中文乱码?不,是 HTML 实体编码!
When question comes
在 如何用 Nodejs 分析一个简单页面 一文中,我们爬取了博客园首页的 20 篇文章标题,输出部分拼接了一个字符串:
var $ = cheerio.load(sres.text);
var ans = '';
$('.titlelnk').each(function (index, item) {
var $item = $(item);
ans += $item.html() + '<br/><br/>';
});
// 将内容呈现到页面
res.send(ans);页面呈现良好:

但是查看网页源代码,却看到这样的情景:

什么鬼?我们让问题再清晰些,试着把爬虫代码稍做修改:
var $ = cheerio.load(sres.text);
var ans = [];
$('.titlelnk').each(function (index, item) {
var $item = $(item);
ans.push($item.html());
});
// 将内容呈现到页面
res.send(ans);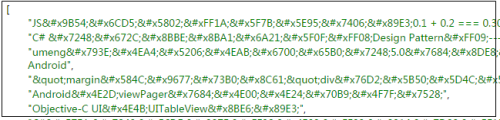
这输出的是什么玩意儿?
乱码?不,是 HTML 实体编码!
HTML 实体编码
在 HTML 中,某些字符是预留的,比如不能使用小于号(<)和大于号(>),这是因为浏览器会误认为它们是标签。如果希望正确地显示预留字符,我们必须在 HTML 源代码中使用字符实体(character entities)。当然还另一个重要原因,有些字符在 ASCII 字符集中没有定义,因此需要使用字符实体来表示,比如中文。
字符实体类似这样:
&entity_name;
或者
&#entity_number;如需显示小于号,我们必须这样写:< 或 <。前者(实体名)易于记忆,而后者(实体数字)在浏览器中的支持较好。
HTML 中常见的需要替换成字符实体的字符有 4 个,分别是 <、>、& 以及 "。为此,我们可以简单写个 escapeHTML 函数(使得网页上可以正确显示这 4 个字符,而不会被误认为是标签):
function escapeHTML(text) {
var replacements= {"<": "<", ">": ">","&": "&", """: """};
return text.replace(/[<>&"]/g, function(character) {
return replacements[character];
});
}更多关于 HTML 实体编码的内容可以参考 HTML 字符实体
Solution
不仅是 "<" ">" 这样的能编码,所有字符均能编码,这也是出现 "乱码" 的原因。在文章开头的例子中,其实它把该 target 标签内的所有东西(包括中文)都给编码了。
而最开始的代码(字符串输出)之所以没有 "乱码",完全是因为浏览器自动帮你解码了。(如果存在于 HTML 代码中,会被自动解码)
知道了原因,我们可以从两个方向解决问题。
首先,我们可以不对其内容进行编码。用 text() 方法取代 html() 方法:
$('.titlelnk').each(function (index, item) {
var $item = $(item);
ans.push($item.text());
});很简单并且完美地解决了这个问题。
或者我们关闭 cheerio 中的 .html() 方法 转换实体编码的功能(2016-01-25 add):
var $ = cheerio.load(sres.text, {decodeEntities: false});
$('.titlelnk').each(function (index, item) {
var $item = $(item);
console.log($item.html());
});如果说不能从编码的角度解决,我们可以试着解码。
方法一:
创建空标签,将编码内容用 html() 方法塞入,用 text() 取出,转换过程让第三方完成(当然前提是获取了 $ 对象):
function htmlDecode(str) {
var t = $("<div></div>");
t.html(str);
return t.text();
}
var $ = cheerio.load(sres.text);
var ans = [];
$('.titlelnk').each(function (index, item) {
var $item = $(item);
ans.push(htmlDecode($item.html()));
});
// 将内容呈现到页面
res.send(ans);方法二:
根据编码转换规则,用正则 decode:
function htmlDecode(str) {
// 一般可以先转换为标准 unicode 格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时)
str = unescape(str.replace(/\\u/g, "%u"));
// 再对实体符进行转义
// 有 x 则表示是16进制,$1 就是匹配是否有 x,$2 就是匹配出的第二个括号捕获到的内容,将 $2 以对应进制表示转换
str = str.replace(/&#(x)?(\w+);/g, function($, $1, $2) {
return String.fromCharCode(parseInt($2, $1? 16: 10));
});
return str;
}
var $ = cheerio.load(sres.text);
var ans = [];
$('.titlelnk').each(function (index, item) {
var $item = $(item);
ans.push(htmlDecode($item.html()));
});
// 将内容呈现到页面
res.send(ans);Encode & Decode
事情到此似乎可以告一段落,我们找到了问题的原因,也找到了解决办法。但是,HTML 实体编码,它到底是如何编码的?
我们任意取一条标题:
前端备忘录 — IE 的条件注释编码后为:
前端备忘录 — IE 的条件注释中文的编码结果开头都是 &#x。试着用 charCodeAt() 取得 "前" 字的 unicode 编码大小,然后将它转成 16 进制,正是 524d !看来和 escape() 相似,又是一次十六进制的转换。
但是英文却没有被转,这点和 escape() 也神似。唯一不同的是 escape 会将空格转为 %20,而 HTML 编码并没有。
而且 HTML 编码甚至会将   自动编码成  ,这也就意味着如果要手写个 HTML 编码函数,需要将所有字符实体的映射都找出来,而且对于 &XXXX 形式的,似乎还要作个校验(确认是实体集还是普通的字符串)。
而 HTML 解码则相对来说简单写,只需将 &#xXXX 进行转换,详细代码可以参考 Solution 一节的正则。
事实上,HTML 编码并不一定要转成十六进制,十进制也可以。还是以 "前" 为例,它的十进制 unicode 码为 21069,完全可以用 前 来代替 前。
最后还有两个客户端的编码、解码函数:
function HtmlEncode(str) {
var t = document.createElement("div");
t.textContent ? t.textContent = str : t.innerText = str;
return t.innerHTML;
}
function HtmlDecode(str) {
var t = document.createElement("div");
t.innerHTML = str;
return t.textContent || t.innerText;
}真的是吃一堑长一智,以后碰到 "&#x" 开头的一些编码,十有八九是 HTML 的实体编码,再也不用担心了!
