若要深入应用该技术,有必要了解其局限性,以便在实际应用中取长补短。主要总结六大局限:
1.逻辑不透明
GPT模型的回答本质上是概率。传统的软件开发中,接口的输入和输出参数都是确定的,而在给定输入参数(即提示词)的情况下,GPT的回复却有一定随机性。当大家将ChatGPT作为聊天工具使用时,这种不精确可以是用户的谈资;当涉及到商业化软件应用时,设计时就需要特别注意降低不确定性,在大部分产品场景下,用户都很重视确定性。
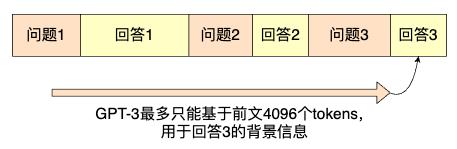
2.短期记忆差
得益于自注意力机制,ChatGPT具备了多轮对话能力。然而,它的记忆长度相当有限,GPT-3.5模型仅支持向前追溯4096个tokens用于回复的参考。更糟糕的是,这4096个tokens还包括ChatGPT之前回复用户的部分!这使得其捉襟见肘的记忆更加难堪,堪称电子金鱼。好在GPT-4已经将上下文token上限扩展至3.2万个,一定程度上缓解了这个问题。
3.资源消耗多
ChatGPT的智能需要消耗大量算力,而运行大规模高端显卡需要消耗大量电力。在五年之内,依靠半导体制程的进一步升级和大模型的广泛应用,算力与电力的边际成本将逐渐转变为固定成本,也就解决了本问题。
4.响应速度慢
由于模型极大,GPT在回复时也无法做到瞬时响应,正如用户实际体验,ChatGPT是逐词回复的。企业在设计相关产品时需要特别关注应用场景:
①需要避免将GPT用于高并发的场景,本服务依赖的接口调用并发上限非常低。
②产品设计上避免用户急切需要结果的应用场景,确保用户能够“等得起”。
5.行业认知浅
诚然,ChatGPT拥有来自互联网和经典书籍的丰富知识。然而,真正的企业级专业知识往往源于特定领域的深入研究和实践,这些真知灼见无法仅凭互联网上的知识获取。因此,若希望GPT充当企业参谋,只能帮助梳理战略框架,但难以为企业提供颇具洞察的策略建议。
6.价值未对齐
①在自监督学习阶段,GPT训练数据英文占比高达92%。②在监督学习阶段,传授道德观的工程师主要来自英语世界。③在强化学习环节,也可能受到恶意用户输入错误价值观的影响。因此,GPT的“精神内核”是以西方价值观为基石的,这可能导致生成的文字难以符合我国的文化背景和价值观。
三、GPT的多层应用指南
在了解了GPT模型的原理及局限性后,终于可以看看怎么用好这项技术了。我按照感知其能力的直观性,由浅入深将其分为五层,逐层进行介绍。
第一层:聊天能力
在此类用法中,GPT的回答就是给客户的交付物,是GPT模型最简单、最直观的用法。
1.套壳聊天机器人
