elasticSearch(四)--结构化查询
结构化查询
1、请求体查询
GET(POST) /_search
POST /_search
{
"from": 30,
"size": 10
}
2、DSL
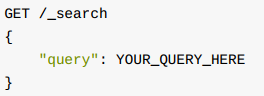
使用结构化查询, 你需要传递 query 参数:

3、合并多子句
查询子句就像是搭积木一样, 可以合并简单的子句为一个复杂的查询语句, 比如:
叶子子句(leaf clauses)(比如 match 子句)用以在将查询字符串与一个字段(或多字段)进行比较
复合子句(compound)用以合并其他的子句。 例如, bool 子句允许你合并其他的合法子句, must , must_not 或者 should

4、查询与过滤
结构化查询( Query DSL) 和结构化过滤( Filter DSL) 。 查询与过滤语句非常相似, 但是它们由于使用目的不同而稍有差异
5、最重要的查询过滤语句
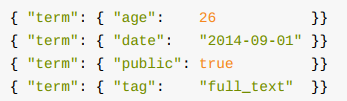
term过滤:主要用于精确匹配哪些值,如数字,布尔,日期,未进行分词的字符串
terms过滤:与term类似,terms允许有多个匹配条件。

range过滤:允许指定范围匹配。

exists和missing过滤:exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段, 类似于SQL语句中的 IS_NULL 条件

bool过滤:
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑, 它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and 。
must_not :: 多个查询条件的相反匹配, 相当于 not 。
should :: 至少有一个查询条件匹配, 相当于 or 。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:

match_all查询:
使用 match_all 可以查询到所有文档, 是没有查询条件下的默认语句

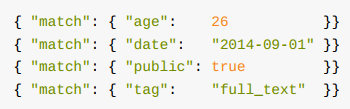
match查询:
match 查询是一个标准查询, 不管你需要全文本查询还是精确查询基本上都要用到它。如果你使用 match 查询一个全文本字段,
它会在真正查询之前用分析器先分析 match 一下查询字符

如果用 match 下指定了一个确切值, 在遇到数字, 日期, 布尔值或者 not_analyzed 的字符串时, 它将为你搜索你给定的值
multi_match查询:
multi_match 查询允许你做 match 查询的基础上同时搜索多个字段:

bool查询:
bool 查询与 bool 过滤相似, 用于合并多个查询子句。 不同的是, bool 过滤可以直接给出是否匹配成功, 而 bool 查询要计算每一个查询子句的 _score ( 相关性分值) 。
must :: 查询指定文档一定要被包含。
must_not :: 查询指定文档一定不要被包含。
should :: 查询指定文档, 有则可以为文档相关性加分。