Read More:
中文乱码?不,是 HTML 实体编码!的更多相关文章
- 服务器返回中文乱码的情况(UTF8编码 -> 转化为 SYSTEM_LOCALE 编码)
服务器乱码 转换使用如下方法 入惨{“msg”} -> utf8编码 -> 转化为 SYSTEM_LOCALE 编码 -> 接受转换后的参数 "sEncoding" ...
- 程序写入mycat中文乱码解决(也包括mysql编码修改)
乱码问题可能出现的三个地方 1.程序连接的编码要设置 jdbc:mysql://192.168.1.1:8066/TESTDB?useUnicode=true&characterEncodin ...
- centos中文乱码修改字符编码使用centos支持中文
如何你的centos显示中文乱码,只要修改字符编码使centos支持中文就可以了,没有这个文件可以创建它,下面是修改步骤 一.中文支持 安装中文语言包: 复制代码 代码如下: yum groupins ...
- python基础系列教程——Python中的编码问题,中文乱码问题
python基础系列教程——Python中的编码问题,中文乱码问题 如果不声明编码,则中文会报错,即使是注释也会报错. # -*- coding: UTF-8 -*- 或者 #coding=utf-8 ...
- 转:jsp页面显示中文乱码解决方案
jsp页面显示中文乱码: jsp页面的编码方式有两个地方需要设置: <%@ page language="java" import="java.util.*&quo ...
- JSP页面的中文乱码
jsp页面显示中文乱码: jsp页面的编码方式有两个地方需要设置: <%@ page language="java" import="java.util. ...
- PHP+MySQL存储数据出现中文乱码的问题
PHP+MySQL出现中文乱码的原因: 1. MYSQL数据库的编码是utf8,与PHP网页的编码格式不一致,就会造成MYSQL中的中文乱码. 2. 使用MYSQL中创建表.或者选择字段时设置的类型不 ...
- 中文乱码的分析 和 从Eclipse设置启动JVM时的字符集(转)
最近时常碰到中文乱码的问题,eclipse的编码环境设置的都是UTF-8,外部也是以UTF-8的编码进行传参的,但是遇到中文的时候还是因为乱码而产生一系列的错误.在网上查了许多资料,发现这是跟JVM的 ...
- Filezilla出现中文乱码
使用Filezilla client FTP客户端登陆某些FTP站点会出现中文乱码,原因是FTP服务器端编码与filezilla client端编码不一致造成的,解决方法如下:文件-站点管理-选中要登 ...
- filezilla里怎么解决中文乱码问题
使用Filezilla client FTP客户端登陆某些FTP站点会出现中文乱码,原因是FTP服务器端编码与filezilla client端编码不一致造成的.解决方法如下:文件-站点管理-选中要登 ...
随机推荐
- 1-1 gulp 实战
npm install gulp-htmlmin gulp-imagemin imagemin-pngcrush gulp-minify-css gulp-jshint gulp-uglify gul ...
- iOS UISearchController的使用
在iOS9中,UISearchDisplayController 已经被UISearchController替代.搜索框是一种常用的控件. 假设我们要满足下图的需求,产生100个“数字+三个随机字母” ...
- centos 7 64位虚机上android4环境运行
场景 现在的开发大多是在linux的虚拟机上进行,现在有些工作和android有关,因此初步尝试了一下是否可以和目前的场景进行统一. 系统是在vmware workstaion上的centos 7的6 ...
- 自己实现苹果安装app动画
最近在学习CALayer相关动画,然后某一天突然发现苹果安装app这动画就很不错啊,所以就想自己实现下. 具体效果如图: 还是不试不知道一试吓一跳啊,这看上去简单的动画没我想象的那么简单. 首先这个动 ...
- yii2批量添加的问题
作者:白狼 出处:http://www.manks.top/yii2_batch_insert.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否 ...
- crontab不执行perl脚本分析
在新装的Linux服务器上部署了一个作业监控磁盘空间并提前告警,在shell脚本里面调用了一个perl脚本发送告警邮件.结果出现了一个很奇怪的现象:如果手工执行该脚本/home/oracle/scri ...
- 解决session阻塞的问题
简介 对于数据库运维人员来说创建session或者查询时产生问题是常规情况,下面介绍一种很有效且不借助第三方工具的方式来解决类似问题. 最近开始接触运维工作,所以自己总结一些方案便于不懂数据库的同事解 ...
- linux top 源码分析
/* * Copyright (c) 2008, The Android Open Source Project * All rights reserved. * * Redistribution a ...
- Spark调度管理(读书笔记)
Spark调度管理(读书笔记) 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark调度管理 本文主要介绍在单个任务内Spark的调度管理,Spark调度相关概念如 ...
- android 获取应用的当前版本号&获取当前android系统的版本号
(转自:http://www.cnblogs.com/qsl568/archive/2012/03/14/2395636.html) 获取当前应用的版本号: private String getVer ...