通过使用OpenAI官方接口,开发的套壳聊天机器人产品。这类产品之所以存在,原因懂得都懂。否则,用户为何不直接使用ChatGPT呢?此类产品难以形成现象级应用,且竞争激烈。由于比较灰色且内容未经过滤,网站被封后又换域名的故事将持续上演。
2.场景化问答
这种模式对GPT的回复场景进行了约束。通过限定提示词、嵌入大量特定领域知识以及微调技术,使GPT能够仅基于某类身份回答特定类型的问题。对于其他类型的问题,机器人会告知用户不了解相关内容。这种用法可以有效约束用户的输入,降低许多不必要的风险,但是想训练一个出色的场景化机器人,也需要投入许多精力。典型应用包括智能客服、智能心理咨询和法律咨询等。微软的new Bing正是此类应用的杰出代表,其俏皮傲娇的回复风格,深受网友的喜爱。
第二层:语言能力
在本层,我们充分发挥ChatGPT的语言天赋,辅助各种基于文字的处理工作。从这一层开始,需要使用one-shot或few-shot(在提示词中给ChatGPT一个或多个示例)来提升ChatGPT的表现。与用户的交互不再局限于聊天窗口,提前预制提示词模板,用户只能输入限定的信息,对应提示词的空槽位。

预制带槽位提示词模板的应用基本流程如下:

1.文字处理类
此类应用主要有三种用法:
①文章提炼
可以输入文章段落,要求提取段落主旨。但受token数限制,难以总结整篇文章。也可要求生成短标题、副标题等。在提示词中预留【案例】槽位,让用户输入一些参考案例,GPT便可以学习相应的风格,进行针对性的输出。
②润色/改写
可用于文章的初步润色,能够消除错别字、错误标点等。改写则可以转换文章风格,如更改成小红书风格等。
③文章扩写
在有大纲基础上,分段进行文章扩写。受token限制,如一次要求过长,输出的扩写难以做到前后呼应。ChatGPT本身不会产生新知识,文章扩写难以写出深刻见地,只能生成口水文。通过给定关键词和案例,要求生成有规律的短文案,是应用其文章扩写能力的有效方法。
2.翻译
GPT模型训练时学习了大量语言,具备跨语言能力。无论用何种语言与其沟通,只要理解意图,分析问题能力是不区分语言的。因此,翻译对GPT来说很轻松。当然也仅限基本翻译,不要指望其能翻译的“信、达、雅”。
3.情感分析
GPT能理解文字背后的用户情绪。例如,在客服模块引入GPT能力,基于用户语音和文字快速判断情绪状况,提前识别潜在客诉,在情绪爆发前进行有效安抚。
第三层:文本能力
在本层,GPT的能力已经超越了语言,它通过大量学习,凡是与文本相关的任务,都能胜任。它甚至具备真正的学习能力,使用few-shot技巧,能解决训练数据中不存在的问题。本层的应用范围极广,将迸发出大量极具创造力的产品。我在这里仅举一些典型例子。
