Django聚合函数与分组查询
一:聚合查询
1.聚合函数作用
聚合查询通常情况下都是配合分组一起使用的
2.聚合函数查询关键字:
aggregate
3.聚合函数
Max : 最大值
Min : 最小值
Sum : 求合
Count : 计数
Avg : 平均值
4.聚合函数使用
# 聚合函数查询
from app01 import models
from django.db.models import Max,Min,Sum,Count,Avg
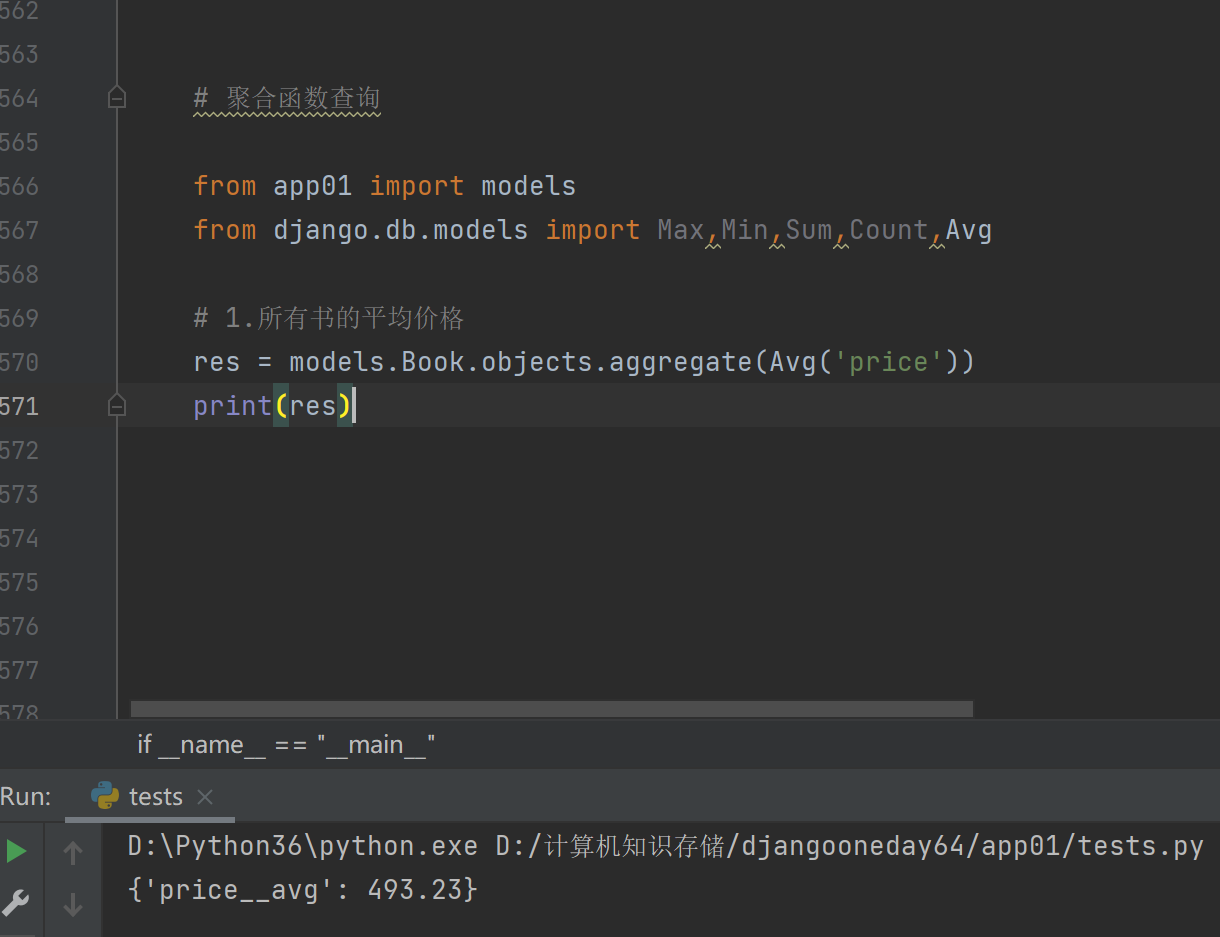
# 1.所有书的平均价格
res = models.Book.objects.aggregate(Avg('price'))
print(res)
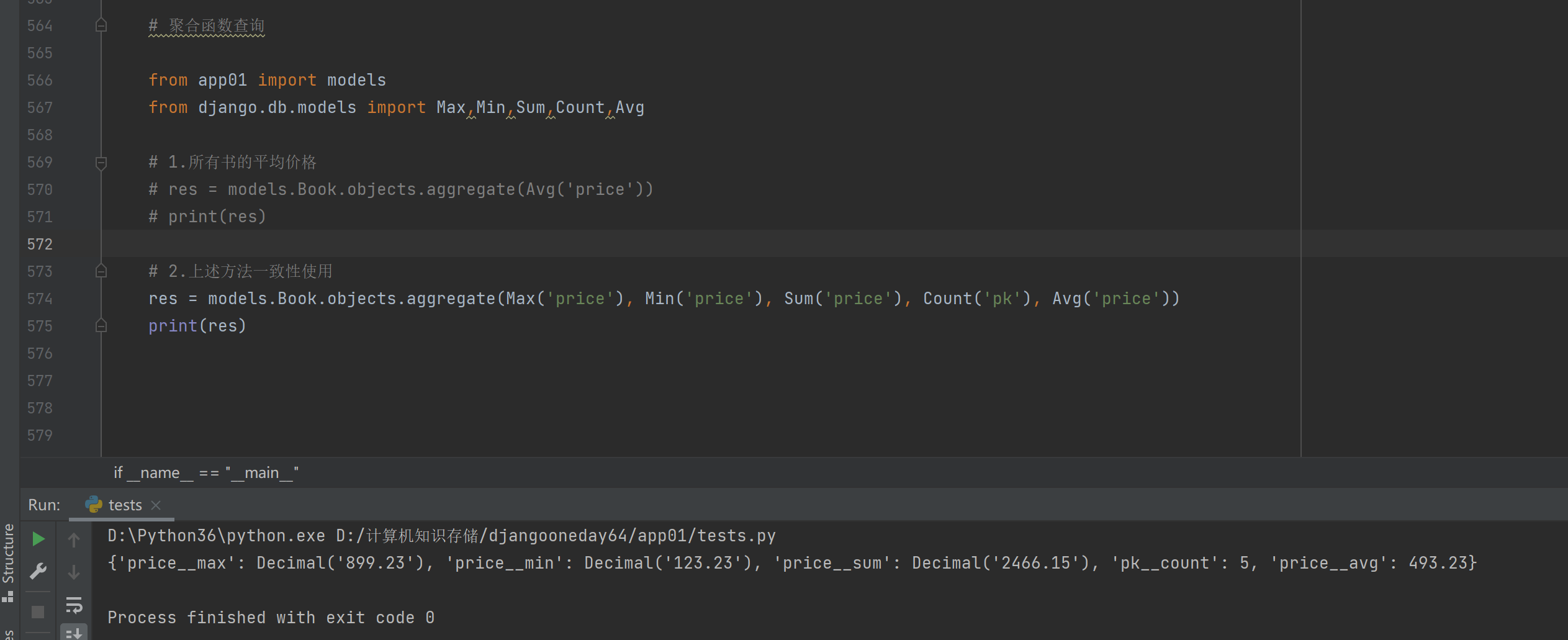
# 2.上述方法一致性使用
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Count('pk'), Avg('price'))
