windows下IntelliJ IDEA搭建kafka源码环境
于kafka核心原理的资料,网上有很多,但是如果不自己研究其源码,永远是知其然而不知所以然。下面就来演示如何在windows环境下来编译kafka源码,并通过IntelliJ IDEA开发工具搭建kafka的源码环境,以方便在本地通过debug调试来研究kafka的内部实现机制。
具体步骤:
(1)安装jdk,版本为1.8.0_131,配置JAVA_HOME:

(2)安装scala,版本为 2.10.6,配置SCALA_HOME:

(3)安装Gradle,版本为 3.1,配置GRADLE_HOME:
(4)安装Maven,版本为 3.2.1,配置MAVEN_HOME:

(5)安装zookeeper,版本为3.4.6(这里为了方便,只在windows下部署了一个单节点的zookeeper,当然你也可以部署一个zookeeper集群)
到zookeeper官网下载压缩包,解压到windows的任意磁盘目录下,将conf目录下的zoo_sample.cfg复制一份,将其名称修改为zoo.cfg,然后打开,指定dataDir=D:\\java\\zookeeper-data\\3.4.6-data,比如我的配置如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=D:\\java\\zookeeper-data\\3.4.6-data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
然后双击bin目录下的zkServer.cmd即可启动zookeeper:
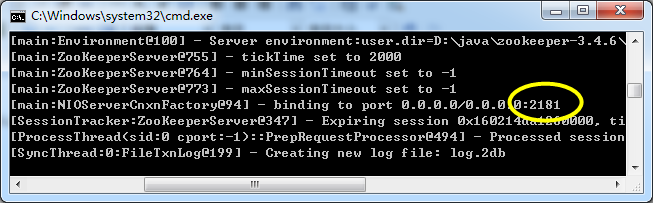
zookeeper启动后如下图,默认占用的端口号为2181:
(6)下载kafka源码。从kafka官网下载源码包kafka-0.10.0.1-src.tgz,解压,比如我解压到了D:\kafka-0.10.0.1-src目录下,在解压后的目录下面通过命令行窗口执行gradle idea命令,然后经过漫长的等待,控制台会出现构建成功的提示,说明kafka源码编译完成;
