Efficient training of physics-informed neural networks via importance sampling


因为看着作者是英伟达的,便看了一下。总体感觉没有什么新意,改进幅度也很小,但是理论推导可以看一下。可以借鉴一下。
本文通过重要性采样对PINN进行高效计算,本文提出的方法很简单,也很直观,但效果提升有限。大概说一下,就是利用一个与损失函数成比例的分布,进行采样,再利用这个子集更新网络参数。最后为了减少计算量,提出了一个分段常数近似(利用最近邻算法)。
一开始,作者提到,目前在PINN中,常使用的mini-SGD,其中由于小批量的选取服从均匀分布,所以会导致对解的收敛产生阻碍影响,因为,有可能很少或者几乎没有梯度信息被获取,这将会阻碍收敛。因此,作者认为通过重要性采样,选取一组合适的配置点可以加速收敛。目前,根据图像和文本领域的发现,如果在每次训练中,根据与损失的梯度的二范数成比例的建议分布进行采样,可以将训练收敛速度最大化。但是,这样直接计算这样的建议分布是计算昂贵的,因此该作者使用了与损失函数本身成比例的近似建议分布来提高计算效率。这在图像分类和语言建模中已经验证了。最后,为了减少计算量,提出分段常数近似(PWC)。由于所提出方法十分简单,所以可以直接应用到目前的PINN模型中。
有一个逐步的推导:
这是目前的优化目标函数,最小化所有配置点的损失
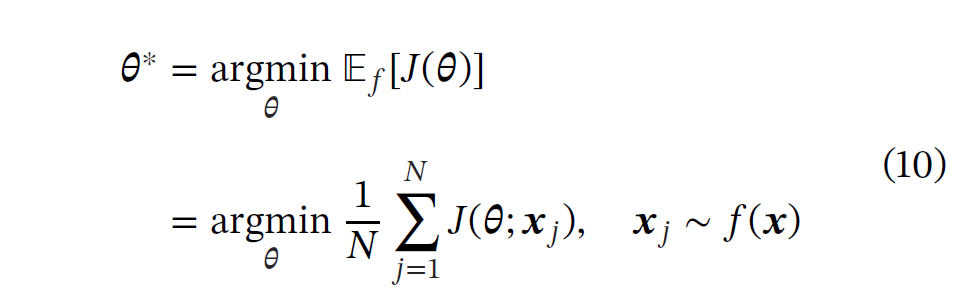
作者希望将其改进成下式,因为有理论证明,下式可以假如收敛。f是均匀采样,q是我们所需要的找的采样分布。在这里我们只考虑离散分布。
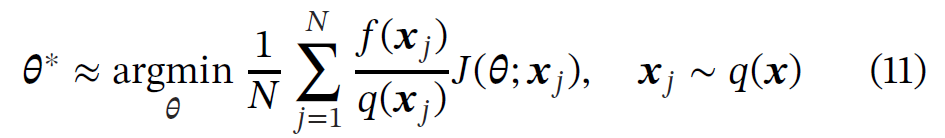
根据理论,这个分布可以找到,并且这个分布于损失函数梯度的二范数相关(某点的损失与所有点的损失之和的比值,考虑离散分布)。
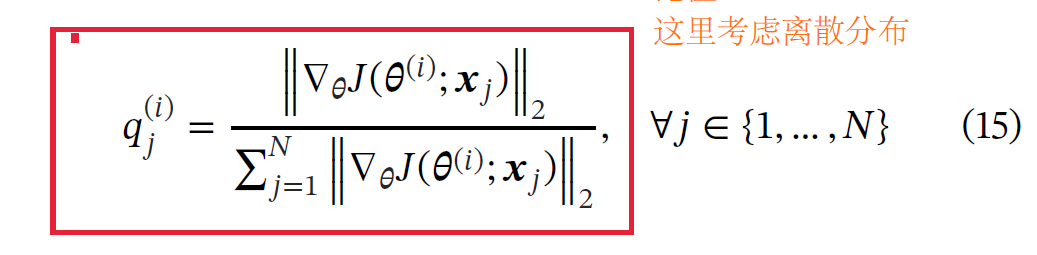
然后,训练时,我们利用q,从N个配置点中,选取m个,作为重要性的代表,用来更新网络。作者认为这样比均匀采样更具代表性,更有利于PINN的收敛。
最后我们的更新方法为下式(η应该为学习率):
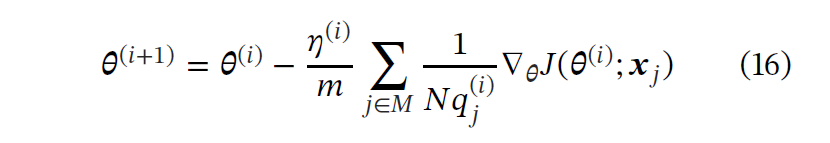
