8000字讲透OBSA原理与应用实践
摘要:OBSA项目是围绕OBS建立的大数据和AI生态,其在不断的发展和完善中,目前有如下子项目:hadoop-obs项目和flink-obs项目。
文章作者:存储服务产品部开发者支持团队
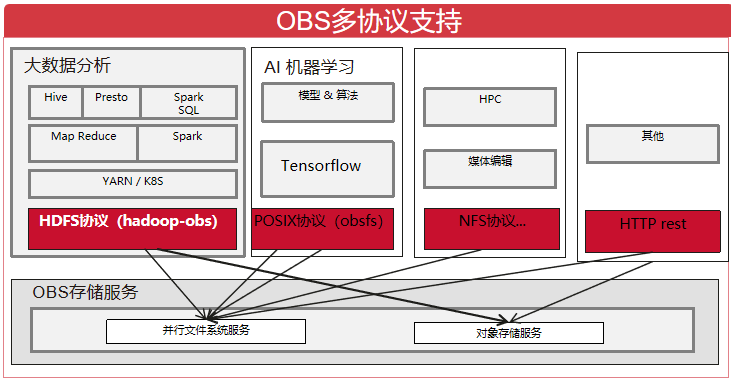
OBS存储服务概述
华为云OBS存储服务提供了“对象存储服务”和”并行文件系统服务”。
1.对象存储服务:提供传统的对象存储语义。
2.并行文件系统服务:简称文件桶,基于对象存储服务提供了一种经过优化的高性能文件系统,其实现了追加写,文件截断,目录重命名原子操作等一系列特性,并和对象存储服务一样提供了毫秒级别访问时延,TB级别带宽和百万级别的IOPS,因此非常适用于大数据分析等场景,华为云的MRS,DLI等大数据分析服务均已支持OBS服务作为其底层的存储服务。
OBSA项目概述
1.OBSA项目是围绕OBS建立的大数据和AI生态,其在不断的发展和完善中,目前有如下子项目:
(1)hadoop-obs项目:基于华为云OBS存储服务实现了hadoop文件系统抽象;
(2)flink-obs项目:基于华为云OBS存储服务实现了Flink文件系统抽象;
2.OBSA官方文档:https://support.huaweicloud.com/bestpractice-obs/obs_05_1501.html
hadoop-obs原理和实践建议
简述
1.hadoop-obs项目基于OBS并行文件系统服务/对象存储服务实现了hadoop的FileSystem抽象(即HDFS协议)OBSFileSystem,可以像使用 HDFS分布式文件系统一样访问OBS中的数据,实现大数据计算引擎Spark、MapReduce、Hive等与OBS存储服务的对接,为大数据计算提供“数据湖”存储。
2.OBSFileSystem继承实现了FileSystem抽象类,适配为对OBS http/https rest API接口的访问,下述章节将详细剖析OBSFileSystem的实现和实践。
3.hadoop-obs以jar包的形式对外发布,hadoop-huaweicloud-x.x.x-hw-y.jar包含义:前三位x.x.x为配套hadoop版本号;最后一位y为hadoop-obs版本号;如:hadoop-huaweicloud-3.1.1-hw-40.jar,3.1.1是配套hadoop版本号,40是hadoop-obs的版本号。
认证和鉴权机制
在了解OBSFileSystem的认证和鉴权机制之前,我们先对OBS服务的认证和鉴权机制做一个简单的介绍。其主要支持两种认证鉴权机制:
1.桶策略:桶拥有者通过桶策略可为IAM用户或其他帐号授权桶及桶内对象精确的操作权限,桶策略有20KB的大小限制,超出此限制可以选择IAM策略
2.IAM策略:IAM权限是作用于云资源的,IAM权限定义了允许和拒绝的访问操作,以此实现云资源权限访问控制
不管上述哪种机制,访问OBS时均需要IAM用户对应的永久aksk或是临时aksk(其包含ak,sk,securityToken三部分,其是有时效限制的,一般为24小时)
在通过OBSFileSystem访问OBS时首先需要配置永久aksk或是临时aksk,OBSFileSystem支持如下几种方式获取aksk:(优先级由高到低排序)
