MapReduce Shuffle And Sort
引言
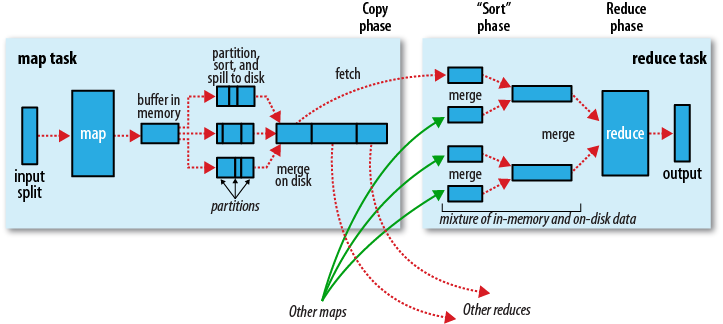
如果溢写文件个数超过3(通过属性min.num.spills.for.combine设置),会对合并且分区排序后的结果执行Combine过程(如果MapReduce有设置Combiner),而且combine过程在不影响最终结果的前提下可能会被执行多次;否则不会执行Combine过程(相对而言,Combine开销过大)。
@Override
public void write(K key, V value) throws IOException,
InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
public int compare(int i, int j) {
final int ii = kvoffsets[i % kvoffsets.length];
final int ij = kvoffsets[j % kvoffsets.length];
// sort by partition
if (kvindices[ii + PARTITION] != kvindices[ij + PARTITION]) {
return kvindices[ii + PARTITION] - kvindices[ij + PARTITION];
}
// sort by key
return comparator.compare(kvbuffer, kvindices[ii + KEYSTART],
kvindices[ii + VALSTART] - kvindices[ii + KEYSTART],
kvbuffer, kvindices[ij + KEYSTART],
kvindices[ij + VALSTART] - kvindices[ij + KEYSTART]);
}
public RawComparator getOutputKeyComparator() {
Class<? extends RawComparator> theClass = getClass(
"mapred.output.key.comparator.class", null, RawComparator.class);
if (theClass != null) {
return ReflectionUtils.newInstance(theClass, this);
}
return WritableComparator.get(getMapOutputKeyClass().asSubclass(
WritableComparable.class));
}
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
public class WritableComparator implements RawComparator {
private static HashMap<Class, WritableComparator> comparators = new HashMap<Class, WritableComparator>();
public static synchronized WritableComparator get(
Class<? extends WritableComparable> c) {
WritableComparator comparator = comparators.get(c);
if (comparator == null) {
comparator = new WritableComparator(c, true);
}
return comparator;
}
public static synchronized void define(Class c,
WritableComparator comparator) {
comparators.put(c, comparator);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
// parse key1
buffer.reset(b1, s1, l1);
key1.readFields(buffer);
// parse key2
buffer.reset(b2, s2, l2);
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
// compare them
return compare(key1, key2);
}
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
public int compare(Object a, Object b) {
return compare((WritableComparable) a, (WritableComparable) b);
}
}
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context)
throws IOException, InterruptedException {
......
}
MapReduce Shuffle And Sort的更多相关文章
- mapreduce shuffle 和sort 详解
MapReduce 框架的核心步骤主要分两部分:Map 和Reduce.当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执 ...
- Hadoop-2.2.0中文文档—— MapReduce下一代- 可插入的 Shuffle 和 Sort
简单介绍 可插入的 shuffle 和 sort 功能,同意在shuffle 和 sort 逻辑中用可选择的实现类替换.这个情况的样例是:用一个不是HTTP的应用协议,如RDMA来 shuffle 从 ...
- MapReduce中的Shuffle和Sort分析
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme ...
- 【Hadoop】MapReduce笔记(三):MapReduce的Shuffle和Sort阶段详解
一.MapReduce 总体架构 整体的Shuffle过程包含以下几个部分:Map端Shuffle.Sort阶段.Reduce端Shuffle.即是说:Shuffle 过程横跨 map 和 reduc ...
- Hadoop : MapReduce中的Shuffle和Sort分析
地址 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Sch ...
- MapReduce Shuffle过程
MapReduce Shuffle 过程详解 一.MapReduce Shuffle过程 1. Map Shuffle过程 2. Reduce Shuffle过程 二.Map Shuffle过程 1. ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- shuffle和sort分析
MapReduce中的Shuffle和Sort分析 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的 ...
随机推荐
- rnqoj-57-找啊找啊找GF-二维背包
简单的二维背包问题. 数组t[j][k]记录时间 数组dp[j][k]记录数量 保证数量的前提下,时间最少 #include<stdio.h> #include<string.h&g ...
- 开源实时视频码流分析软件:VideoEye
本文介绍一个自己做的码流分析软件:VideoEye.为什么要起这个名字呢?感觉这个软件的主要功能就是对"视频"进行"分析".而分析是要用眼睛来看的,因此取了&q ...
- 用htaccess进行访问控制(转)
1. 文件访问控制 利用 httpd.conf 中的 Order.Files 及 FilesMatch 命令实现的访问控制可以满足大部分要求,但是当用户被拒绝时,他们看到的是硕大的“403 Forbi ...
- C++发送邮件和附件
c++socketnulldelete服务器stream 头文件 /**************************************************************** ...
- Eclipse中输入系统变量和运行参数--转
原文地址:http://chenzhou123520.iteye.com/blog/1931670 在开发时,有时候可能需要根据不同的环境设置不同的系统参数,我们都知道,在使用java -jar命令时 ...
- Unable to execute dex: java.nio.BufferOverflowException. Check the Eclipse log for stack trace.(转)
1.程序运行后异常显示: 解决方案:在项目上点击右键->properties->Java Build Path, remove掉Android Dependences即可
- bootstrap栅格布局
<!DOCTYPE html> <html lang="en"> <head> <!-- //简介:boststrap内置了一套响应式,移 ...
- 国内各IE内核浏览器所调用的IE版本--转了
60浏览器,腾讯浏览器,世界之窗,遨游…IE的套套浏览器真是到处都是,在日常生活中,身边的朋友用的也不少,毕竟很多人对浏览器这东西不了解,在他们眼里,神马内核一点区别都没有,但咱们做前端的对这些东西可 ...
- (转)PHP文件没有结尾的?>有什么好处?
1.PHP文件没有结尾的?>有什么好处?-- 防止输出一些不必要的空行或者空格2. 如果你是php和html混编的话结尾?> 还是有必要的,否则会报错. 如果没有?>文件末尾的空白行 ...
- asp.net上传文件并创建文件夹和删除文件
上传文件部分代码: /// <summary> /// 上传保存文件并返回文件的保存地址和文件名称 /// </summary> /// <param name=&quo ...