lucene4 Filter
摘要: 关于过滤方面的知识,也就是Filter,如果了解Solr的朋友们,肯定都会知道Solr里面fq这个参数,这个参数的作用其实就是lucene里面的过滤,对一些q参数查询的结果集,做过滤或者限制返回一些我们需要的内容,可以理解成缩小搜索空间的一种策略。
先介绍下查询与过滤的区别和联系,其实查询(各种Query)和过滤(各种Filter)之间非常相似,可以这样说只要用Query能完成的事,用过滤也都可以完成,它们之间可以相互转换,最大的区别就是使用过滤返回的结果集不带评分操作,而使用Query返回的结果都是带相关性评分的,所以当我们如果有一些跟评分操作没有关系的业务,优先使用Filter操作,将会获取更好的性能,其实这也是Solr里面的q参数跟fq参数的区别。
下面,开始进入正题,在这之前,老生常谈的先来了解一下Lucene里面有关于Filter的整体知识
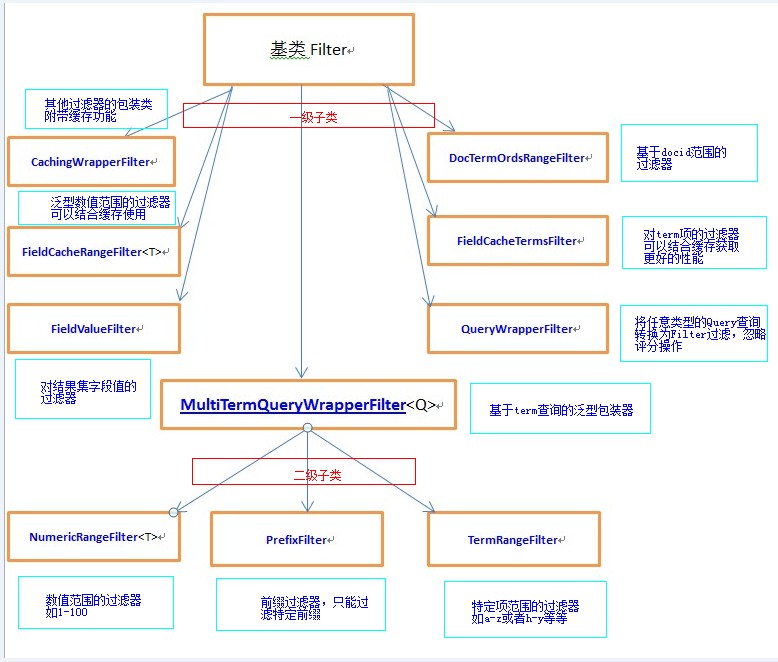
下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据
id score bookname ename type price date
1 1 飘渺之旅 pmzl 小说 52.23 201005
2 1 三国演义 sgyy 小说 36.13 201207
3 1 数据库实战 sjksz 技术 77.13 200811
4 1 编程宝典 bcbd 技术 100.3 200501
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用过滤器 最后一个为true时包含边界部分,为false时不包含边界部分
//倒数第二个为true时,包含查询边界,为false时不包含
TermRangeFilter filter=new TermRangeFilter("ename", new BytesRef("h"), new BytesRef("n"), true, true);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
核心代码
NumericRangeFilter<Double> filter=NumericRangeFilter.newDoubleRange("price", 10D, 40D, true, false);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用缓存过滤
Filter filter=FieldCacheRangeFilter.newDoubleRange("price", 20D, 50D, true, true);
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
5 1 职场关系论 zcgxl 职场 36.59 200501
6 1 健康生活 jksh 生活 20.47 200008
核心代码
// 缓存域过滤特定的类别
Filter filter=new FieldCacheTermsFilter("type", new String[]{"技术","社会"});
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
3 1 数据库实战 sjksz 技术 77.13 200811
4 1 编程宝典 bcbd 技术 100.3 200501
7 1 看清本质 kqbz 社会 10.37 201004
8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
//使用QueryWrapperFilter类包装一个Query
QueryWrapperFilter filter=new QueryWrapperFilter(new TermQuery(new Term("type", "技术")));
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
//使用QueryWrapperFilter类包装一个Query
QueryWrapperFilter filter=new QueryWrapperFilter(new TermQuery(new Term("type", "技术")));
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
最后我来看下,如何继承Filter基类,来定制我们自己的filter,自定义的Filter,虽然某些时候,功能很强大灵活,但是有几个缺点,我们的了解1,保证是内容不重复的字段,例如主键,如果重复,默认返回第一个作为结果集显示2,保证不能被分词的内容,如果是分词的字段,则可能会出现一些不正确的结果。
自定义Filter类
package com.sanjiesanxian.test; import java.io.IOException;
import java.util.BitSet; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.index.AtomicReaderContext;
import org.apache.lucene.index.DocsEnum;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.DocIdSet;
import org.apache.lucene.search.Filter;
import org.apache.lucene.util.AttributeSource;
import org.apache.lucene.util.Bits;
import org.apache.lucene.util.DocIdBitSet;
import org.apache.lucene.util.FixedBitSet;
import org.apache.lucene.util.OpenBitSet; /***
*^_^ ^_^ ^_^
* QQ交流探讨群:324714439
* 自定义过滤器
* @author 三劫散仙
* */
public class MyCustomFilter extends Filter{ public MyCustomFilter() {
// TODO Auto-generated constructor stub
} private String[] terms;//限制返回的数据字典
public MyCustomFilter(String ...terms) {
// TODO Auto-generated constructor stub
this.terms=terms;
}
@Override
public DocIdSet getDocIdSet(AtomicReaderContext arg0, Bits arg1)
throws IOException {
FixedBitSet bits=new FixedBitSet(arg0.reader().maxDoc()) ;//获取没有所有的docid包括未删除的
int base=arg0.docBase;//段的相对基数,保证多个段时相对位置正确
//int limit=base+arg0.reader().maxDoc();//计算最大限制值
for(String s:terms){
DocsEnum doc=arg0.reader().termDocsEnum(new Term("id", s));//必须是唯一的不重复
//保证是单个不重复的term,如果重复的话,默认会取第一个作为返回结果集,分词后的term也不适用自定义term
if(doc.nextDoc()!=-1){
bits.set(doc.docID());//对付符合条件约束的docid循环添加到bits里面
}
}
return bits;
}
}
测试查询代码
MyCustomFilter filter=new MyCustomFilter("3","5","2");//随意指定1之多个需要过滤的项
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);
输出结果
2 1 三国演义 sgyy 小说 36.13 201207
3 1 数据库实战 sjksz 技术 77.13 200811
5 1 职场关系论 zcgxl 职场 36.59 200501
自定义过滤器虽然有缺点,但是某些场景下却能发挥很灵活的作用,特别是对没有分词的字段进行过滤操作。
lucene4 Filter的更多相关文章
- django 操作数据库--orm(object relation mapping)---models
思想 django为使用一种新的方式,即:关系对象映射(Object Relational Mapping,简称ORM). PHP:activerecord Java:Hibernate C#:Ent ...