1.写代码
ChatGPT能编写SQL、Python、Java等代码,并帮忙查找代码BUG。与撰写文章的原因类似,不能要求其编写过长的代码。
2.写提示词
要求GPT创作提示词是与其他AI联动的简单方式。例如,要求GPT为midjourney撰写提示词,已成为非常主流的做法。
3.数据分析
ChatGPT可以直接进行数据分析,或与EXCEL配合进行数据分析。它将数据分析操作成本降至极低,大幅提升了数据分析的效率。
第四层:推理能力
在前几层中,我们已经见识了GPT的推理能力。以GPT的推理能力替代手动点击操作流,将带来B端和C端的产品设计的颠覆式变化。个人认为,短期内B端的机会大于C端。经过互联网20年的发展,C端用户的主要需求已基本得到满足,颠覆C端用户的操作路径会带来较大的学习成本。而B端则有很大的发挥空间,这里将其分为三个阶段:
1.自动化工作流串联
利用ChatGPT理解人类意图的能力,结合langChain技术将提示词和公司内各项工作的网页链接整合。员工无需寻找各种链接,在需要执行相关操作时,会自动跳转到相应页面,进行下一步操作。以ChatGPT为智慧中枢,真正实现将B端各类操作有机整合。下图为设计思路的示例。
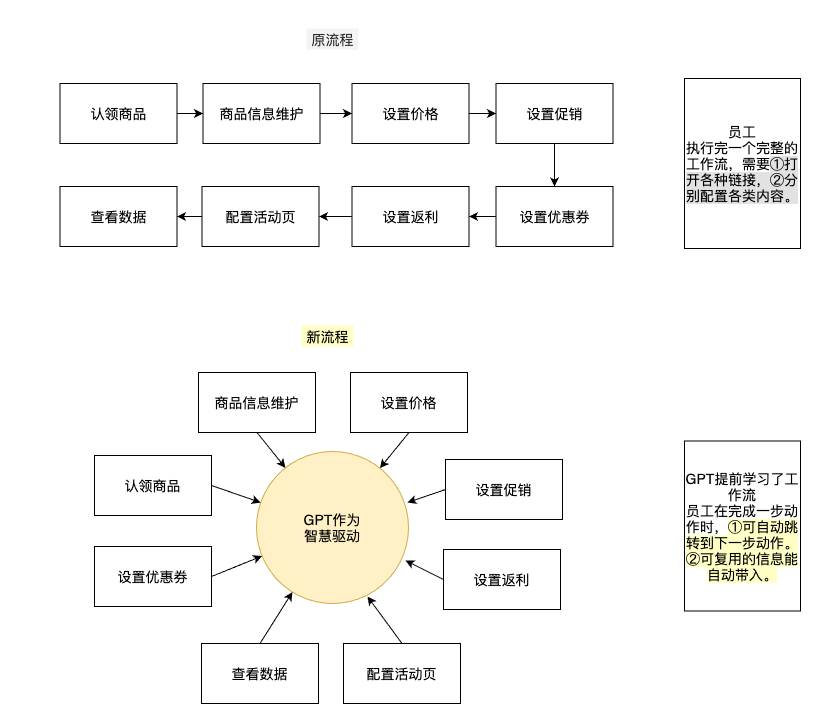
2.AI辅助决策
以第一个阶段为基础,将对应页面的部分功能与GPT联动。这样,在员工执行操作时,部分功能可以由AI实现,成倍提升效率。微软Copilot正是这类产品的代表,比如可以实现在Excel中说明自己想要进行的数据分析,无需寻找相关公式,数据分析就自动做好了。
3.全自动AI工作流
本阶段目前还处于演示层面,呈现了未来的愿景。如前文所述,GPT很难解决特定领域的细节问题,除非针对某个场景进行大量的微调与私有数据部署。AutoGPT、AgentGPT都属于此类。
第五层:国产大模型
AI技术是科学而非神学,大模型的原理也不是秘密。美国能做到,我国不仅能,而且有必要。只要训练数据质量达标,模型参数突破千亿便具备推理能力,突破八千亿可与GPT-4匹敌。采用大量中文语料和中文微调,我国必将拥有符合本国文化背景、价值观的大模型。
然而,路漫漫其修远兮,困难也是极多的,如:训练成本极高、训练数据质量要求高、模型优化复杂、马太效应明显等。因此,预计在未来五年内,中国最多只会有3家知名大模型服务商。