1.从core-site配置文件中获取:通过fs.obs.access.key和fs.obs.secret.key和fs.obs.session.token配置项获取。其支持hadoop的CredentialProvider机制,即通过CredentialProvider机制对aksk进行保护,避免aksk的明文暴露,注意不能将其保存在OBSFileSystem存储系统的路径上因为循环依赖问题https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html
附:关于CredentialProvider机制相关配置项:
hadoop.security.credential.provider.path:存放机密信息的keystore文件路径,例如aksk可以存储在其中
hadoop.security.credential.clear-text-fallback:当从keystore文件中获取不到机密信息时回落到配置项的明文中去获取hadoop.security.credstore.java-keystore-provider.password-file:keystore被加密时,其密码文件的路径
2.从URL中获取:其格式为obs://{ak}:{sk}@obs-bucket/
3.从Provider中获取:自定义aksk提供器,通过fs.obs.security.provider配置项进行配置Provider需要继承com.obs.services.IObsCredentialsProvider接口,目前支持的Provider:
(1)com.obs.services.EnvironmentVariableObsCredentialsProvider:从环境变量里寻找aksk,需要在环境变量中定义OBS_ACCESS_KEY_ID和OBS_SECRET_ACCESS_KEY分别代表永久的AK和SK
(2)com.obs.services.EcsObsCredentialsProvider:从ECS元数据中自动获取临时aksk并进行定期自动刷新
(3)com.obs.services.OBSCredentialsProviderChain:以链式的形式依次从环境变量,ECS服务器上进行搜索以获取对应的访问密钥,且会以第一组成功获取到的访问密钥访问obs
也可以自定义Provider完成符合您架构和安全要求的实现。
(MRS和DLI等华为云服务有自己的provider实现)
注意事项:
(1)对于类似mapreduce的分布式任务,因为分布式任务通过OBSFileSystem访问OBS且分布式任务被不确定的分配到集群节点上,所以需要能在集群的每一个节点上都能够获取aksk,例如如果通过EnvironmentVariableObsCredentialsProvider方式获取,则需要在每一个节点上都进行环境变量设置
(2)当通过临时aksk机制访问OBS时注意临时aksk的时效性
(3)注意EcsObsCredentialsProvider机制中访问ECS元数据时的流控,即访问ECS元数据获取aksk是有频次限制的
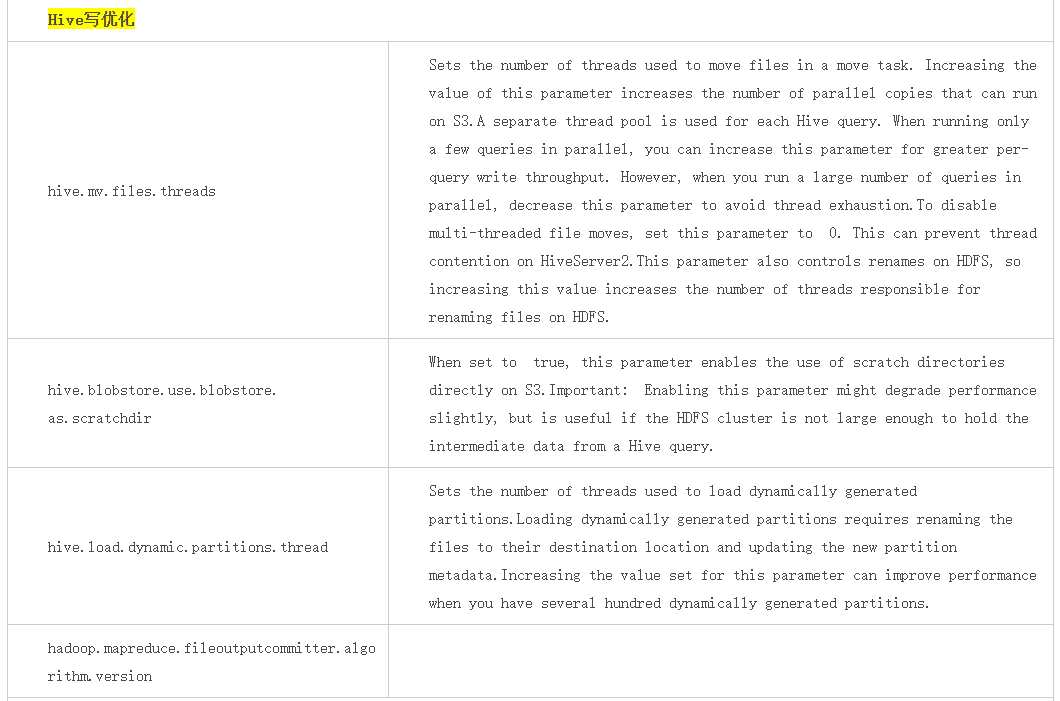
写相关流程
覆盖写
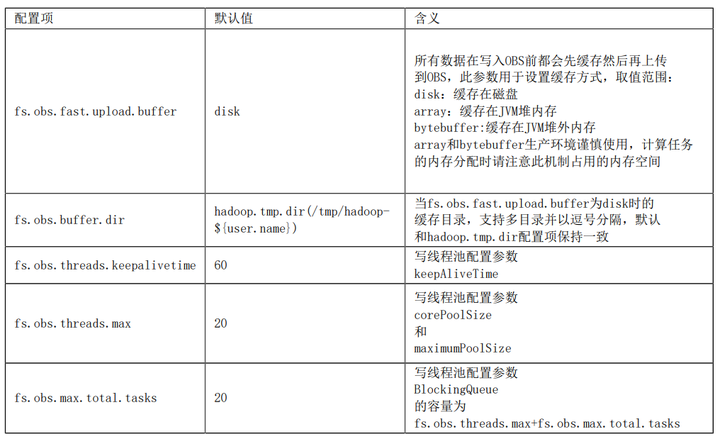
当调用OBSFileSystem的create相关方法时将获取FSDataOutputStream,通过该流写数据到OBS中。此流程总的实现思路是通过“缓存”和“并发多段上传”来实现较高的写性能:
