Django聚合函数与分组查询
一:聚合查询
1.聚合函数作用
聚合查询通常情况下都是配合分组一起使用的
2.聚合函数查询关键字:
aggregate
3.聚合函数
Max : 最大值
Min : 最小值
Sum : 求合
Count : 计数
Avg : 平均值
4.聚合函数使用
# 聚合函数查询
from app01 import models
from django.db.models import Max,Min,Sum,Count,Avg
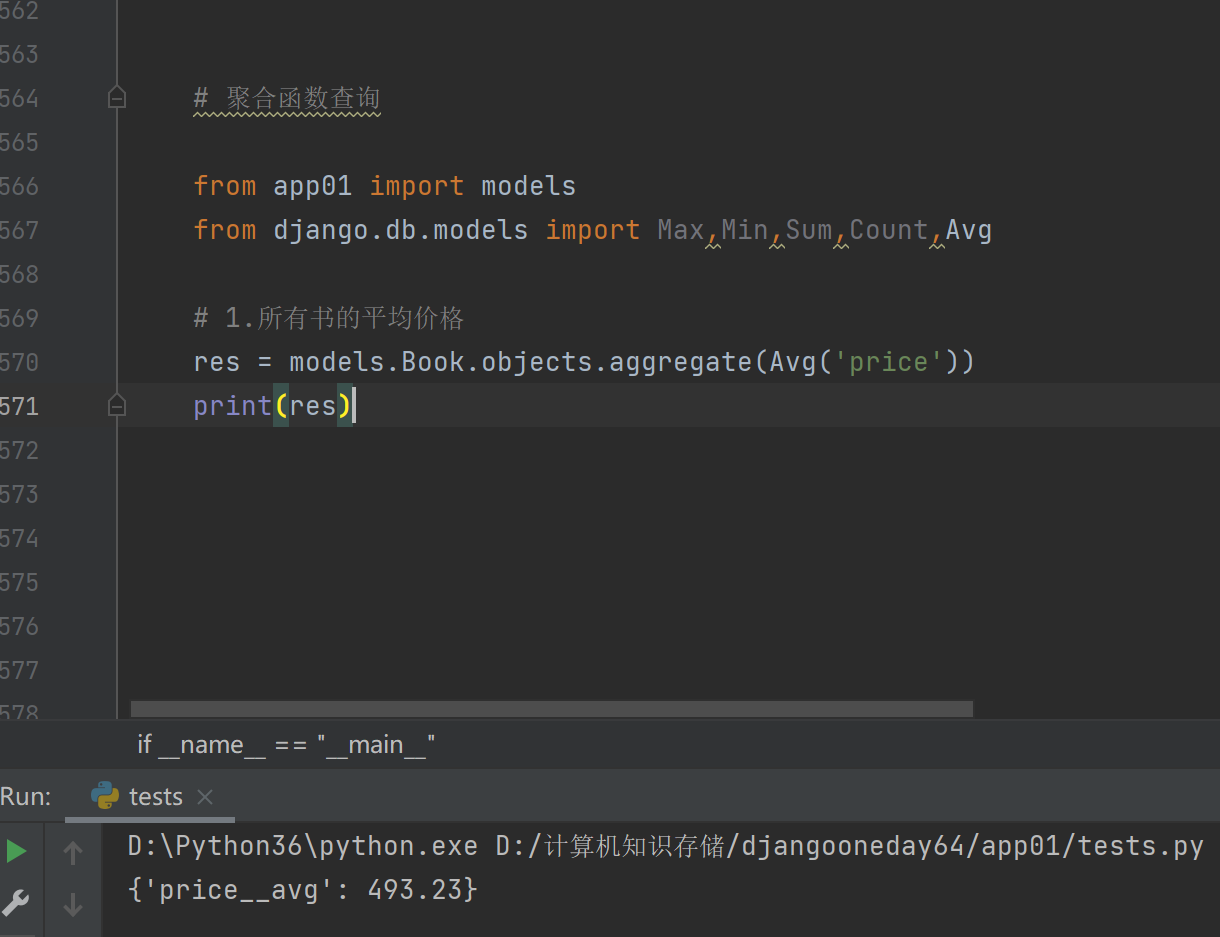
# 1.所有书的平均价格
res = models.Book.objects.aggregate(Avg('price'))
print(res)
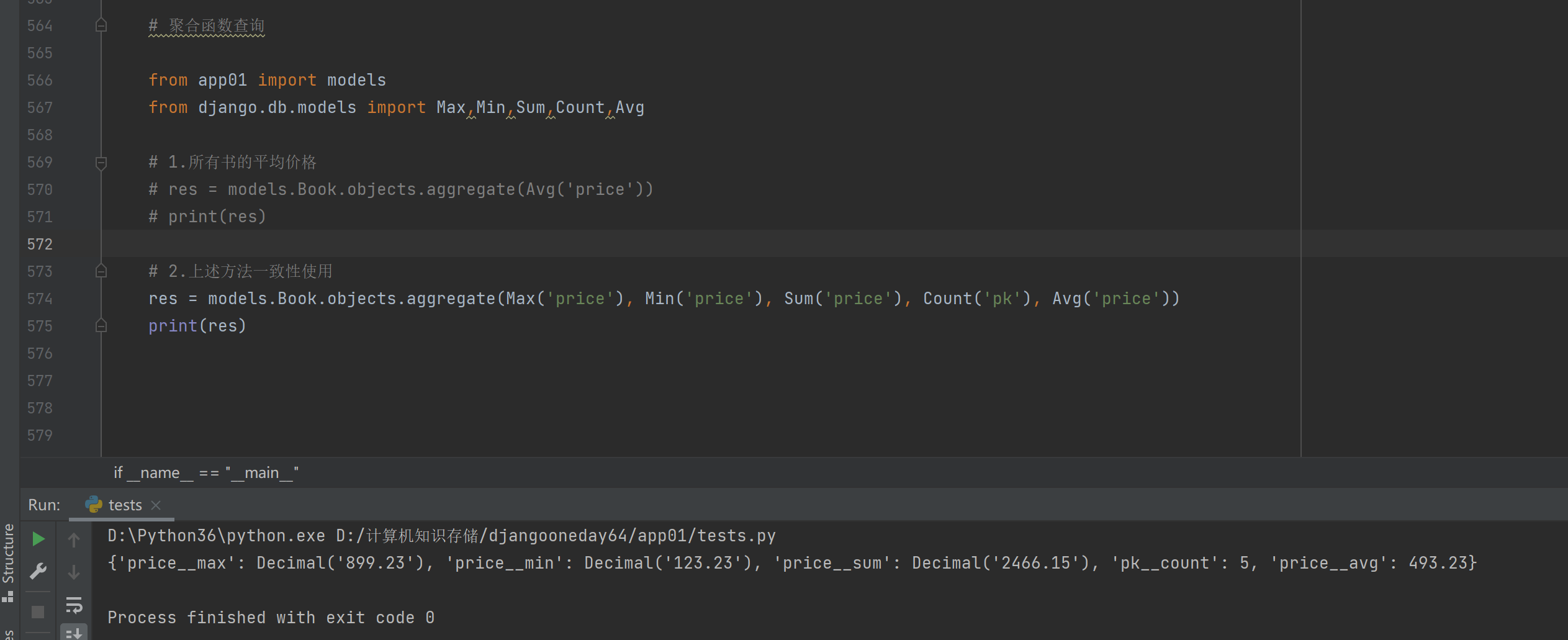
# 2.上述方法一致性使用
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Count('pk'), Avg('price'))