(7)开发工具使用的是IntellJ IDEA 14.1.7(也可以使用其他更高的版本):

(8)在IntelliJ IDEA中安装scala插件,这里我安装的插件版本为 1.5.4:
(9)将编译好的kafka源码导入到idea开发工具中,导入后的目录情况:
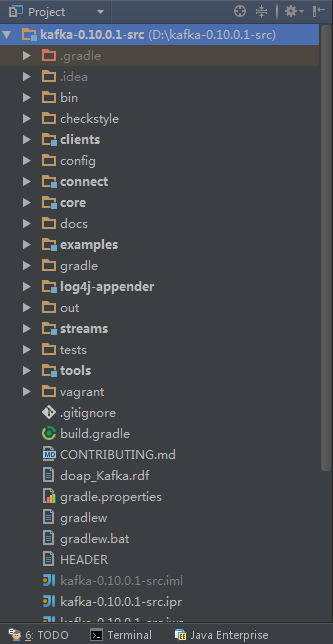
(10)将config目录下的log4j.properties文件拷贝到core\src\main\scala\目录下,方便查看日志:
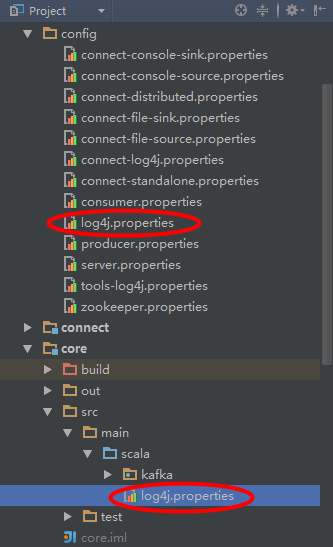
(11) 修改server.properties文件中的log.dirs=D:\\tmp\\kafka-logs(修改为你自己windows磁盘目录)
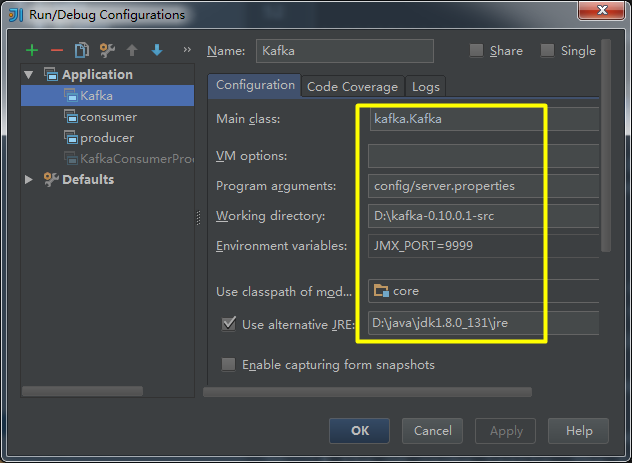
(12)启动kafka服务器,即运行core\src\main\scala\kafka\Kafka.scala中的main方法,运行前指定启动参数:
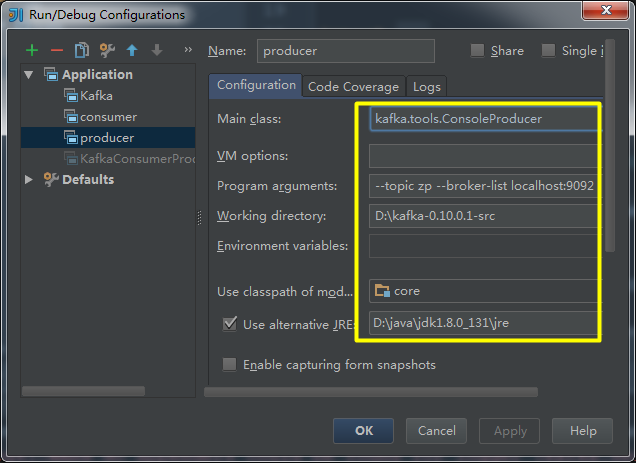
(13)启动生产者,启动参数配置:
(14)启动消费者,启动参数配置:
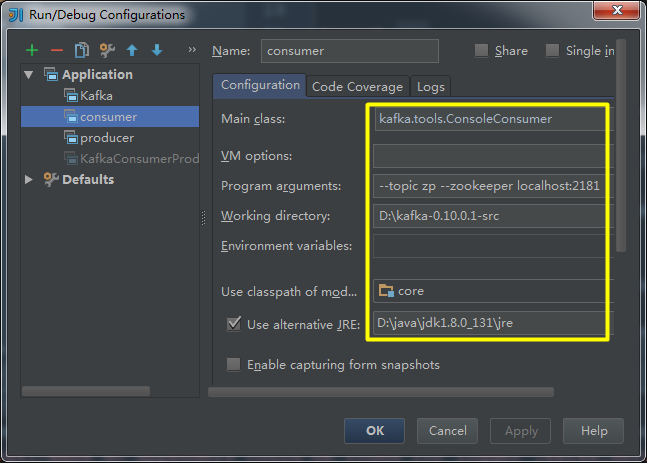
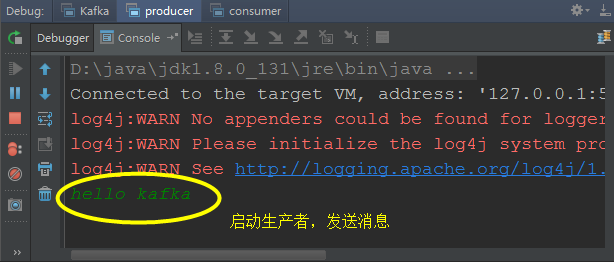
(15)在生产者的控制台上输入消息"hello kafka"并回车:
观察消费者的控制台上,如果有消息被消费,说明源码环境搭建成功:
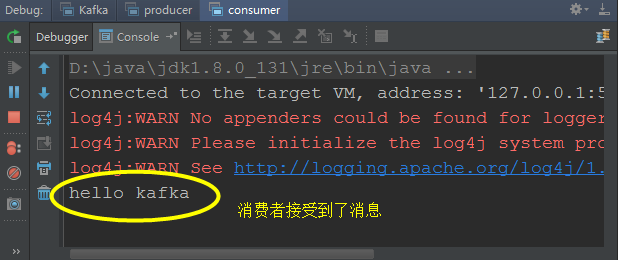
致此,kafka在IntelliJ IDEA中的源码环境搭建成功。
windows下IntelliJ IDEA搭建kafka源码环境的更多相关文章
- 使用IntelliJ IDEA搭建kafka源码环境时遇到Output path错误解决办法
kafka源码环境搭建好之后,需要在IntelliJ IDEA开发工具中以debug方式启动kafka服务器来测试消息的生产和消费. 但是在启动kafka.Kafka类中的main方法(也就是运行 k ...