(1)通过FSDataOutputStream写入数据时,数据首先将被缓存然后并发多段上传到OBS
(2)通过参数fs.obs.multipart.size设置缓存的大小,当数据写入量达到此阈值时将对应产生一次range上传请求,且是异步发起的range上传请求,当异步range上传任务完成时将及时清理其对应的缓存,例如当缓存机制为disk时,将及时清理本地磁盘中的缓存文件;
(3)当调用FSDataOutputStream的close方法时将等待所有的range上传异步任务完成,并发起多段合并请求完成文件的真正写入;并发多段上传线程池相关配置参数:
附obs java sdk 多段上传:https://support.huaweicloud.com/sdk-java-devg-obs/obs_21_0607.html
实践建议:
(1)当缓存fs.obs.fast.upload.buffer设置为disk时(默认),建议使用高性能存储介质(例如SSD盘)承载,且当集群中有大量并行任务时,确保缓存盘的空间足够(可以配置多个目录)
(2)当缓存fs.obs.fast.upload.buffer设置为array或bytebuffer时,生产环境谨慎使用,计算任务的内存分配时请注意此机制占用的内存空间
追加写
当调用OBSFileSystem的append方法时将获取FSDataOutputStream,通过该流追加写数据到OBS中,其依赖于OBS服务的追加写特性:
(1)通过流write数据时当达到缓存阈值fs.obs.multipart.size时将立刻写入数据到OBS;
(2)OBS的追加写特性不支持“并发range追加写”,所以其失去了“并发range写”的优势,相对覆盖写性能将会有所下降;
(3)OBS的追加写特性在频繁小数据追加写的场景其性能表现并不是很好
flush/hflush/hsync/sync
OBSFileSystem的create或是append相关方法将返回FSDataOutputStream,其实现了flush/hflush/hsync/sync等相关方法。
文件桶场景:

对象桶场景:

注意:hadoop-obs 46版本才开始支持fs.obs.outputstream.hflush.policy策略,之前的版本实现机制等同于fs.obs.outputstream.hflush.policy=Sync的行为。
截断
OBSFileSystem真正实现了FileSystem定义的截断接口truncate,其依赖于OBS文件桶的截断特性。
(1)此接口将可以很好的支撑flink的StreamingFileSink的exactly once场景或是其他场景
(2)普通对象桶不具备截断特性;
读相关流程
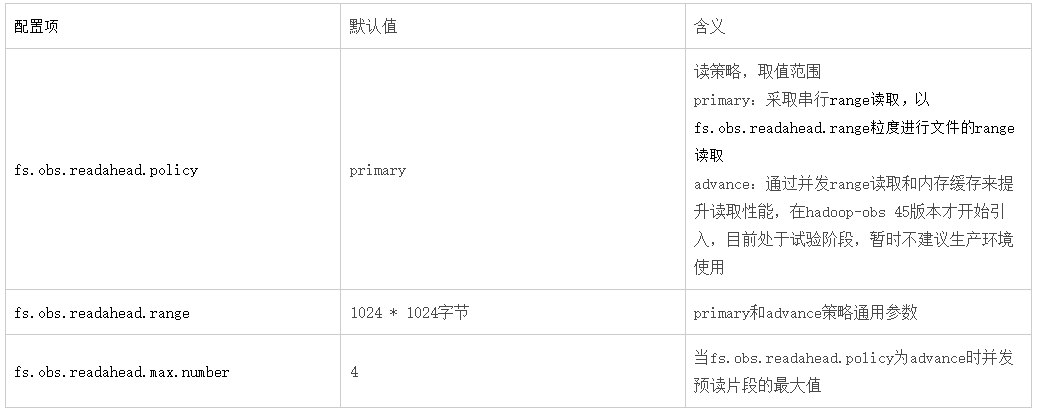
当调用OBSFileSystem的open相关方法时将获取FSDataInputStream,通过该流读取OBS中的数据。此流程总的实现思路是通过obs的“range读取”特性进行实现,相关配置项如下:
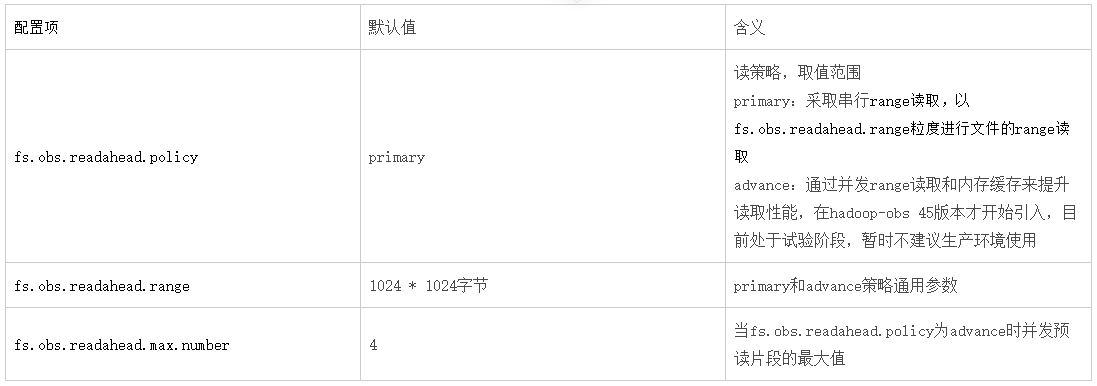
附OBS range读:当读取一个较大的文件时例如1000MB,可以将其分为0-100MB,100MB-200MB。。。10个段并发读取以提升性能。https://support.huaweicloud.com/sdk-java-devg-obs/obs_21_0703.html