理论证明(上面的推导),可以通过重要性采样加速PINN的训练,其中训练样本是从与损失函数相对于模型参数的梯度的2范数成比例的分布中获得的。但是,直接计算这个分布是昂贵。再次根据理论(Katharopoulos and Fleuret),我们可以使用损失值而不是梯度来作为重要性指标。我们最后获得的分布是:
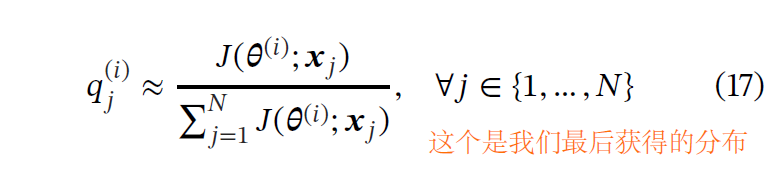
不过,每次迭代中对计算这种分布也是昂贵的,因此作者提出了一个分段常数近似对于损失函数。即,只在点子集上评估,然后使用最近邻搜索,对于每一个配置点j,确定最近的种子s,并且将配置点j的损失值设定成种子s处的损失值。下图为一个示意图,其中橙色为种子s。

伪代码如下:

实验部分,作者做了很多消融实验。但具体的性能提升是有限的。也没有与其他PINN的变体相比。
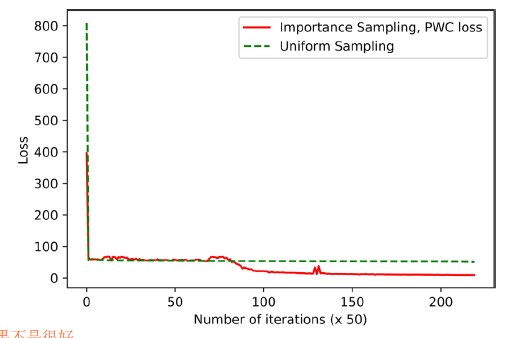
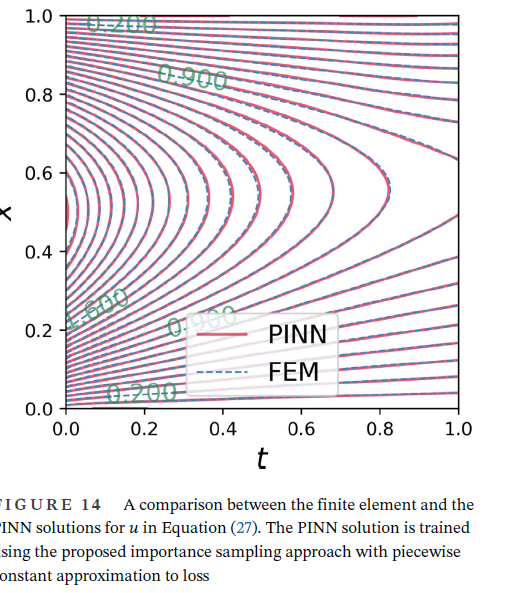
这篇论文虽然简单,还很一般,但是我还是有收获的。最大的一点就是,本文有少量的理论推导,以前我是读不动的,这次读起来感觉还可以。因此以后可以逐渐的进步了。
Efficient training of physics-informed neural networks via importance sampling的更多相关文章
- 阅读笔记 The Impact of Imbalanced Training Data for Convolutional Neural Networks [DegreeProject2015] 数据分析型
The Impact of Imbalanced Training Data for Convolutional Neural Networks Paulina Hensman and David M ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- Must Know Tips/Tricks in Deep Neural Networks
Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei) Deep Neural Networks, especially C ...
- Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)
http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html Deep Neural Networks, especially Conv ...
- 《Graph Neural Networks: A Review of Methods and Applications》阅读笔记
本文是对文献 <Graph Neural Networks: A Review of Methods and Applications> 的内容总结,详细内容请参照原文. 引言 大量的学习 ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- [论文阅读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNet)
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 本文提出的模型叫Mobi ...
- [Converge] Training Neural Networks
CS231n Winter 2016: Lecture 5: Neural Networks Part 2 CS231n Winter 2016: Lecture 6: Neural Networks ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- 【论文翻译】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文链接:https://arxi ...
随机推荐
- sqlserver 行转列 列转行
行列互转,是一个经常遇到的需求.实现的方法,有case when方式和2005之后的内置pivot和unpivot方法来实现. 在读了技术内幕那一节后,虽说这些解决方案早就用过了,却没有系统性的认识和 ...
- php连接Access数据库
最近想把一个asp的网站改成php的,无奈空间不支持mysql数据库,只好用access数据库了,但以前都是用的php+mysql,php+access数据库编程还真没有做过.感谢党,感谢cctv,感 ...
- SQL Server迁移数据库文件(ldf&mdf文件)到其他盘
为什么 SQL Server安装时,默认都安装在C盘,包括数据库文件的默认位置也是C盘 一般路径是C:/Program Files/Microsoft SQL Server/MSSQL14.MSSQL ...
- Jmeter 快速生成测试报告
我们使用Jmeter工具进行接口测试或性能测试后一般是通过察看结果数.聚合报告等监听器来查看响应结果.一.Jmeter配置 首先要保证jmeter命令是ok的,如果你在cmd中输入jmeter -v, ...
- web生命周期概览
1, 输入URL(或单击连接). 2, 生成请求并发送至服务器. 3,执行某些动作或者获取某些资源;将响应发送给客户端. 4,处理HTML,CSS和JavaScript并构建结果页面. 5,监控事件队 ...
- 使用iperf测试网卡性能
1.目标 测试网卡通信性能,同时可以通过改变连接方式(从两台PC网线直连,切换到通过交换机连接)测试交换机最高速率性能. 2.使用工具 硬件:两台PC机(本例用win10 64位).数根网线.交换机 ...
- ElementUI导航连续点击报错
原因 vue项目中连续多次点击路由, 原因是在路由跳转时不允许同一个路由添加多次 错误解决: 吧vue-router换成3.0版本 import Vue from 'vue' import Route ...
- SQLServer中使用between查询日期
SQL Server中字段是Datetime型 以" YYYY-MM-DD 00:00:00" 存放的 between and是包括边界值的,not between不包括边界值,不 ...
- MySQL 增加timestamp 列都是000000的时间
问题: 在MySQL 用工具navicat 给表增加 类型为 timestamp 的列的时候 默认值没有具体设置 默认值使用当前时间 CURRENT_TIMESTAMP 函数 导致生成的默认是0000 ...
- Software_programming_automation_selenium
10:52:37 Table 获取 tr list 注意会无法正常遍历获取. 修正后正常 1 public SelectionCriteriaPage checkSpecifyTag(int coun ...