MapReduce – 基本思路之推荐引擎
理解MapReduce关键两个步骤;
首先是构想出结构的数据结构,这种数据结构可以支撑你的业务分析使用;是要理解这种模式的处理元素。
第二步,分析原始数据的结构是怎样的;
第三步,基于原始数据结构以及目标数据结构,在分析map的实现逻辑,返回值什么,sort-shuffle之后的值什么,这个值也是reduce的入口参数,然后是reduce的逻辑是什么,以符合目标结构;
map和reduce在处理数据上面的很大差别在于map之后会有一个汇总过程,按照key进行汇聚(发生在sort-shuffle阶段);reduce产生的数据不会再有这个过程,产生的是什么数据,加入到集合中之后,这个数据集合再无其他操作;如果再次把这个数据集合作为下一个阶段的Map-Reduce。
对于"购买过该商品的用户还购买了哪些商品",这个需求,分析过程如下:
0. 目标数据结构是:key:商品(主体);value:关联商品+权值(数量)列表;
1. 实现要明白map的入口参数是什么样子,用户对应一个商品;
2. 分析一下map之后数据,是一个商品对应多个商品;
3. shuffle没有什么特别处理;
3. reduce没有什么特别处理;
下面是第二轮mapreduce:
1. 入口参数是一个用户对多个商品;
2. map返回值某个用户的某个商品对应多个相关联的商品;
3. map之后shuffle合并是个集合,集合中的元素是:key是某个商品,value是相关联的商品List,此时这个list里面可能会有很多重复项;
4. reduce的入口参数是上步中介绍的内容;reduce处理之后,变成了key:某个商品;value:关联商品以及该商品的累加个数;
下面的是应用:基于reduce处理的数据,我们可以获得某个商品关联度最高的前N个商品(累加个数最高的N的)
处理的全流程如下图所示:
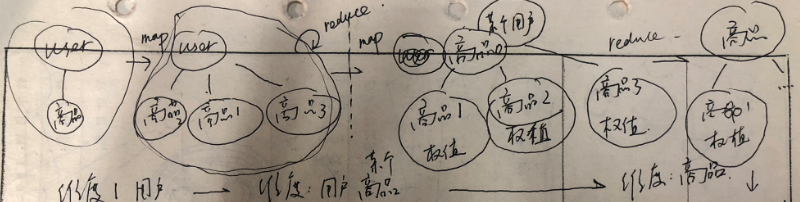
注意其实处理的维度的变化,阶段1map的处理维度还是在user;到了阶段儿的map处理维度是用户+商品,到了阶段2的reduce就抛弃了用户了,而是完全在商品的维度了;reduce的一个功能就是"降维",这个是我的一个说法,其实"降维"是指原本的key不管了,而是从value中在建立一套key-value数据结构;因为reduce功能是group,group意味着可以抛弃一个数据维度,或者说忽略某些个数据维度。
继续,对于"经常一起购买的商品":
0. 构想目标数据结构:key:商品;value:关联商品+权值列表;
1. 你要原始的数据集合中,一条记录的结构是交易-产品列表;
2. 在map阶段,直接"降维",抛弃key(交易ID),对于产品列表做两两配对;shuffle之后的数据集合的元素结构是[<p1,p2>, 1];
3. 到了reduce阶段,就是按照<p1, p2>进行汇聚,输出的是数据集合的元素结构是[<p1, p2>, n];
应用:
找到p1=XX,n最高的3个产品作为推荐。
第三波,难度比较大了,推荐好友,A和B是好友,B是C的好友,那么AC要双向推荐一下。
我最初的想法是做差集;A-B的人向B做推荐,B-A的人想A做推荐;但是这样算法无法获取共同好友,我们登录QQ看到推荐的时候,一般都会看到你和以下人是好友;
0. 构想目标数据结构,key:主体人,value:[推 荐者,List<共同好友>]
1. 原始数据结构:key:主体人,value:List<Friends>
2. map输出的是key:被推荐人;value:[推荐好友, 共同好友(入参的主体人)];shuffle之后是key是推荐人;value推荐好友列表;
3. reduce逻辑则是将被推荐人的推荐好友叠加到List中,同时叠加该推荐好友的共同朋友;
MapReduce – 基本思路之推荐引擎的更多相关文章
- PredictionIO+Universal Recommender快速开发部署推荐引擎的问题总结(3)
PredictionIO+Universal Recommender虽然可以帮助中小企业快速的搭建部署基于用户行为协同过滤的个性化推荐引擎,单纯从引擎层面来看,开发成本近乎于零,但仍然需要一些前提条件 ...