实践建议:
(1)对于需要顺序读取文件的场景:例如hdfs命令下载文件,DistCp,sql查询文本文件
- 在primary策略下:可以大幅度提高fs.obs.readahead.range的值(默认1MB),例如可以设置为100MB
例如hadoop fs -Dfs.obs.readahead.range=104857600 -get obs://obs-bucket/xxx
- 在advance策略下:可以适度提高fs.obs.readahead.range和fs.obs.readahead.max.number的值或是保持默认值不变
(2)对于大量随机访问的场景:例如orc或parquet文件读取
在primary策略和advance策略下均保持默认值即可,或是针对你的场景进行调优测试。
list相关流程
因为对象存储的特点,其逻辑模型是KV模型,因此其list操作是耗时的,其每次最多只能返回1000条数据,类似分页查询。因此在超大目录场景,OBSFileSystem中的listXXX接口其性能是相对低的,因为其要发起多次list请求才能获取完整的列表。
并行文件桶场景下OBSFileSystem对于list的优化:
1.根据目录结构尝试并发list。
2.例如当要列举A目录时,A目录下有B,C,D目录,将会并发列举B,C,D目录以提升列举性能。

实践建议:
1.对于超大目录的list或是getContentSummary(即hdfs du命令):
(1)不要在前台列举或是du一个超大目录
(2)可以精确到某一个分区目录以避免超大目录场景下前台进行列举或是du操作时出现的长时间等待
删除相关流程
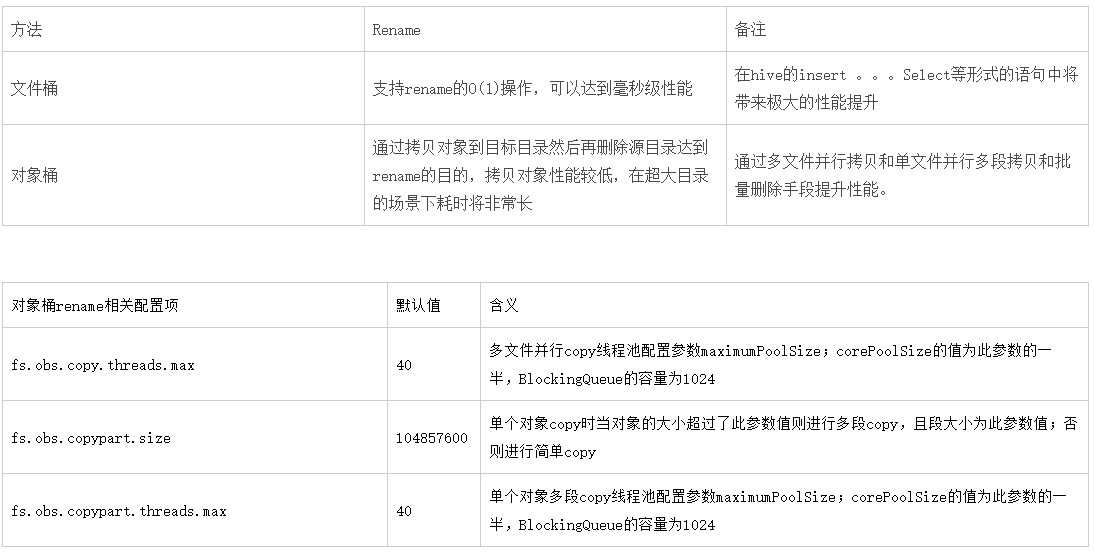
目录删除操作在OBSFileSystem中不是O(1)操作,其实现分为两个步骤:
1.先递归列举出目录下的所有文件
2.利用对象存储的批量删除特性将其删除,批量删除的最大条数1000,对于文件桶必须先删除目录下的文件才能删除父目录
hadoop-obs的快速删除机制:即将删除操作转为rename操作,rename到指定目录,目的是利用文件桶rename的高效性解决删除性能

实践建议:
1.对于超大目录的删除:建议可以采用OBS服务的生命周期特性,通过OBS后台任务进行删除。
2.快速删除机制:开启后需要配合OBS服务的生命周期特性,定期删除fs.obs.trash.dir目录中的数据
rename相关流程
垃圾回收机制
在大数据应用场景中,往往存在防止数据误删除的诉求,通过OBSFileSystem的垃圾回收机制实现。
1.在相关组件的core-site.xml文件中配置如下内容:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>垃圾回收机制开关,设置为大于0 的值即可</description>
</property>
2.配置OBS服务的生命周期策略:垃圾目录中的文件无法自动清除,需通过OBS生命周期策略进行定期清除
3.场景:
(1)hdfs命令:
hadoop fs -rm obs://obs-bucket/test.txt;
会将test目录转移到obs://obs-bucket/user/${username}/.Trash/Current垃圾目录下
(2)hive语句:
drop table obstable;
