数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友。
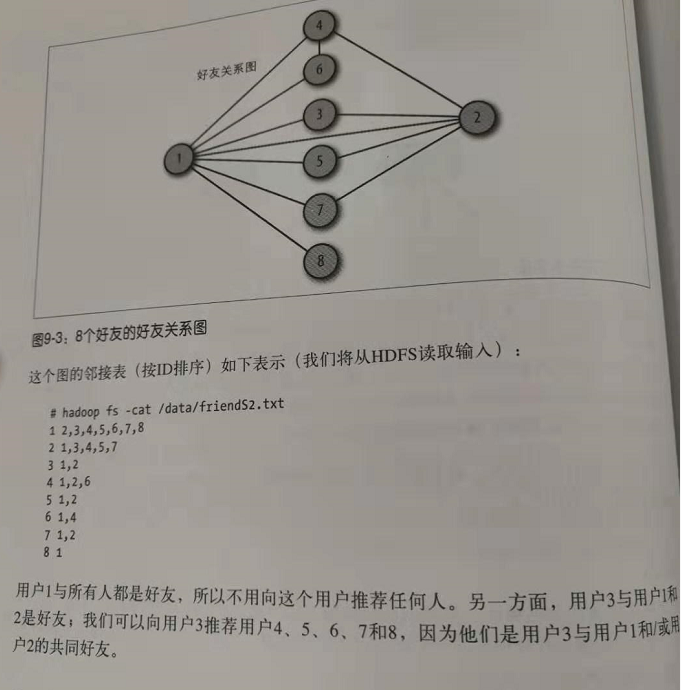
在所有用户对中找出“共同好友”。
eg:
a b,c,d,g
b a,c,d,e
map()-》 <a,b>,<b,c,d,g> ;<a,c>,<b,c,d,g>;.....
<a,b>,<a,c,d,e>
reduce()-> <a,b>,<c,d> 也就是a,b的共同好友是c,d。
上述就是思想。
八,使用MR实现推荐引擎
1.购买过该商品的顾客还购买了哪些商品。
这里,利用MR的两次迭代实现CWBTIAB功能。
阶段1:生成同一个用户购买的所有商品列表。分组由HAdoop框架处理,其中映射器和规约器都会完成一个恒等函数。
阶段2:解决列表商品的共现问题。使用Stripes(条纹)设计模式,只发出5个最常见的商品。


2.经常一起购买的商品(FBT)

3.推荐连接
解决方案(实现思路):


数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)的更多相关文章
- 数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五.移动平均 多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均.之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删 ...
- 数据算法 --hadoop/spark数据处理技巧 --(1.二次排序问题 2. TopN问题)
一.二次排序问题. MR/hadoop两种方案: 1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序.这种方法不具有可伸缩性,因 ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
- 数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三. 左外连接 考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易.假设我们有两类数据,用户和交易: users(user_id,location_id) transactions( ...
- 数据算法 --hadoop/spark数据处理技巧 --(17.小文件问题 18.MapReuce的大容量缓存)
十七.小文件问题 十八.MR的大容量缓存 在MR中使用和读取大容量缓存,(也就是说,可能包括数十亿键值对,而无法放在一个商用服务器的内存中).本次提出的算法通用,可以在任何MR范式中使用.(eg:MR ...
- 数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
十一.k-均值聚类 这个需要MR迭代多次. 开始时,会选择K个点作为簇中心,这些点成为簇质心.可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点.一旦选择了K个初始的簇质心,下 ...
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
- 数据算法 --hadoop/spark数据处理技巧 --(15.查找、统计和列出大图中的所有三角形 16.k-mer计数)
十五.查找.统计和列出大图中的所有三角形 第一步骤的mr: 第二部mr: 找出三角形 第三部:去重 spark: 十六: k-mer计数 spark:
- 哈,我自己翻译的小书,马上就完成了,是讲用python处理大数据框架hadoop,spark的
花了一些时间, 但感觉很值得. Big Data, MapReduce, Hadoop, and Spark with Python Master Big Data Analytics and Dat ...
随机推荐
- 微信小程序--百度地图坐标转换成腾讯地图坐标
最近开发小程序时出现一个问题,后台程序坐标采用的时百度地图的坐标,因为小程序地图时采用的腾讯地图的坐标系,两种坐标有一定的误差,导致位置信息显示不正确.现在需要一个可以转换两种坐标的方法,经过查询发现 ...
- Spring-cloud微服务实战【二】:eureka注册中心(上)
## 前言 本系列教程旨在为大家演示如何一步一步构建一整套微服务系统,至于其中的数据库用什么,订单ID如何保持唯一,分布式相关问题等等不在我们讨论范围内,本教程为了方便大家后续下载代码运行测试,不 ...
- DP- 01背包问题
这个01背包 , 理解了一天才勉强懂点 , 写个博客 ( 推荐 http://blog.csdn.net/insistgogo/article/details/8579597) 题目 : 有N ...
- Oracle安装连接常见错误
oracle安装注意:安装路径url不能带中文C:\app\59428\product\11.2.0\dbhome_1\sqldeveloper打开sqldeveloper的时候,需要输入java.e ...
- 8.JavaSE之变量、常量、作用域
变量variable: 变量是什么:就是内存中开辟的可以变化的量! Java是一种强类型语言,每个变量都必须声明其类型. Java变量是程序中最基本的存储单元,其要素包括变量名,变量类型,作用域 ...
- hdu4841
今天天气确实很好! 接下来是圆桌问题,顺便做个vector容器的笔记方便以后复习.嘿嘿 Problem Description圆桌上围坐着2n个人.其中n个人是好人,另外n个人是坏人.如果从第一个人开 ...
- 【WPF学习】第十三章 理解路由事件
每个.NET开发人员都熟悉“事件”的思想——当有意义的事情发生时,由对象(如WPF元素)发送的用于通知代码的消息.WPF通过事件路由(event routing)的概念增强了.NET事件模型.事件路由 ...
- 常用API_1
API API(Application Programming Interface),应用程序编程接口.Java API是一本程序员的 字典 ,是JDK中提供给 我们使用的类的说明文档.这些类将底层的 ...
- SEO 搜索 形成一个关联
- 英语学习app——Alpha发布2
英语学习app--Alpha发布1 这个作业属这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/GeographicInformationScience/ ...