print(res)
二:分组查询
1.分组查询
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数,所有使用前要从django.db.models引入Avg,Max,Count,Sum(首字母大写))。
2.返回值
- 分组后,用values取值,则返回值是QuerySet书籍类型里面为一个个字典
- 分组后,用values_list取值,则返回值是QuerySet数据类型里面为一个个元组
MySQL中的limit相当于ORM中的QuerySet数据类型的切片。
3.分组查询关键字
annotate() 里面放聚合函数
- values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
- values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
- filter放在 annotate 前面:表示where条件
- filter放在annotate后面:表示having
4.分组查询特点
分组之后默认只能获取分组的依据 组内其他字段都无法直接获取
严格模式
ONLY_FULL_GROUP_BY
5总结:
跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询
三:分组使用
1.统计每一本书的作者个数
from django.db.models import Max, Min, Sum, Count, Avg
# res = models.Book.objects.annotate()
按照书分组 正向查询 按字段 authors__kp 分组省略 __kp 将前面数据拿过来
res = models.Book.objects.annotate(authors_num=Count('authors')).values('title', 'authors_num')
print(res)
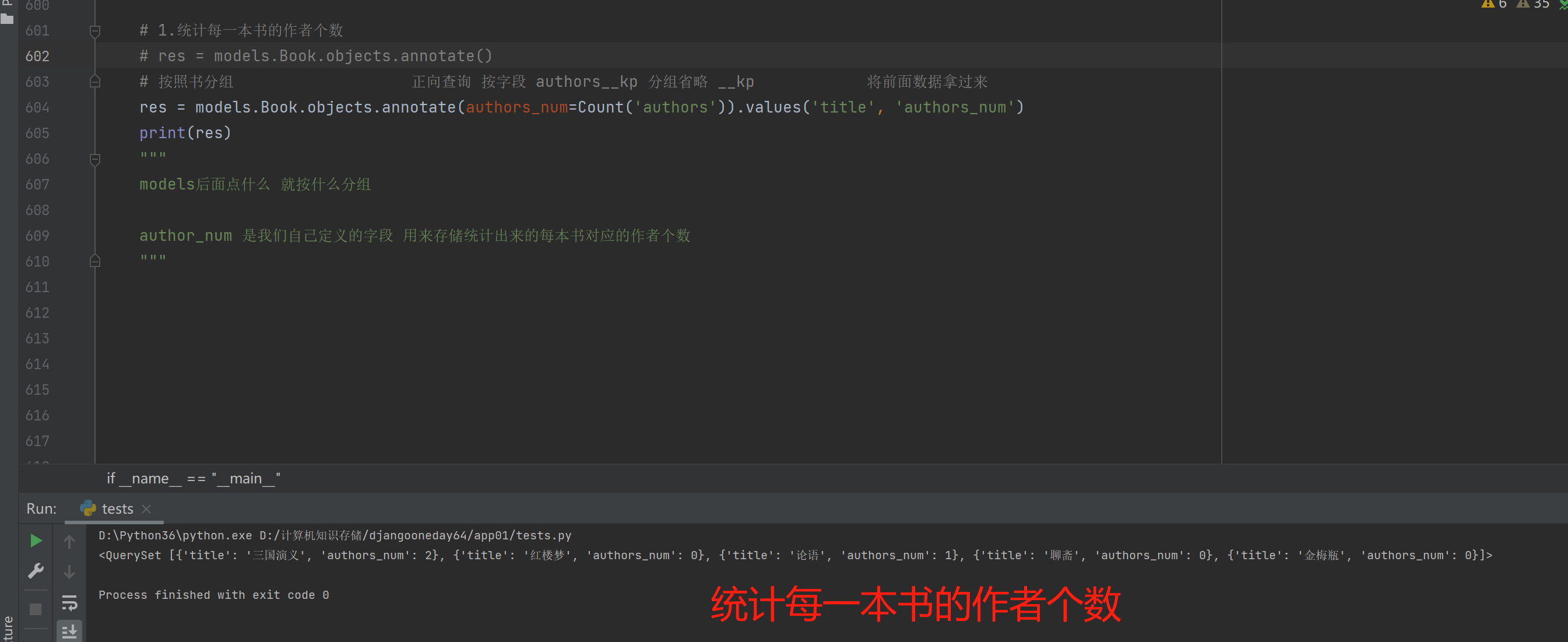
models后面点什么 就按什么分组