大模型是AI时代的基础设施,大部分公司选择直接应用,直接获取商业价值。在这个大背景下,愿意投身自有大模型的公司就更加难能可贵了。在此,我谨代表个人向那些勇于投身于自有大模型建设的国内企业表示敬意。
四、总结
总的来看,ChatGPT是一款跨时代的产品。不同层面对GPT技术的应用,体现出了一些共性的机会。我总结了三项未来具有巨大价值的能力。
1.问题分解技术
鉴于GPT回复的限制在于最多只能基于32,000个tokens,因此有效地将问题分解成子问题并交由GPT处理显得尤为关键。未来的工作模式可能将问题拆解为子问题,再组装子问题的解决方案。在具体实施时,还需要对子问题的难度进行判断,有些问题可以交给一些小模型处理,这样就可以有效的控制应用成本。
2.三种调优方法
想要让GPT在多个层面上发挥特定的作用,主要有三种交互方式,成本从低到高分别为:
| 调优方法 | 优势 | 缺点 |
| 提示词优化 | 提升效果明显成本极低 | 占用token多,影响上下文关联长度 |
| embedding | 扩展GPT知识调优成本较低 | GPT并非真的理解了相关的内容,而是在遇到相关问题时,能够基于给定的知识库回答。 |
| 微调技术 | 搭建真正的私有模型,GPT能理解相关的问题。 | 成本较高,需要大量的“问答对”,训练过程非常消耗token。 |
①提示词优化
通过探索找到最优提示词模板,预留特定槽位以供用户输入。仅通过提示词优化就能实现广泛功能,许多基于GPT的产品,其底层就是基于特定提示词的包装。好的提示词需包含角色、背景、GPT需执行的任务、输出标准等。根据业界的研究,好的提示词能使GPT3.5结果的可用性由30%飙升至80%以上。提示词优化毫无疑问是这三种方法中最重要的。
②embedding
这是一种搭建自有知识库的方法,将自建知识库使用embedding技术向量化,这样GPT就能基于自有数据进行问答。
③微调(finetune)
通过输入大量问答,真正教会GPT如何回答某类问题,成本较前两者更高。优势在于将提示词的短期记忆转化为私有模型的长期记忆,从而释放宝贵的Token以完善提示词其他细节。
以上三种方式并不冲突,在工程实践中往往互相配合,特别是前两种。
3.私有数据积累
私有数据集的价值得到进一步提升,各行业可基于此对GPT进行二次包装,解决特定领域问题。建议使用微软Azure提供的GPT接口,搭建带有私有数据的大语言模型产品。因微软面向B端的GPT服务为独立部署,不会将私有数据用于大模型训练,这样可以有效保护私有数据。毕竟私有数据一旦公开,价值将大打折扣。
凭借以上几项能力加持,大语言模型可以充分释放在解决依赖电脑的重复性劳动的生产力。我将下一个时代(3年内)的业务运转模式总结如下图:
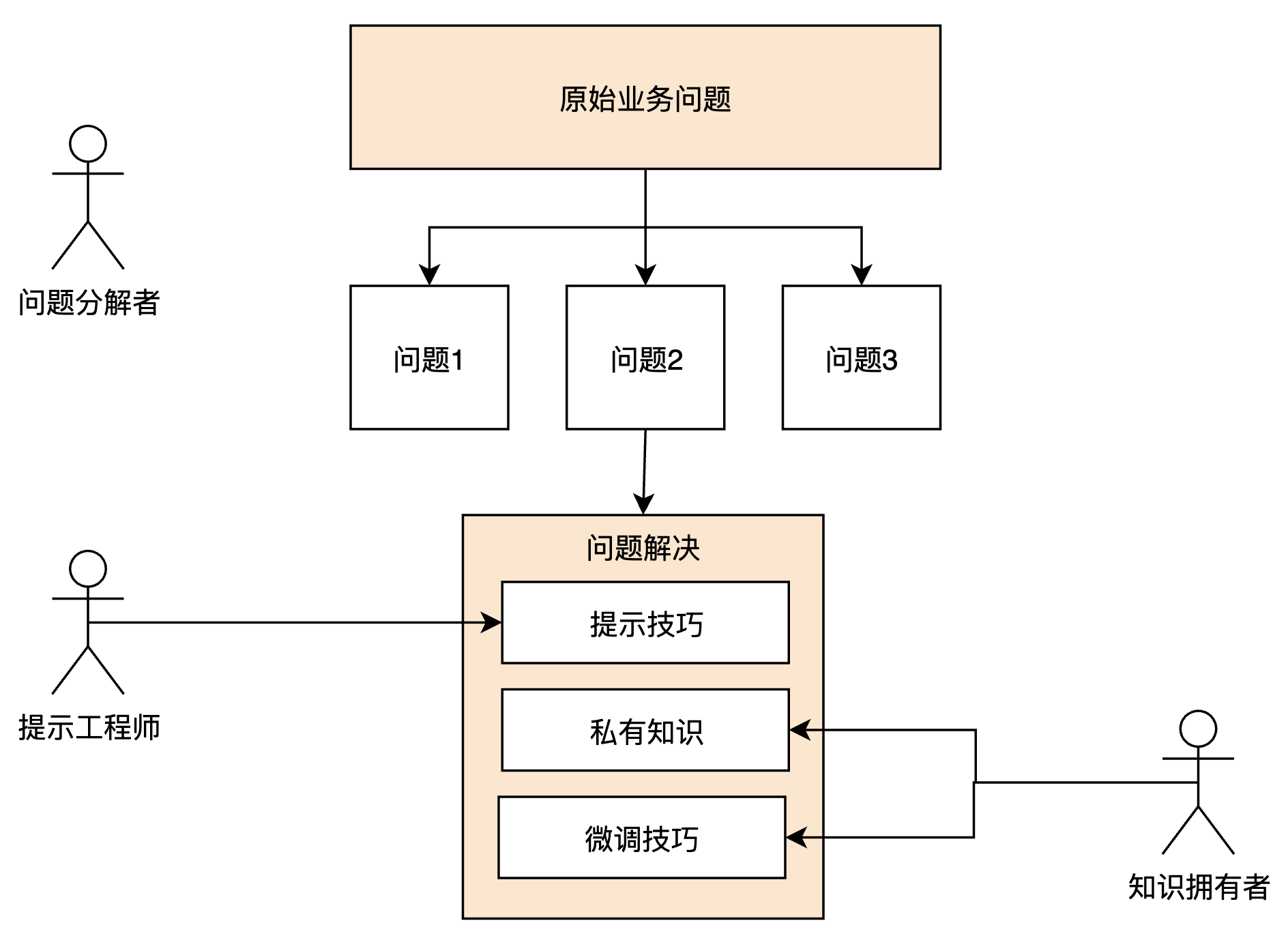
企业会根据三大能力衍生出三大类角色:
①问题分解者
这类角色很清楚大语言模型能力的边界,能够将一个业务问题有效的分解为GPT能处理的子问题,并能根据问题结果,将子问题进行拼装。
②提示工程师
这类角色深谙与GPT沟通之道,能够根据不同的问题类型,给出有效的提示词模板,极大提升GPT的输出质量。
③知识拥有者
这类角色有大量的行业knowhow,并且能够将知识进行结构化,传授给GPT。对应现在的领域专家。
在这种模式的推动下,GPT将会成为企业提效的重要帮手,可以解决大量重复劳动,可以提供有价值的参考。但人的主观能动性仍起决定性作用。
五、写在最后
即使以GPT-4为代表的AI技术保持当前的水平,带来的效率提升已经令人震惊,更遑论其仍以飞快的速度进化。从技术革命的发展史来看,一项大幅度提效的新技术出现,往往先惠及B端,而后才慢慢在C端开始释放巨大的价值。这是由企业对效率天然的敏感性所决定的,而改变C用户的习惯需要大量学习成本与场景挖掘,滞后效应较强。举三个例子大家就懂了:
1. 回顾第一次工业革命,内燃机的出现先导致了纺织女工的大量失业,而后才逐渐找到了各种C端场景,推动了社会生产力的大幅度上升。
2. ChatGPT可以更快的生成口水文,但是C端用户对阅读的诉求是没有增加的。对于营销号公司来说,效率提升了,所需要的人变少了。
3. MidJourney可以快速生成抱枕的图案,但是C端用户并不会购买更多的抱枕,那么需要作图的人员就少了。
一场信息化企业的內效革命就要到来了,依靠电脑的重复劳动将会消失,因为大模型最擅长学这个了。正如我文初所举得案例一样,像IBM公司缩减7800个编制的案例,只会发生的越来越频繁。
AI时代真的已经到来,每个岗位都需要思考,如何让AI成为工作上的伙伴。
从原理到应用,人人都懂的ChatGPT指南的更多相关文章
- 人人都懂区块链--pdf电子版学习资料下载
人人都懂区块链 21天从区块链“小白”到资深玩家电子版pdf下载 链接:https://pan.baidu.com/s/1TWxYv4TLa2UtTgU-HqLECQ 提取码:6gy0 好的学习资料需 ...
- 【人人都懂密码学】一篇最易懂的Java密码学入门教程
密码与我们的生活息息相关,远到国家机密,近到个人账户,我们每天都在跟密码打交道: 那么,密码从何而来?生活中常见的加密是怎么实现的?怎么保证个人信息安全?本文将从这几方面进行浅谈,如有纰漏,敬请各位大 ...