- Linux Kafka源码环境搭建
本文主要讲述的是如何搭建Kafka的源码环境,主要针对的Linux操作系统下IntelliJ IDEA编译器,其余操作系统或者IDE可以类推. 1.安装和配置JDK确认JDK版本至少为1.7,最好是1 ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- intellij idea 编译 kafka 源码
1. 从 GitHub 网站,git clone kafka 源码 2. 下载安装好 gradle,scala 3. 进入 kafka 项目目录,依次执行 gradle wrapper,gradle ...
- 搭建kafka源码开发环境时使用"gradle idea"命令构建源码失败
我的环境: JDK: 1.8.0_131 Gradle: Gradle 3.1 Kafka源码包: kafka-0.10.0.1-src.tgz Zookeeper安装包: zookeeper-3.4 ...
- [原创]在Windows和Linux中搭建PostgreSQL源码调试环境
张文升http://ode.cnblogs.comEmail:wensheng.zhang#foxmail.com 配图太多,完整pdf下载请点这里 本文使用Xming.Putty和VMWare几款工 ...
- Windows下用Git下载android源码 转载
http://my.oschina.net/jiadebin/blog/52631 1.首先你的电脑要安装好git,这个请参考git官网. 2.打开git命令窗口输入git clone http:// ...
- 在windows下执行./configure,make,makeinstall源码安装程序spice-gtk
使用MSYS软件,在我的上一篇博客中有软件下载地址.本文使用MSYS进行源码编译spice-gtk-0.33. 首先打开MSYS软件,进入你源码所在目录,例如:cd /c/Users/Admi... ...
- Ubuntu搭建Spring源码环境常见问题
在一心想要学习Spring框架源码时,我们会遇到很多麻烦的问题.开始本文前,你只需要拥有一个装好IDEA的Ubuntu系统就可以愉快启程了.如果还没有IDEA,可以参考在Ubuntu上安装Intell ...
随机推荐
- linux(ubuntu) 查看系统设备信息 命令
时间:2012-08-02 00:12 ubuntu查看版本命令 方法一: 在终端中执行下列指令: cat /etc/issue 方法二: 使用 lsb_release 命令也可以查看 Ubunt ...
- SpringBoot开发项目,引入JPA找不到findOne方法
写在前面 开发SpringBoot的DAO层之后,去测试的时候,发现findOne()这个方法找不到了,查看了对应的表字段名和实体类的属性都一致 网上有通过降低版本解决的, 方式太牵强. 还有一种方式 ...
- Mysql DBA 20天速成教程
Mysql DBA 20天速成教程 基本知识1.mysql的编译安装2.mysql 第3方存储引擎安装配置方法3.mysql 主流存储引擎(MyISAM/innodb/MEMORY)的特点4.字符串编 ...
- Git 远程仓库(分布式版本控制系统)
前言 远程仓库是指托管在因特网或其他网络中的你的项目的版本库.你可以有好几个远程仓库,通常有些仓库对你只读,有些则可以读写. 1.查看远程仓库 如果想查看你已经配置的远程仓库服务器,可以运行 git ...
- 【Linux】数据流重导向(前篇)
数据流重导向 (redirect) 由字面上的意思来看,好像就是将『数据给他传导到其他地方去』的样子? 没错-数据流重导向就是将某个命令运行后应该要出现在屏幕上的数据, 给他传输到其他的地方,例如文件 ...
- easyui textbox combobox 设置只读不可编辑状态
输入框 textbox $("#xx").textbox('setValue','value'); //设置输入框的值 $('#xx').textbox('textbox').a ...
- SQL Tuning Advisor
SQL Tuning Advisorsql调优顾问可提供的建议有:-收集对象的统计信息-创建索引-重写sql语句-创建sql profile-创建sql plan baseline SQL Tunin ...
- 常用代码之四:创建jason,jason转换为字符串,字符串转换回jason,c#反序列化jason字符串的几个代码片段
1.创建jason,并JSON.stringify()将之转换为字符串. 直接使用var customer={}, 然后直接customer.属性就可以直接赋值了. 也可以var customer = ...
- Python 爬虫 大量数据清洗 ---- sql语句优化
. 问题描述 在做爬虫的时候,数据量很大,大约有五百百万条数据,假设有个字段是conmany_name(拍卖公司名称),我们现在需要从五百万条数据里面查找出来五十家拍卖公司, 并且要求字段 time( ...
- Talend open studio如何调试代码
Talend将设计的模型直接生成了java代码,可以直接对模型生成的java代码进行调试,排查问题比kettle灵活很多, 设计的模型如下: 生成的代码如下: 点击 Java Debug进入调试模式, ...