print(res)
二:分组查询
1.分组查询
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数,所有使用前要从django.db.models引入Avg,Max,Count,Sum(首字母大写))。
2.返回值
- 分组后,用values取值,则返回值是QuerySet书籍类型里面为一个个字典
- 分组后,用values_list取值,则返回值是QuerySet数据类型里面为一个个元组
MySQL中的limit相当于ORM中的QuerySet数据类型的切片。
3.分组查询关键字
annotate() 里面放聚合函数
- values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
- values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
- filter放在 annotate 前面:表示where条件
- filter放在annotate后面:表示having
4.分组查询特点
分组之后默认只能获取分组的依据 组内其他字段都无法直接获取
严格模式
ONLY_FULL_GROUP_BY
5总结:
跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询
三:分组使用
1.统计每一本书的作者个数
from django.db.models import Max, Min, Sum, Count, Avg
# res = models.Book.objects.annotate()
按照书分组 正向查询 按字段 authors__kp 分组省略 __kp 将前面数据拿过来
res = models.Book.objects.annotate(authors_num=Count('authors')).values('title', 'authors_num')
print(res)
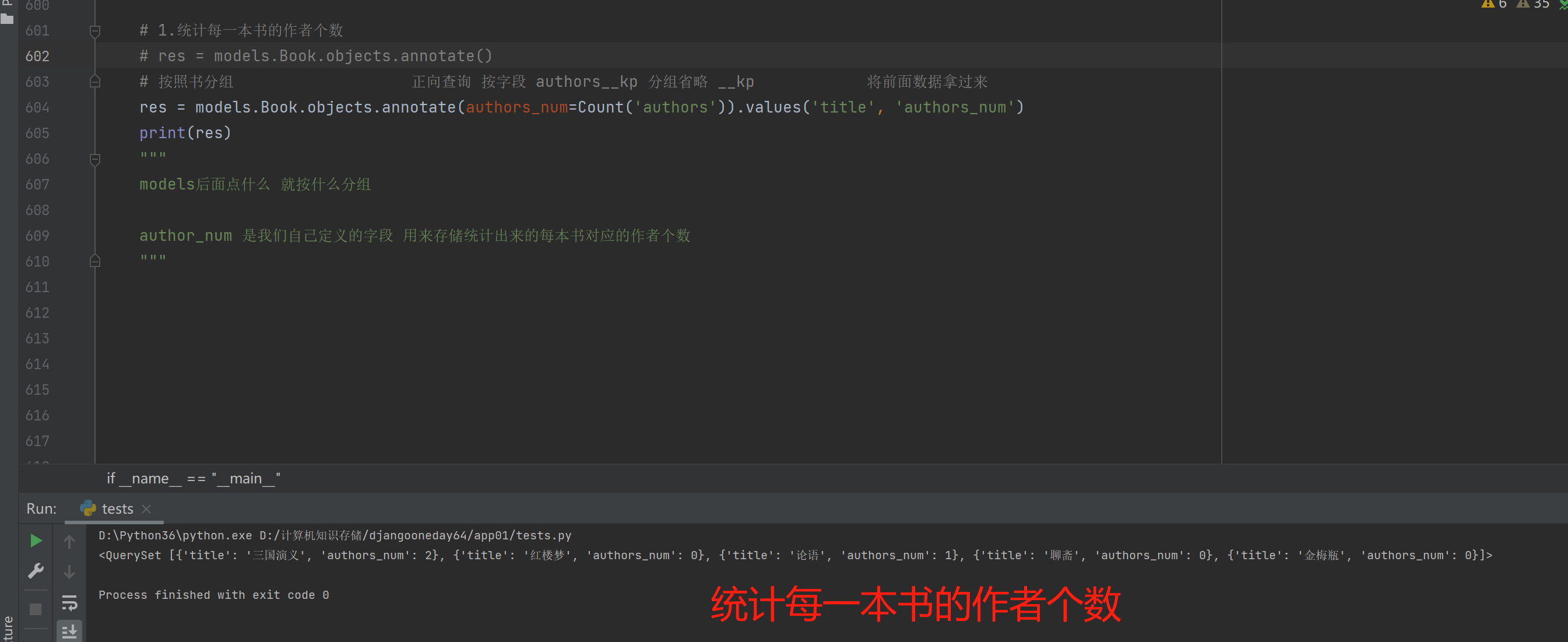
models后面点什么 就按什么分组
author_num 是我们自己定义的字段 用来存储统计出来的每本书对应的作者个数
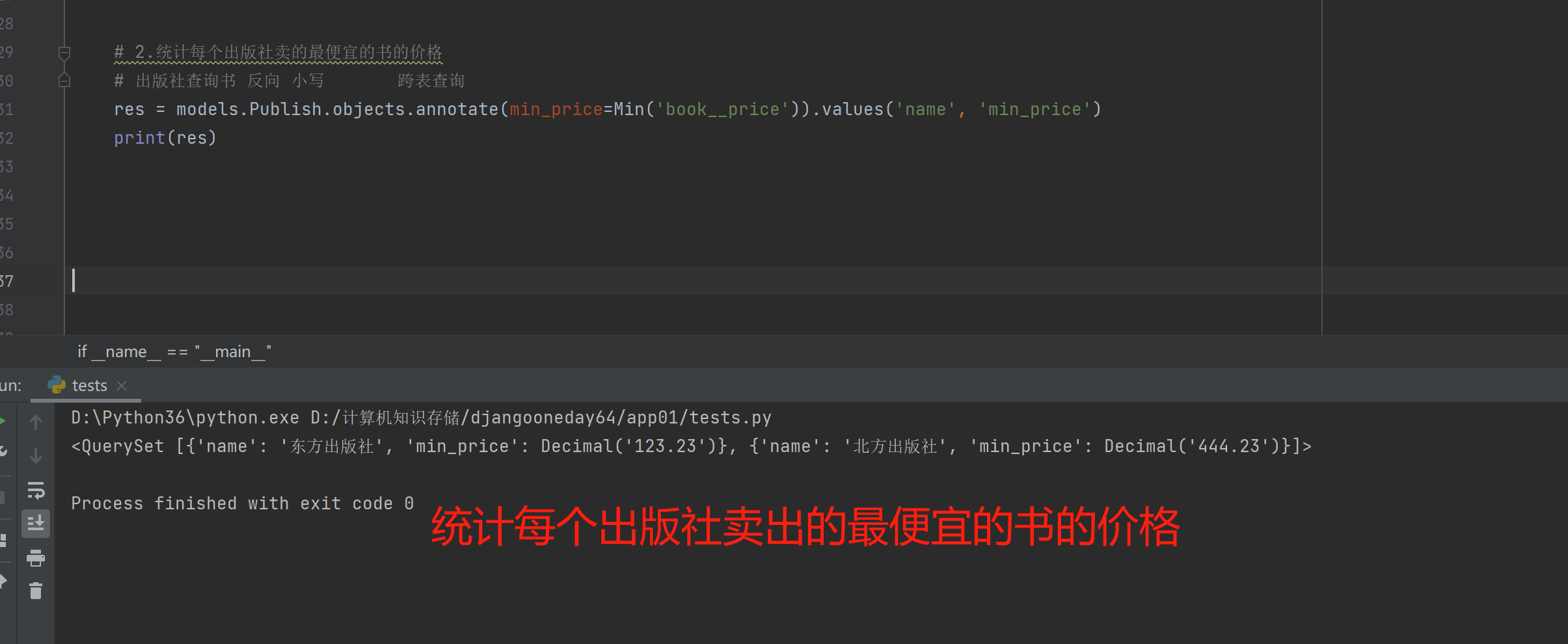
2.统计每个出版社卖的最便宜的书的价格
出版社查询书 反向 小写 跨表查询
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res)
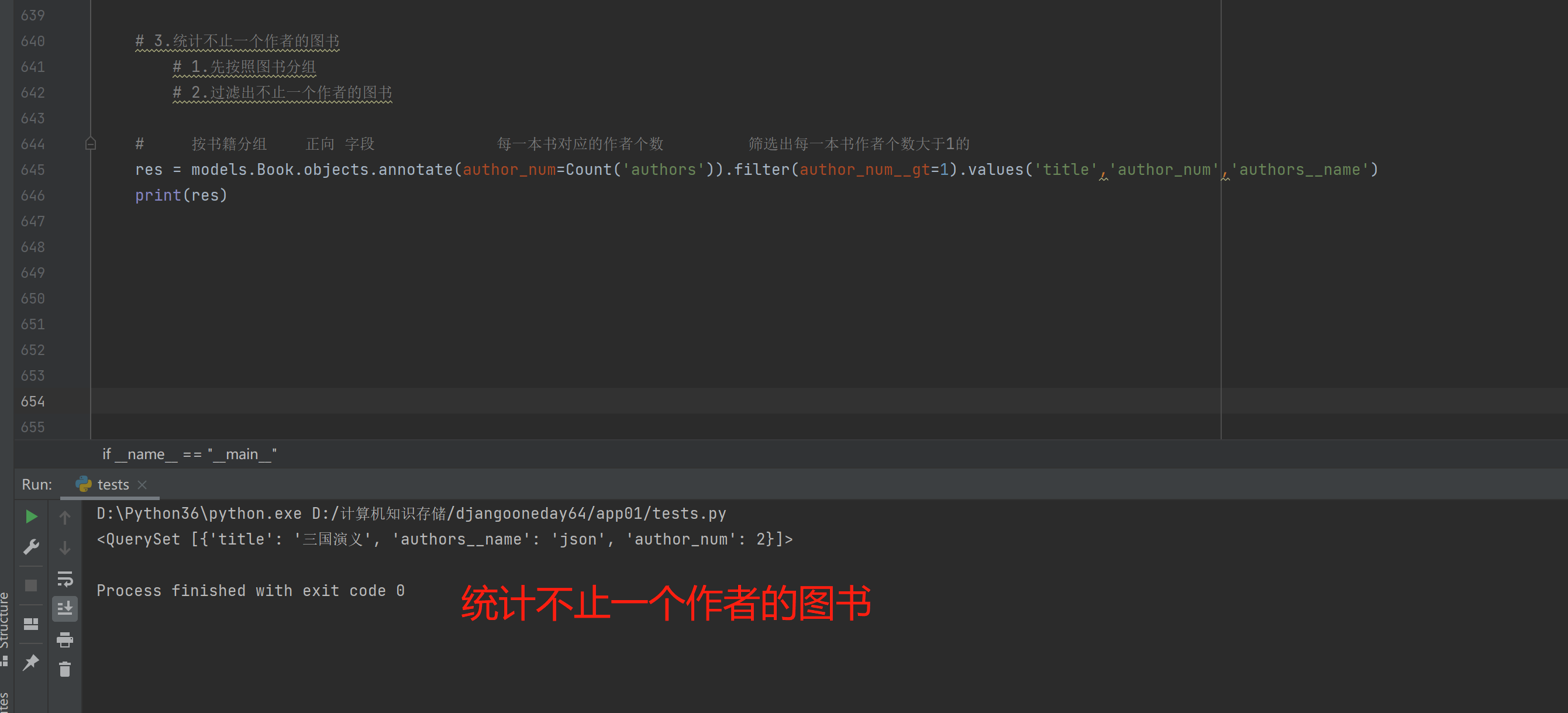
3.统计不止一个作者的图书
1.先按照图书分组
2.过滤出不止一个作者的图书
# 按书籍分组 正向 字段 每一本书对应的作者个数 筛选出每一本书作者个数大于1的
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title','author_num','authors__name')
print(res)
4.查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res)
Django聚合函数与分组查询的更多相关文章
- $Django 聚合函数、分组查询、F,Q查询、orm字段以及参数
一.聚合函数 from django.db.models import Avg,Sum,Max,Min,Count,F,Q #导入 # .查询图书的总价,平均价,最大价,最小价 ...
- ORM中聚合函数、分组查询、Django开启事务、ORM中常用字段及参数、数据库查询优化
聚合函数 名称 作用 Max() 最大值 Min() 最小值 Sum() 求和 Count() 计数 Avg() 平均值 关键字: aggregate 聚合查询通常都是配合分组一起使用的 关于数据库的 ...