author_num 是我们自己定义的字段 用来存储统计出来的每本书对应的作者个数
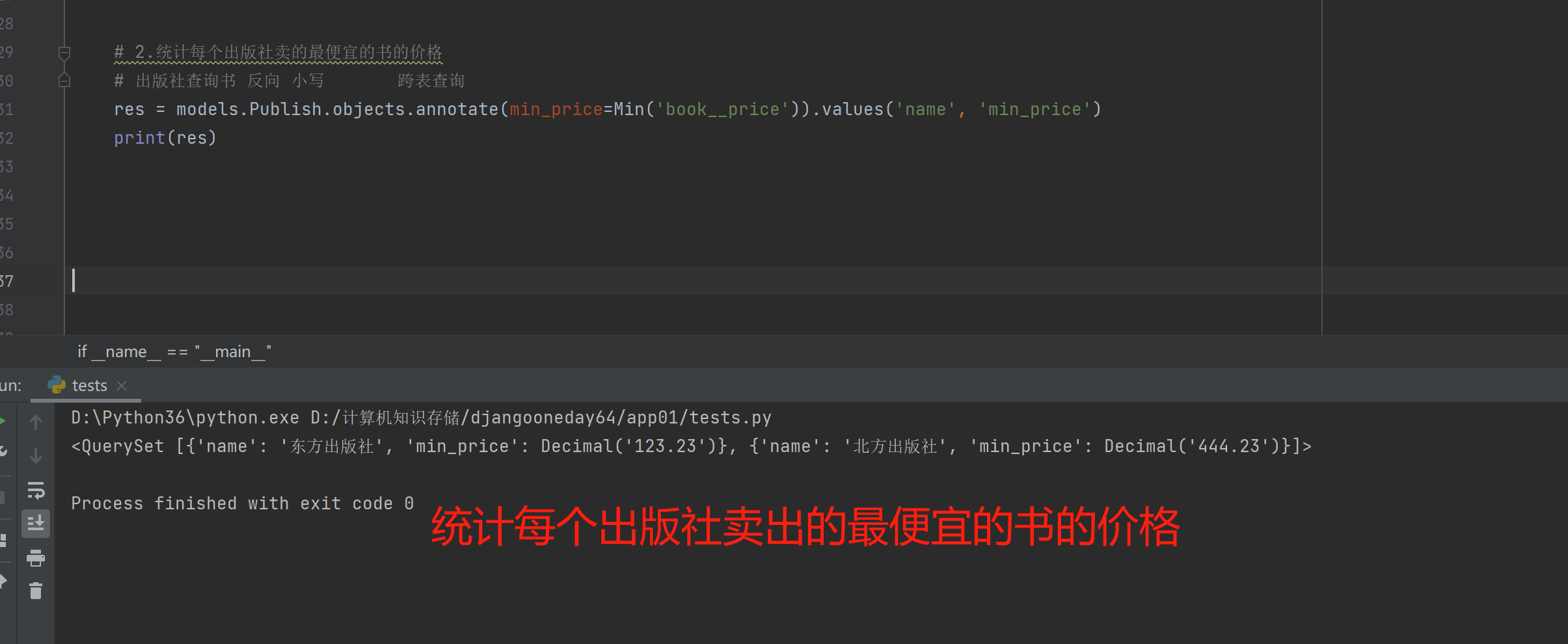
2.统计每个出版社卖的最便宜的书的价格
出版社查询书 反向 小写 跨表查询
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res)
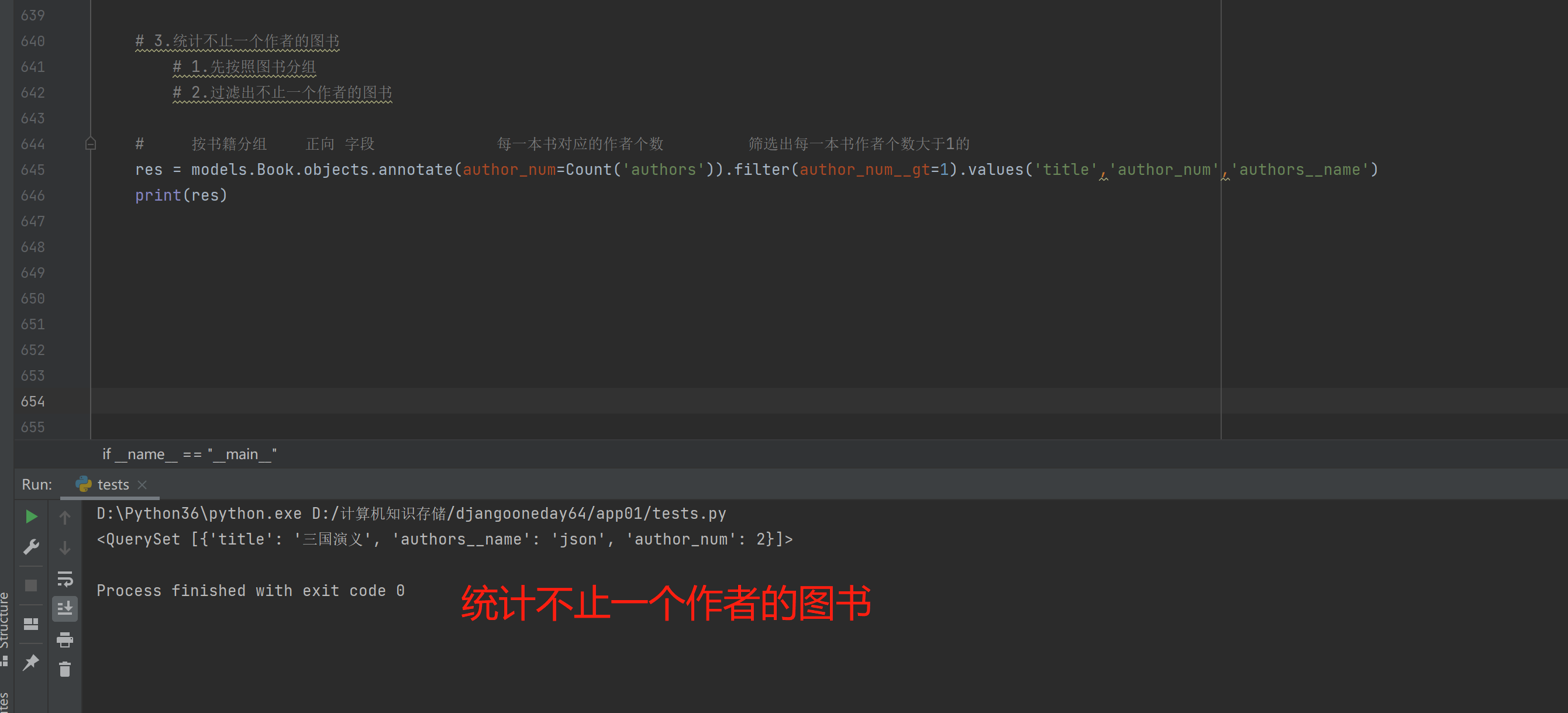
3.统计不止一个作者的图书
1.先按照图书分组
2.过滤出不止一个作者的图书
# 按书籍分组 正向 字段 每一本书对应的作者个数 筛选出每一本书作者个数大于1的
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title','author_num','authors__name')
print(res)
4.查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res)
Django聚合函数与分组查询的更多相关文章
- $Django 聚合函数、分组查询、F,Q查询、orm字段以及参数
一.聚合函数 from django.db.models import Avg,Sum,Max,Min,Count,F,Q #导入 # .查询图书的总价,平均价,最大价,最小价 ...
- ORM中聚合函数、分组查询、Django开启事务、ORM中常用字段及参数、数据库查询优化
聚合函数 名称 作用 Max() 最大值 Min() 最小值 Sum() 求和 Count() 计数 Avg() 平均值 关键字: aggregate 聚合查询通常都是配合分组一起使用的 关于数据库的 ...
- hibernate学习系列-----(5)hibernate基本查询下篇:hibernate聚合函数、分组查询及命名查询
在上一篇中,大致学习了hibernate的基本查询:HQL基本查询,今天,继续昨天的步伐,继续学习hibernate的基本查询..... 1.hql聚合函数,先大致列一下hql的聚合函数有哪些吧: 在 ...