如果obstable是一张内表,会将obstable表对应的目录转移到obs://obs-bucket/user/${username}/.Trash/Current垃圾目录下
日志机制
1.hadoop-obs项目对应的jar包放置于hadoop,hive,spark等组件的目录下,受这些组件的日志机制控制;例如对于hadoop组件,在${HADOOP_HOME}/etc/hadoop/log4j.properties文件中增加如下配置项以避免产生大量info级别的日志:
log4j.logger.com.obs=ERROR或是WARN
log4j.logger.org.apache.hadoop.fs.obs=INFO
2.关于warn级别的404状态码:OBSFileSystem在实现一些FileSystem的接口时为了语义的准确实现,在一些流程中会去探测文件是否存在,例如在实现create接口时会先获取文件的状态用以判断是文件还是目录,当为目录时则抛出异常,当为文件或是文件不存在时则正常创建文件,在此过程中会打印warn级别的带404状态码的日志(当日志级别调整为info或是warn时),此warn级别的日志属于正常现象。
重试机制
1.访问OBS服务时可能会因为网络短暂抖动,服务突发故障,服务突发流控等瞬时故障导致访问失败,hadoop-obs为了应对上述瞬时故障进行了必要的重试机制;
注:对于OBS服务处于长期故障状态重试机制是无力解决的
2.重试策略:采取退让重试策略,即随着失败次数的增加重试间隔梯次增加
1.hadoop-obs的通用重试策略:
fs.obs.retry.maxtime:默认值180000ms,控制最大重试时间,重试间隔为max(fs.obs.retry.sleep.basetime*2的重试次数次方,fs.obs.retry.sleep.maxtime)
fs.obs.retry.sleep.basetime:默认值50ms,重试间隔的基数
fs.obs.retry.sleep.maxtime:默认值30000ms,重试间隔最大等待时间 2.hadoop-obs的流控重试策略:您可视您的业务情况独立配置
fs.obs.retry.qos.maxtime:默认值180000ms
fs.obs.retry.qos.sleep.basetime:默认值1000ms
fs.obs.retry.qos.sleep.maxtime:默认值30000ms 3.什么情况下会进行重试:
(1)尚未与obs服务建立连接或是IO中断,例如ConnectException,SocketTimeoutException等
(2)obs服务返回5xx:obs服务指示服务状态不正常 注:
(1)50.1版本开始才实现了独立的流控重试策略
(2)50.1版本开始写入流程才被施加重试机制
flink-obs原理和实践建议(待完善)
大数据各组件优化



其他
OBS 带宽评估
在基于OBS的大数据存算分离解决方案中OBS侧QOS(主要是读写带宽)的评估没有一个准确的计算公式,也因业务场景的复杂性导致难有一个一以贯之的公式。根据经验和理论的沉淀现阶段能够采用的OBS QOS评估方法如下:
算法一:根据CPU核数估算
此算法的依据是现网观察后的经验估算。

算法二:根据POC估算
此算法的依据是根据客户在POC测试时的真实业务场景观测到的OBS侧的实际带宽消耗峰值,然后依据计算集群的规模进行推算。
例如:POC时搭建了10个计算节点,对OBS的读带宽需求峰值能达到200Gb,写带宽需求峰值能达到15Gb;