- 简易推荐引擎的python实现
代码地址如下:http://www.demodashi.com/demo/12913.html 主要思路 使用协同过滤的思路,从当前指定的用户过去的行为和其他用户的过去行为的相似度进行相似度评分,然后 ...
- 机器学习 101 Mahout 简介 建立一个推荐引擎 使用 Mahout 实现集群 使用 Mahout 实现内容分类 结束语 下载资源
机器学习 101 Mahout 简介 建立一个推荐引擎 使用 Mahout 实现集群 使用 Mahout 实现内容分类 结束语 下载资源 相关主题 在信息时代,公司和个人的成功越来越依赖于迅速 ...
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- 从源代码剖析Mahout推荐引擎
转载自:http://blog.fens.me/mahout-recommend-engine/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pi ...
- 基于Azure构建PredictionIO和Spark的推荐引擎服务
基于Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://po ...
- [转] 基于 Apache Mahout 构建社会化推荐引擎
来源:http://www.ibm.com/developerworks/cn/java/j-lo-mahout/index.html 推荐引擎简介 推荐引擎利用特殊的信息过滤(IF,Informat ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- JVM调优(这里主要是针对优化基于分布式Mahout的推荐引擎)
优化推荐系统的JVM关键参数 -Xmx 设定Java允许使用的最大堆空间.例如-Xmx512m表示堆空间上限为512MB -server 现代JVM有两个重要标志:-client和-server,分别 ...
随机推荐
- Android将view保存为图片并放在相册中
在Android中,可以将view保存为图片并放在相册中,步骤为 view->bitmap->file,即先将view转化为bitmap,再将bitmap保存到相册中. 需要将红框标注的v ...
- pytorch人脸识别——自己制作数据集
这是一篇面向新手的博文:因为本人也是新手,记录一下自己在做这个项目遇到的大大小小的坑. 按照下面的例子写就好了 import torch as t from torch.utils import da ...
- OAF中下载附件之后页面失效,报过时的数据异常,浏览器后退异常
我在使用了下载功能之后,再往页面添加行或进行保存,页面老是报浏览器后退的异常. 猜测是因为我的下载按钮使用的submitButton,它隐式的包含了一个submit动作,且我在代码中有一个Commit ...
- quartz---的一个简单例子
quartz---的一个简单例子 首先建立一个maven项目.jar工程即可.(提示:我前面有如何建立一个maven工程的总结以及maven环境的配置.) 1.建立好后点击到app中运行,--> ...
- SMTP 通过 ssh 通道发送垃圾邮件
通过SSH隧道传输SMTP 根据设计,我们不允许校外机器使用我们的SMTP服务器.如果我们允许它,我们将允许任何和所有使用我们的SMTP服务器来分发垃圾邮件.但是也可以通过我们的SMTP服务器发送邮件 ...
- jsp jsp传统标签开发
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- spoj8406
题解: 二分+树状数组 记录以下i在当前拍第几 代码: #include<bits/stdc++.h> using namespace std; ; int a[N],f1[N],f2[N ...
- 玩转X-CTR100 | X-PrintfScope波形显示
我造轮子,你造车,创客一起造起来!塔克创新资讯[塔克社区 www.xtark.cn ][塔克博客 www.cnblogs.com/xtark/ ] X-CTR100控制器配套的X-Print ...
- Java学习图谱
学习图谱 一:常见模式与工具 二:分布式架构 三:微服务架构 四:底层知识 五:性能优化 六:工程化与工具
- USER 版本与ENG 版本差异
[Description] Android USER 版本与ENG 版本的差异 [Keyword] USER ENG user eng 用户版本 工程版本 差异 [Solution] Goog ...