6、带过滤的查询语句

7、验证查询
/megacorp/_validate/query?explain
显示查询过程

elasticSearch(四)--结构化查询的更多相关文章
- ElasticSearch(6)-结构化查询
引用:ElasticSearch权威指南 一.请求体查询 请求体查询 简单查询语句(lite)是一种有效的命令行_adhoc_查询.但是,如果你想要善用搜索,你必须使用请求体查询(request bo ...
- ElasticSearch 5学习(10)——结构化查询(包括新特性)
之前我们所有的查询都属于命令行查询,但是不利于复杂的查询,而且一般在项目开发中不使用命令行查询方式,只有在调试测试时使用简单命令行查询,但是,如果想要善用搜索,我们必须使用请求体查询(request ...
- ElasticSearch权威指南学习(结构化查询)
请求体查询 简单查询语句(lite)是一种有效的命令行adhoc查询.但是,如果你想要善用搜索,你必须使用请求体查询(request body search)API. 空查询 我们以最简单的 sear ...
- ElasticSearch 基本概念 and 索引操作 and 文档操作 and 批量操作 and 结构化查询 and 过滤查询
基本概念 索引: 类似于MySQL的表.索引的结构为全文搜索作准备,不存储原始的数据. 索引可以做分布式.每一个索引有一个或者多个分片 shard.每一个分片可以有多个副本 replica. 文档: ...
- elasticsearch结构化查询过滤语句-----4
1.之前三节讲述的都是索引结构及内容填充的部分,既然添加了数据那我们的目的无非就是增产改查crudp,我先来讲讲查询-----结构化查询 我们看上图截图两种方式: 1)第一种,在索引index5类型s ...
- elasticsearch 深入 —— 结构化搜索
结构化搜索 结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作.比较常见的操作 ...
- SQL结构化查询语句
SQL结构化查询语句 SQL定义了查询所有关系型数据库的规则. 1.通用语法 SQL语句可以单行或者多行书写,以分号结尾 可以使用空格和缩进增强可读性 不区分大小写,但是关键字建议大写 3种注释 注释 ...
- ElasticSearch常用结构化搜索
最近,需要用到ES的一些常用的结构化搜索命令,因此,看了一些官方的文档,学习了一下.结构化查询指的是查询那些具有内在结构的数据,比如日期.时间.数字都是结构化的. 它们都有精确的格式,我们可以对这些数 ...
- Elasticsearch系列---结构化搜索
概要 结构化搜索针对日期.时间.数字等结构化数据的搜索,它们有自己的格式,我们可以对它们进行范围,比较大小等逻辑操作,这些逻辑操作得到的结果非黑即白,要么符合条件在结果集里,要么不符合条件在结果集之外 ...
- (四) 结构化查询语言SQL——2
3)ORDER BY排序语句 通常,查询的结果是以无序的方式显示的,有时需要将查询结果按照一定次序来进行排序.ORDER BY就可以用上了,例如查询课程号为202的课程成绩的所有信息,并按照成绩降序排 ...
随机推荐
- Java内存分析利器——Eclipse Memory Analyzer工具的使用
一.如何下载Java程序的dump内存文件并离线导入到MemoryAnalyser工具进行分析 1.jps查看Java应用的pid jps 11584216168084 Launcher24792 ...
- Word15 财务部年度报告office真题
1.课程的讲解之前,先来对题目进行分析,首先需要在考生文件夹下,将Wrod素材.docx文件另存为Word.docx,后续操作均基于此文件,否则不得分. 2.这一步非常的简单,打开下载素材文件,在 ...
- Windows 下安装 Bun:像 Node 或 Deno 一样的现代 JavaScript 运行时
背景 最近前端工具链又火了一个项目 Bun,可以说内卷非常严重.Bun 是一个新的 JavaScript 运行时,内置了打包器.转译器.任务运行器和 npm 客户端. Bun 是像 Node 或 De ...
- shell实现接口初次失败告警,恢复也发送一次通知
1.该shell判断 第一次失败告警,接口恢复发送一次通知 参数:一个参数接口返回结果0 表示成功 1表示失败 脚本详情 [root@localhost bd]# more bd-new.sh #!/ ...
- MDK GCC调试
openocd调试 https://blog.csdn.net/chunyexixiaoyu/article/details/120448515
- 通过java代码向mysql数据库插入记录,中文乱码处理
处理步骤 修改mysql配置文件,并重启mysql服务.mysql默认配置文件路径为/etc/my.cnf. 修改配置如下: [mysqld] character-set-server=utf8 [c ...
- 关于Java中数组的简单使用
关于java中数组的简单使用--继java环境配置后的第二篇学习笔记 近期在学习Java的过程中学到了数组的部分,至于为什么我会到数组才来写这个,主要是数组这一章节的内容感觉还是与之前学的C里面的数组 ...
- python 操作 ES 一、基础操作
示例代码环境 python:3.8 es:7.8.0环境安装 pip install elasticsearch==7.8.0 from elasticsearch import Elasticsea ...
- BUU刷题记录
[GWCTF 2019]mypassword xss+csp 打开页面可以注册登录 登进去提示不是sql注入 然后提示源码 看一下 然后有段后端代码写道了注释里 <!-- if(is_array ...
- Vue 事件监听
事件监听 v-on 使用v-on进行事件绑定监听,回调函数写在methods中.可以使用@的这种简写形式来代替v-on,当事件源无参数传递时,可省略括号. 语法如下所示: <button @:事 ...