Hadoop MapReduce编程 API入门系列之wordcount版本4(八)
这篇博客,给大家,体会不一样的版本编程。
是将map、combiner、shuffle、reduce等分开放一个.java里。则需要实现Tool。
代码
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
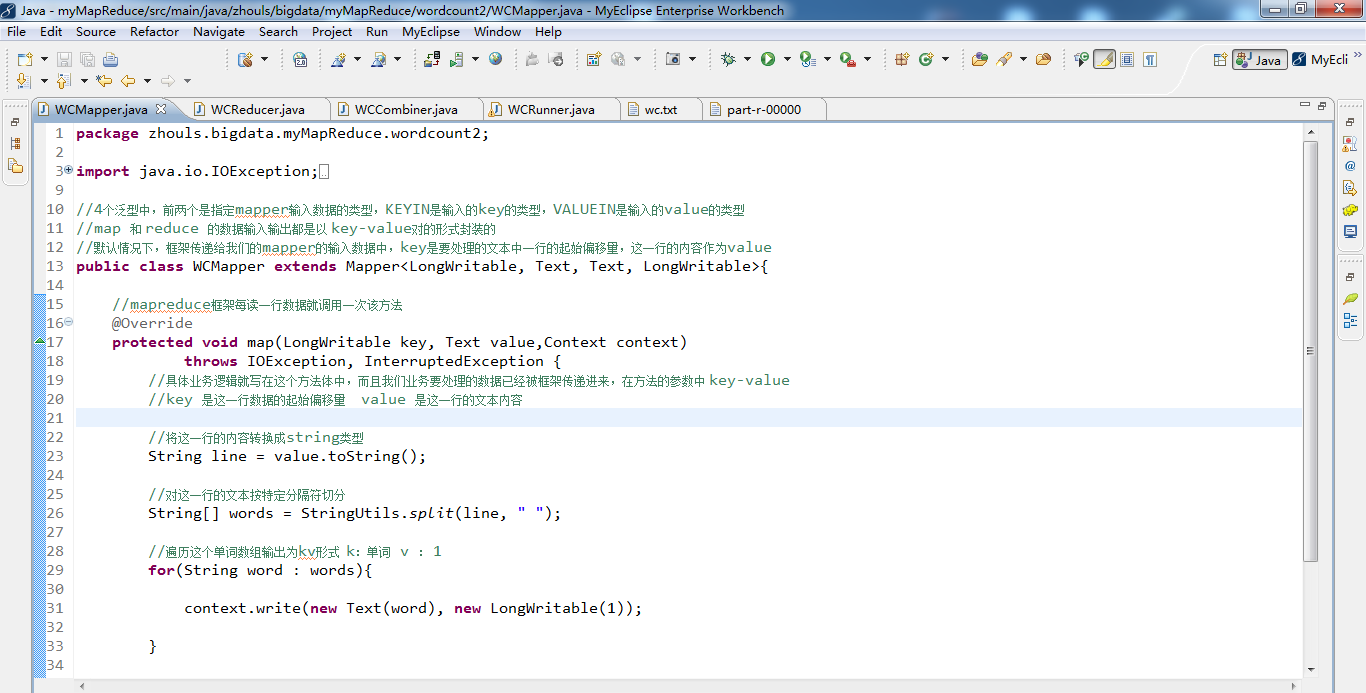
import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException{
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value
//key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型
String line = value.toString(); //对这一行的文本按特定分隔符切分
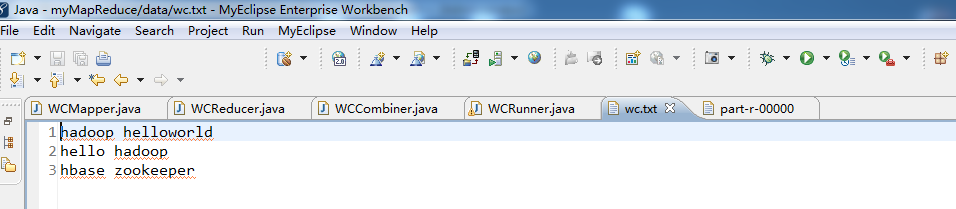
//hadoop helloworld
String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1
for(String word : words){//word是k2
context.write(new Text(word), new LongWritable(1));//写入word是k2,1是v2
// context.write(word,1);等价 } } }
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
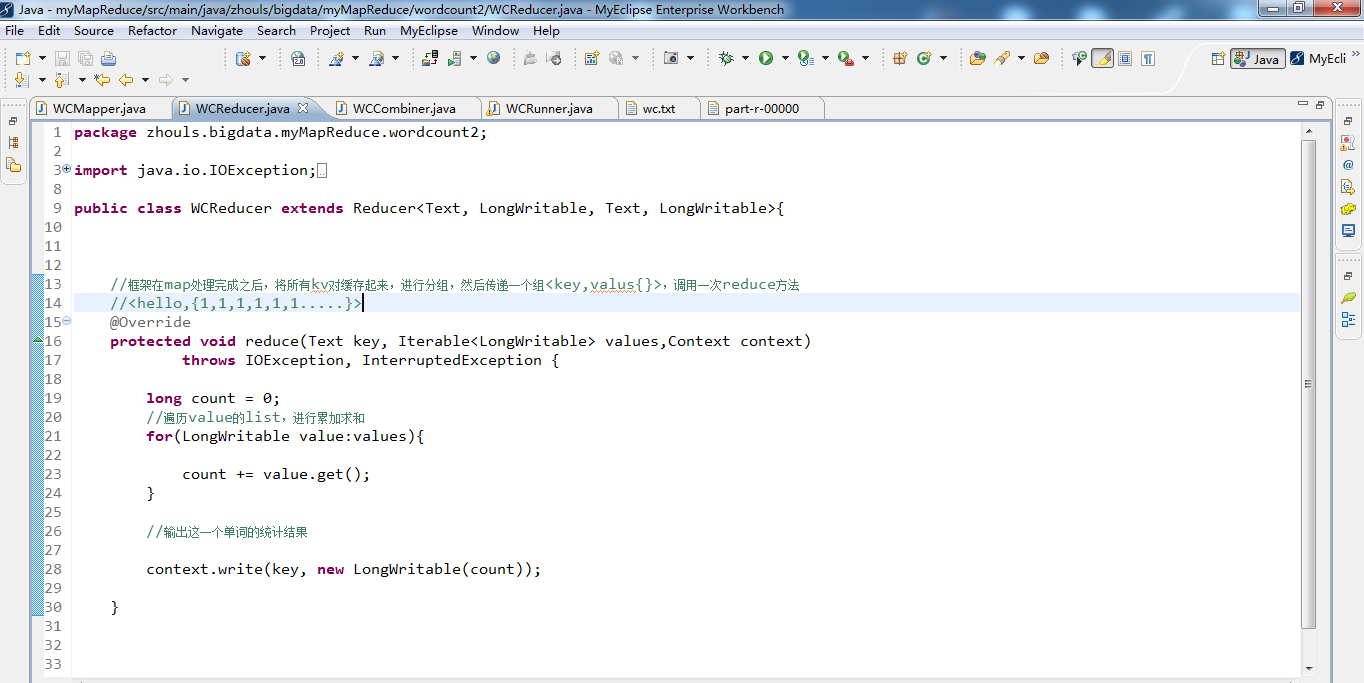
import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ //框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法