- hibernate学习系列-----(5)hibernate基本查询下篇:hibernate聚合函数、分组查询及命名查询
在上一篇中,大致学习了hibernate的基本查询:HQL基本查询,今天,继续昨天的步伐,继续学习hibernate的基本查询..... 1.hql聚合函数,先大致列一下hql的聚合函数有哪些吧: 在 ...
- MySQL数据操作与查询笔记 • 【第6章 聚合函数和分组查询】
全部章节 >>>> 本章目录 6.1 sum.max 和 min 聚合函数 6.1.1 聚合函数介绍 6.1.2 sum 函数 6.1.3 max/min 函数 6.2 a ...
- Django ORM 多对多操作 使用聚合函数和分组 F查询与Q查询
创建表 # models.py form django.db import models class Book(models.Model): # 表名book,django会自动使用项目名+我们定义的 ...
- SQL Server 基础 04 函数与分组查询数据
函数与分组查询数据 系统函数分 聚合函数.数据类型转换函数.日期函数.数学函数 . . . 1. 聚合函数 主要是对一组值进行计算,然后返回一个值. 聚合函数包括 sum(求和).avg(求平均值). ...
- Django的mode的分组查询和聚合查询和F查询和Q查询
1.聚合查询 # 聚合函数aggregate,求指定字段的最大值,最小值,平均值,和的值,方法如下 from django.db.models import Avg from django.db.mo ...
- orm中的聚合函数,分组,F/Q查询,字段类,事务
目录 一.聚合函数 1. 基础语法 2. Max Min Sum Avg Count用法 (1) Max()/Min() (2)Avg() (3)Count() (4)聚合函数联用 二.分组查询 1. ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均值 –MAX:计算列的最大值 –MIN:计 ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
拖了一个星期,终于开始写第三篇了.走起! 聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均 ...
随机推荐
- linux系统排查数据包常用命令
1.查看当前系统中生效的所有参数 sysctl -a 2.统计处于TIME_WAIT状态的TCP连接数 netstat -ant|grep TIME_WAIT|wc -l 3.统计TCP连接数 net ...
- prometheus和granfana企业级监控实战v5
文件地址:https://files.cnblogs.com/files/sanduzxcvbnm/prometheus和granfana企业级监控实战v5.pdf
- Docker网络详解——原理篇
安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络). none .host 网络模式 简介 Host 容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP ...
- 【面试题】Vue2动态添加路由 router.addRoute()
Vue2动态添加路由 点击打开视频讲解更加详细 场景: 一般结合VueX和localstorage一起使用 router.addRoutes vue-router4后 已废弃:使用 router.ad ...
- nsis离开自定义页面保存设置
这是群里一位朋友问他的自定义页面设置完成后返回上一步无法保存怎么办写的一个小例子,拓展了下,只要不关闭,不管上一步还是进入下一步返回都可以保留原页面设置. !include LogicLib.nsh ...
- 2016 ZCTF note3:一种新解法
2016 ZCTF note3:一种新解法 最近在学习unlink做到了这道题,网上有两种做法:一种是利用edit功能读入id时整数溢出使索引为-1,一种是设置块大小为0使得写入时利用整数溢出漏洞可以 ...
- 洛谷U81904 【模板】树的直径
有负边权,所以用树形DP来找树的直径. 1 //树形DP求树的直径 2 #include<bits/stdc++.h> 3 using namespace std; 4 const int ...
- Linux Block模块之IO合并代码解析
1 IO路径 从内核角度看,进程产生的IO路径主要有三条: 缓存IO:系统绝大部分IO走的这种形式,充分利用文件系统层的page cache所带来的优势.应用程序产生的IO经系统调用落入page ca ...
- 经典排序算法之-----选择排序(Java实现)
其他的经典排序算法链接地址:https://blog.csdn.net/weixin_43304253/article/details/121209905 选择排序思想: 思路: 1.从整个数据中挑选 ...
- 通过jmeter连接人大金仓数据库
某项目用的人大金仓数据库,做性能测试,需要用jmeter来连接数据库处理一批数据.jmeter连接人大金仓,做个记录. 1. 概要 在"配置元件"中添加"JDBC Con ...