商用时需要搭建120个计算节点,OBS的读带宽=200Gb/8*(120/10)=300GB; OBS的读带宽=15Gb/8*(120/10)=22.5GB;
HDFS-OBS映射
通过HDFS地址映射到OBS地址的方式,支持将HDFS中的数据迁移到OBS后,不需要变动业务逻辑中的数据地址,即可完成数据访问。
https://support.huaweicloud.com/usermanual-mrs/mrs_01_0769.html
附:hadoop-obs约束与限制
hadoop-obs不支持以下HDFS语义:
- Lease
- Symbolic link operations
- Proxy users
- File concat
- File checksum
- File replication factor
- Extended Attributes(XAttrs) operations
- Snapshot operations
- Storage policy
- Quota
- POSIX ACL
- Delegation token operations
附:hadoop-obs常见问题
0.大数据场景强烈建议使用并行文件系统,即文件桶
1.hadoop-obs性能基准测试
可以通过开源的DFSIO和NNbench基准测试工具进行大数据场景的性能基准测试
注:OBS服务是基于HDD存储介质,请不要和基于ssd的HDFS服务进行性能对比
2.OBS服务流控问题
(1)每个region可以独立设置租户级别和桶级别的流控阈值
(2)OBS服务流控相关阈值:主要包含读写带宽Gb/s,读写TPS,并发连接数三个阈值
(3)流控准则:
当达到带宽/TPS阈值时HTTP请求依然会成功返回200状态码,但访问时延会增大;
当达到并发连接数阈值时OBS服务将拒绝访问返503/GetQosTokenException

3.hadoop-obs权限问题
通过hadoop-obs访问OBS时需要aksk/临时aksk才能访问OBS服务,OBSFileSystem支持如下几种方式获取aksk:(优先级由高到低排序)
- (1)通过core-site.xml的fs.obs.access.key和fs.obs.secret.key和fs.obs.session.token配置项获取。 其支持hadoop的CredentialProvider机制,即通过CredentialProvider机制对aksk进行保护,避免aksk的明文暴露
- (2)从provider中获取:自定义aksk提供器,通过fs.obs.security.provider配置项进行配置。 provider实现需要继承com.obs.services.IObsCredentialsProvider接口,目前hadoop-obs内置的provider如下: com.obs.services.EnvironmentVariableObsCredentialsProvider:从环境变量里寻找aksk,需要在环境变量中定义OBS_ACCESS_KEY_ID和OBS_SECRET_ACCESS_KEY分别代表永久的AK和SK
- com.obs.services.EcsObsCredentialsProvider:从ECS元数据中自动获取临时aksk并进行定期自动刷新 com.obs.services.OBSCredentialsProviderChain:以链式的形式依次从环境变量,ECS服务器上进行搜索以获取对应的访问密钥,且会以第一组成功获取到的访问密钥访问obs 也可以自定义provider实现完成符合您架构和安全要求的实现,例如MRS服务提供了自己的provider实现