- 人人都懂的HTML基础知识-HTML教程(1)
01.HTML基础简介 HTML (HyperText Markup Language,超文本标记语言) 不是一门编程语言,而是一种用于定义内容结构的标记语言,用来描述网页内容,文件格式为.html. ...
- <人人都懂设计模式>-单例模式
这个模式,我还是了解的. 书上用了三种不同的方法. class Singleton1: # 单例实现方式1 __instance = None __is_first_init = False def ...
- <人人都懂设计模式>-装饰模式
书上,真的用一个人穿衣打拌来讲解装饰模式的呢. from abc import ABCMeta, abstractmethod class Person(metaclass=ABCMeta): def ...
- <人人都懂设计模式>-中介模式
真正的用房屋中介来作例子, 好的书籍总是让人记忆深刻. class HouseInfo: def __init__(self, area, price, has_window, has_bathroo ...
- <人人都懂设计模式>-状态模式
同样是水,固态,气态,液态的变化,是由温度引起. 引此为思考状态模式. from abc import ABCMeta, abstractmethod # 引入ABCMeta和abstractmeth ...
- [转帖]看完这篇文章,我奶奶都懂了https的原理
看完这篇文章,我奶奶都懂了https的原理 http://www.17coding.info/article/22 非对称算法 以及 CA证书 公钥 核心是 大的质数不一分解 还有 就是 椭圆曲线算法 ...
- 腾讯QQ会员技术团队:人人都可以做深度学习应用:入门篇(下)
四.经典入门demo:识别手写数字(MNIST) 常规的编程入门有"Hello world"程序,而深度学习的入门程序则是MNIST,一个识别28*28像素的图片中的手写数字的程序 ...
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
随机推荐
- HTTPS、HTTP/2前端入门篇
随着网络安全重要性日益凸显,越来越多的站点已经全站切换到HTTPS,其中很多HTTPS站点同时将HTTP协议升级到了HTTP/2.作为一只前端,最近一直在学习和应用相关知识点,便总结梳理如下. 一.何 ...
- MAC下使用Wireshark调试chrome浏览器的HTTP/2流量
1.设置环境变量 mkdir ~/tls && touch ~/tls/sslkeylog.log #zsh echo "\nexport SSLKEYLOGFILE=~/t ...
- Caused by: java.lang.NoSuchMethodError
ERROR [localhost-startStop-1] - Context initialization failedorg.springframework.beans.factory.BeanD ...
- CSS伪类三角形
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于IDEA发出基于APR的本地库加载失败错误的解决------->求解决!
问题描述 在没有使用Maven项目启动该Project时,Tomcat可以正常使用,但在这里会显示这样的错误: 这个错误,已经查了两天了,相关文件以及解决方法已经翻烂了,还没有解决,放出来集思广益一下 ...
- 使用ELRepo升级CentOS内核
在腾讯云中部署了一些服务器,操作系统使用的是CentOS 7.6,但是其默认内核版本较低,现使用ELRepo对CentOS的内核进行升级. 操作环境 服务器:腾讯云轻量应用服务器 操作系统:CentO ...
- 集训第二周计划:把cf近期的div2除了最后一题给切完
太菜了太菜了,弄个训练计划. 晚上没事干的时候我想把博客园皮肤改一下,搜着搜着不知道怎么回事点进去一些竞赛选手的博客,比如这个 https://www.cnblogs.com/soda-ma/p/13 ...
- 可靠消息最终一致性【本地消息表、RocketMQ 事务消息方案】
更多内容,前往IT-BLOG 一.可靠消息最终一致性事务概述 可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能够接收消息并处理事务成功,此方案强调 ...
- 从pcap文件中提取pcma音频
操作系统 :Windows10_x64 .CentOS 7.6.1810_x64 wireshark版本:3.6.12 Python 版本 : 3.9.12 一.背景描述 工作中有时候会遇到需要从 ...
- 迁移学习(NRC)《Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation》
论文信息 论文标题:Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation论文作者:Shiq ...