- 【课程分享】基于Lucene4.6+Solr4.6+Heritrix1.14+S2SH实战开发从无到有垂直搜索引擎
对这个课程有兴趣的朋友,能够加我的QQ2059055336和我联系,能够和您分享. 课程介绍:最有前途的软件开发技术--搜索引擎技术 搜索引擎作为互联网发展中至关重要的一种应用,已经成为互联网各个 ...
- Lucene4.6至 Lucene6.6的每个迭代对API的改动
由于项目需求,需要将Lucene4.6升级到Lucene6.6,因此我对这之间的所有重要的API改动做了搜集:特别重要的改变加粗显示. Lucene4.7改动: LUCENE-5405: Make S ...
- Lucene4.6 把时间信息写入倒排索引的Offset偏移量中,并实现按时间位置查询
有个新的技术需求,需要对Lucene4.x的源码进行扩展,把如下的有时间位置的文本写入倒排索引,为此,我扩展了一个TimeTokenizer分词器,在这个分词器里将时间信息写入 偏移量Offset中. ...
- JavaWeb——Filter
一.基本概念 之前我们用一篇博文介绍了Servlet相关的知识,有了那篇博文的知识积淀,今天我们学习Filter将会非常轻松,因为Filter有很多地方和Servlet类似,下面在讲Filter的时候 ...
- 以bank account 数据为例,认识elasticsearch query 和 filter
Elasticsearch 查询语言(Query DSL)认识(一) 一.基本认识 查询子句的行为取决于 query context filter context 也就是执行的是查询(query)还是 ...
- AngularJS过滤器filter-保留小数,小数点-$filter
AngularJS 保留小数 默认是保留3位 固定的套路是 {{deom | number:4}} 意思就是保留小数点 的后四位 在渲染页面的时候 加入这儿个代码 用来精确浮点数,指定小数点 ...
- 挑子学习笔记:特征选择——基于假设检验的Filter方法
转载请标明出处: http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html Filter ...
- Lucene4.4.0 开发之排序
排序是对于全文检索来言是一个必不可少的功能,在实际运用中,排序功能能在某些时候给我们带来很大的方便,比如在淘宝,京东等一些电商网站我们可能通过排序来快速找到价格最便宜的商品,或者通过排序来找到评论数最 ...
随机推荐
- [JavaScript] - 7kyu
Johnny is a boy who likes to open and close lockers. He loves it so much that one day, when school w ...
- 使用caffenet微调时的一些总结
1,比较笨的方法生成图片列表(两类举例)data/myself/train 目录下 find -name cat.\*.jpg |cut -d '/' -f2-3 >train.txtsed - ...
- HDU 5961 传递
http://acm.hdu.edu.cn/showproblem.php?pid=5961 题意: 思路: 话不多说,直接暴力. #include<iostream> #include& ...
- ASCII 、UTF-8、Unicode都是个啥啊,为啥会乱码啊?
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制1111 ...
- ubuntu server 16.04(amd 64) 配置网桥,多网卡使用激活
安装了Ubuntu16.04的server版本,结果进入系统输入ifconfig后发现,只有一个网卡enp1s0,还有一个网络回路lo,ifconfig -a 发现其实一共有四个网卡,enp1s0,e ...
- Could NOT find SDL_image (missing:SDL_IMAGE_LIBRARIES SDL_IMAGE_INCLUDE_DIRS)
sudo apt-get install libsdl-image1.2-dev
- Linux 下的profile
# /etc/profile # System wide environment and startup programs, for login setup# Functions and aliase ...
- Java8 新特性之默认接口方法
摘要: 从java8开始,接口不只是一个只能声明方法的地方,我们还可以在声明方法时,给方法一个默认的实现,我们称之为默认接口方法,这样所有实现该接口的子类都可以持有该方法的默认实现. · 待定 一. ...
- 【Robot Framework 项目实战 02】SeleniumLibrary Web UI 自动化
前言 SeleniumLibrary 是针对 Robot Framework 开发的 Selenium 库.它也 Robot Framework 下面最流程的库之一.主要用于编写 Web UI 自动化 ...
- RabbitMQ入门_11_DLX
参考资料:https://www.rabbitmq.com/dlx.html 队列中的消息可能会成为死信消息(dead lettered).让消息成为死信消息的事件有: 消息被取消确认(nack 或 ...