//<hello,{1,1,1,1,1,1.....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException {
long count = 0;
//遍历value的list,进行累加求和
for(LongWritable value:values){//value是v2
count += value.get();
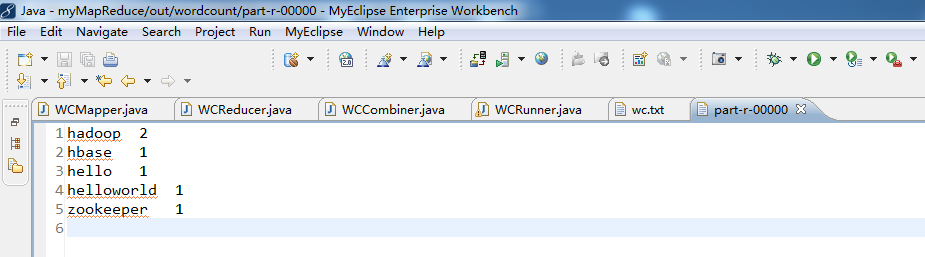
} //输出这一个单词的统计结果 context.write(key,new LongWritable(count));//key是k3,count是v3
// context.write(key,count);
} }
package zhouls.bigdata.myMapReduce.wordcount2; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
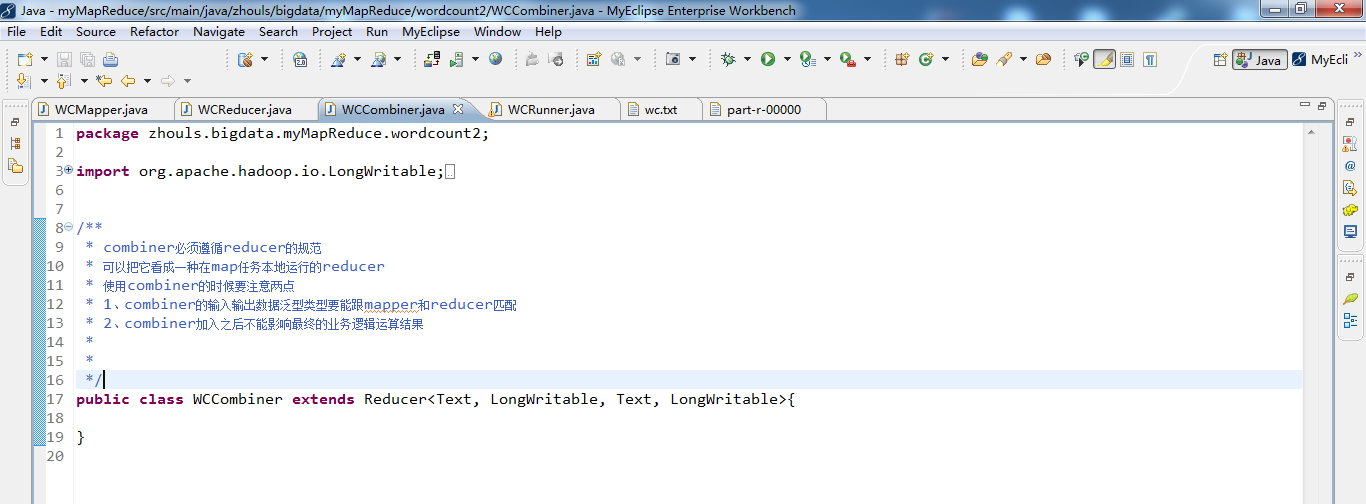
* combiner必须遵循reducer的规范
* 可以把它看成一种在map任务本地运行的reducer
* 使用combiner的时候要注意两点
* 1、combiner的输入输出数据泛型类型要能跟mapper和reducer匹配
* 2、combiner加入之后不能影响最终的业务逻辑运算结果
*
*
*/
public class WCCombiner extends Reducer<Text, LongWritable, Text, LongWritable>{ }
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce
* 还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* ....