- MySQL数据操作与查询笔记 • 【第6章 聚合函数和分组查询】
全部章节 >>>> 本章目录 6.1 sum.max 和 min 聚合函数 6.1.1 聚合函数介绍 6.1.2 sum 函数 6.1.3 max/min 函数 6.2 a ...
- Django ORM 多对多操作 使用聚合函数和分组 F查询与Q查询
创建表 # models.py form django.db import models class Book(models.Model): # 表名book,django会自动使用项目名+我们定义的 ...
- SQL Server 基础 04 函数与分组查询数据
函数与分组查询数据 系统函数分 聚合函数.数据类型转换函数.日期函数.数学函数 . . . 1. 聚合函数 主要是对一组值进行计算,然后返回一个值. 聚合函数包括 sum(求和).avg(求平均值). ...
- Django的mode的分组查询和聚合查询和F查询和Q查询
1.聚合查询 # 聚合函数aggregate,求指定字段的最大值,最小值,平均值,和的值,方法如下 from django.db.models import Avg from django.db.mo ...
- orm中的聚合函数,分组,F/Q查询,字段类,事务
目录 一.聚合函数 1. 基础语法 2. Max Min Sum Avg Count用法 (1) Max()/Min() (2)Avg() (3)Count() (4)聚合函数联用 二.分组查询 1. ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均值 –MAX:计算列的最大值 –MIN:计 ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
拖了一个星期,终于开始写第三篇了.走起! 聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均 ...
随机推荐
- k8s中pod的容器日志查看命令
如果容器已经崩溃停止,您可以仍然使用 kubectl logs --previous 获取该容器的日志,只不过需要添加参数 --previous. 如果 Pod 中包含多个容器,而您想要看其中某一个容 ...
- Prometheus告警处理
在Prometheus Server中定义告警规则以及产生告警,Alertmanager组件则用于处理这些由Prometheus产生的告警.Alertmanager即Prometheus体系中告警的统 ...
- 11. Fluentd部署:性能优化
如果你的日志请求达到了5000条/秒,这里描述的技术点可用于调优. 检查操作系统配置 在安装Fluentd之前,进行操作系统参数优化. 通过top查看系统瓶颈 如果发现Fluentd运行效率不佳,可先 ...
- 微信小程序开发优化
一.开发优化一 1.使用Vant Weapp 1.1 什么是Vant Weapp Vant Weapp官网链接 Vant Weapp是有赞前端团队开源的一套小程序UI组件库,助力开发者快速搭建小程序应 ...
- StampedLock:一个并发编程中非常重要的票据锁
摘要:一起来聊聊这个在高并发环境下比ReadWriteLock更快的锁--StampedLock. 本文分享自华为云社区<[高并发]一文彻底理解并发编程中非常重要的票据锁--StampedLoc ...
- Stanford CoreNLP无法生成实例对象
在服务器上运行Stanford,今日无法启动"StanfordCoreNLP"了,就是运行下面代码一直在运行,不结束,不报错. from stanfordcorenlp impor ...
- 记录一次使用git工具拉取coding上代码密码账号错误的经历
1.忘记密码 1.另外的一个位置
- DevOps|1024程序员节怎么做?介绍下我的思路
1024,祝每个程序员小哥哥小姐姐节日快乐. 因为在研发效能部门,我支持过几次 1024 程序员节的活动,所以经常有朋友问我1024 程序员节怎么做,本篇就是简单介绍下我的思路,希望对你有用. 102 ...
- LabVantage仪器数据采集方案
LabVantage的仪器数据采集组件为LIMS CI,是一个独立的应用程序/服务,实现仪器数据的采集(GC.LC等带有工作站的仪器). 将仪器输出数据转换为LIMS所需数据并传输,使用Talend这 ...
- 使用rsync向服务器迁移大文件
场景 本人将12G本地单文件(12G大小h5文件数据集)向Linux服务器进行大文件上传时传输失败.最初使用 scp 命令或 rsync 直接对大文件进行传输,会出现网络断开或服务器端管道破裂情况,而 ...