4.写入操作缓存盘注意事项
当通过hadoop-obs写数据到obs时,其通过缓存机制提升写入性能,当缓存介质fs.obs.fast.upload.buffer设置为disk时(默认),可以通过fs.obs.buffer.dir配置项设置缓存目录(默认与hadoop.tmp.dir相同目录),可以设置多目录以逗号分隔;建议使用高性能存储介质(例如SSD盘)承载,且当集群中有大量并行任务时,确保缓存盘的空间足够(可以配置多个目录)

5.读取操作实践建议:
(1)对于需要顺序读取文件的场景:例如hdfs命令下载文件,DistCp,sql查询文本文件
- 在primary策略下:可以大幅度提高fs.obs.readahead.range的值(默认1MB),例如可以设置为100MB
例如hadoop fs -Dfs.obs.readahead.range=104857600 -get obs://obs-bucket/xxx - 在advance策略下:可以适度提高fs.obs.readahead.range和fs.obs.readahead.max.number的值或是保持默认值不变
(2)对于大量随机访问的场景:例如orc或parquet文件读取
在primary策略和advance策略下均保持默认值即可,或是针对你的场景进行调优测试。
6.快速删除特性实践建议
因为hadoop-obs的删除操作不是O(1)操作,其操作耗时和目录大小成正比例,即随着目录结构的增大其操作耗时将持续增长;如果您的应用场景存在频繁的删除操作,且删除的是超大目录,建议可以开启快速删除特性。相关配置项:

注:文件桶才支持快速删除特性,普通对象桶不支持,因为快速删除是利用文件桶的rename性能优势实现的
注:快速删除开启后需要配合OBS服务的生命周期特性,定期删除fs.obs.trash.dir目录中的数据
7.OBS服务监控
通过华为云的云监控服务CES,其是华为云资源的监控平台,提供了实时监控、及时告警、资源分组、站点监控等能力。
8.问题排查
通过客户端日志和服务端日志进行问题排查,通常以客户端日志为问题排查的优先手段。
(1)客户端日志: OBS服务两层返回码用于指示访问状态: 状态码:符合HTTP规范的HTTP状态码,例如2xx,4xx,5xx 错误码:在状态码之下又细分了错误码,例如403状态码/InvalidAccessKeyId错误码表示 注:错误码描述https://support.huaweicloud.com/api-obs/obs_04_0115.html
(2)服务端日志:开启桶日志功能,OBS会自动对这个桶的访问请求记录日志,并生成日志文件写入用户指定的桶中,可用于进行请求分析或日志审计 6.问题反馈渠道 华为云工单系统
9.跨云访问obs问题(待完善)
附:hadoop-obs完整配置项
见https://clouddevops.huawei.com/domains/2301/wiki/8/WIKI2021080300343
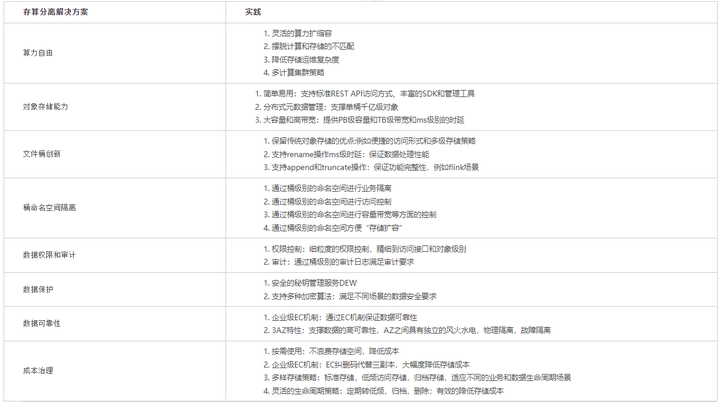
附:存算分离解决方案
8000字讲透OBSA原理与应用实践的更多相关文章
- 终于有人把Elasticsearch原理讲透了!