* @author duanhaitao@itcast.cn
*
*/
public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类
wcjob.setMapperClass(WCMapper.class);
wcjob.setReducerClass(WCReducer.class); //指定本job使用combiner组件,组件所用的类为
wcjob.setCombinerClass(WCReducer.class); //指定reduce的输出数据kv类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class); // //指定要处理的输入数据存放路径
// FileInputFormat.setInputPaths(wcjob, new Path("hdfs://HadoopMaster:9000/wordcount/wc.txt/"));
//
// //指定处理结果的输出数据存放路径
// FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://HadoopMaster:9000/out/wordcount/wc/")); //指定要处理的输入数据存放路径
FileInputFormat.setInputPaths(wcjob, new Path("./data/wordcount/wc.txt")); //指定处理结果的输出数据存放路径
FileOutputFormat.setOutputPath(wcjob, new Path("./out/wordcount/wc/")); //将job提交给集群运行
wcjob.waitForCompletion(true); } }
Hadoop MapReduce编程 API入门系列之wordcount版本4(八)的更多相关文章
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之wordcount版本5(九)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount1; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之wordcount版本3(七)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount3; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount4; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
随机推荐
- Java中final,finally和finalize区别
Day11_SHJavaTraing_4-18-2017 Java中final,finally和finalize区别 1.final—修饰符(关键字) ①final修饰类,表示该类不可被继承 ②fin ...
- uni-app判断各大平台的语法
uni-app是一款强大的前端框架,它除了pc端其他都可以实现,打包原生app.手机h5页面,微信小程序, 但是有一个问题就是本生的app和微信小程序是有一定的区别的,因为app有标题栏,返回键,而微 ...
- 使用.Net Core RT 标准动态库
这个文档可以引导你如何通过CoreRT生成一个原生标准的系统动态库让其他编程语言调用. CoreRT 可以构建静态库, 这些库可以在编译时链接或者也可以构建运行时所需的共享库, 创建一个支持CoreR ...
- mysql 是如何保证在高并发的情况下autoincrement关键字修饰的列不会出现重复
转载自 https://juejin.im/book/5bffcbc9f265da614b11b731/section/5c42cf94e51d45524861122d#heading-8 mysql ...
- idea搭建第一个springboot
1.打开idea开发工具,在菜单栏选择File-->New-->Project...-->Spring Initializer说明:社区版的idea是没有Spring Initial ...
- 通俗易懂之SpringMVC&Struts2前端拦截器详解
直接进入主题吧!一,配置Struts2的拦截器分两步走1配置对应的拦截器类:2在配置文件Struts.xml中进行配置拦截器同时在Strust2中配置拦截器类有三种方法1实现Interceptor接口 ...
- PHP共享内存
如何使用 PHP shmop 创建和操作共享内存段,使用它们存储可供其他应用程序使用的数据. 1. 创建内存段 共享内存函数类似于文件操作函数,但无需处理一个流,您将处理一个共享内存访问 ID.第一个 ...
- BZOJ 1572: [Usaco2009 Open]工作安排Job 贪心 + 堆 + 反悔
Description Farmer John想修理牧场栅栏的某些小段.为此,他需要N(1<=N<=20,000)块特定长度的木板,第i块木板的长度为Li(1<=Li<=50, ...
- 软件工程1916|W(福州大学)_助教博客】团队Beta冲刺作业(第9次)成绩公示
1. 作业链接: 项目Beta冲刺(团队) 2. 评分准则: 本次作业包括现场Beta答辩评分(映射总分为100分)+团队互评分数(总分40分)+博客分(总分130分)+贡献度得分,其中博客分由以下部 ...
- 【VIP视频网站项目一】搭建视频网站的前台页面(导航栏+轮播图+电影列表+底部友情链接)
首先来直接看一下最终的效果吧: 项目地址:https://github.com/xiugangzhang/vip.github.io 在线预览地址:https://xiugangzhang.githu ...