终于有人把Elasticsearch原理讲透了! http://developer.51cto.com/art/201904/594615.htm 小史是一个非科班的程序员,虽然学的是电子专业,但是通 ...
- (转)终于有人把Elasticsearch原理讲透了!
终于有人把Elasticsearch原理讲透了! 小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了. 来源:互联网侦察 | 2019-04-08 ...
- 终于有人把O2O、C2C、B2B、B2C的区别讲透了!
终于有人把O2O.C2C.B2B.B2C的区别讲透了! 一.O2O.C2C.B2B.B2C的区别在哪里? O2O是online to offline分为四种运营模式: 1.online to offl ...
- 视频透雾原理加视频增强Retinex算法介绍
(本文转自:http://www.syphong.cn/52-1.html#) 视频透雾原理加视频增强Retinex算法介绍 -上海凯视力成 钟建军 一. 视频增强的背景 视觉信息是人类获得外界信息的 ...
- Tengine HTTPS原理解析、实践与调试【转】
本文邀请阿里云CDN HTTPS技术专家金九,分享Tengine的一些HTTPS实践经验.内容主要有四个方面:HTTPS趋势.HTTPS基础.HTTPS实践.HTTPS调试. 一.HTTPS趋势 这一 ...
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- Android端代码染色原理及技术实践
导读 高德地图开放平台产品不断迭代,代码逻辑越来越复杂,现有的测试流程不能保证完全覆盖所有业务代码,测试不到的代码及分支,会存在一定的风险.为了保证测试全面覆盖,需要引入代码覆盖率做为测试指标,需要对 ...
- Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结
Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结 1. 什么是可扩展的应用程序?1 2. 松耦合(ioc)2 3. 接口的思考 2 4. 单一用途&模块化,小粒度化2 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
随机推荐
- git 本地项目关联新repo
git initgit remote add origin repo-url git pull origin master --allow-unrelated-histories git add . ...
- MySQL体系结构与数据类型
layout: post title: "MySQL体系结构与数据类型" date: 2018-02-26 categories: MySQL tags: MySQL 一.MySQ ...
- Zookeeper安装学习(二)
学习内容:Zookeeper集群安装(Zookeeper版本:Zookeeper3.5.7:注:master,s1,s2都需要部署) 解压安装: (1)在主机 master 解压 Zookeeper ...
- [C++STL] vector 容器的入门
vector容器的入门 #include<vector> 创建vector容器的几种方式 数据类型可以是结构体,也能是另外一个容器 vector 的初始化: (1) 创建并声明大小 vec ...
- df-查看磁盘目录空间大小
查看磁盘分区挂载情况. 语法 df [option] 选项 -T 显示文件系统类型. -h 带单位显示. 示例 [root@localhost ~]# df -Th Filesystem Type S ...
- Vue2-Slot插槽使用
Slot插槽 父组件向子组件传递 父组件将内容分发到子组件 slot插槽的值只读,不能在子组件中修改 slot插槽也可以作为组件之间的通信方式 默认插槽 父组件中:使用Son组件 <templa ...
- MySQL之SQL语句优化
语句优化 即优化器利用自身的优化器来对我们写的SQL进行优化,然后再将其放入InnoDB引擎中执行. 条件简化 移除不必要的括号 select * from x where ((a = 5)); 上面 ...
- Es6语法+v-on参数相关+vue虚拟dom
Es6的语法 Es5:if和for 都没有块级作用域,函数function有作用域. Es6:加入let使得if和for有作用域 .建议: 在Es6中优先使用const,只有需要改变某一个标识符的时候 ...
- HDD线上沙龙·创新开发专场:多元服务融合,助力应用创新开发
5月24日,由华为开发者联盟主办的HUAWEI Developer Day(华为开发者日,简称HDD)线上沙龙·创新开发专场在华为开发者学堂及各大直播平台与广大开发者见面.直播内容主要聚焦Harmon ...
- C++:制作火把
制作火把 时间限制 : 1.000 sec 内存限制 : 128 MB 题目描述: 小红最近在玩一个制作火把的游戏,一开始,小红手里有一根木棍,她希望能够通过这一根木棍通过交易换取制 ...