【自动化测试&爬虫系列】Selenium Webdriver
文章来源:公众号-智能化IT系统。
一. Selenium Webdriver技术介绍
1. 简介
selenium Webdriver是一套针对不同浏览器而开发的web应用自动化测试代码库。使用这套库可以进行页面的交互操作,并且可以重复地在不同浏览器上进行各种测试操作。
以python为例,在cmd输入python-m pip install selenium --upgrade pip进行安装。
2. 特点
开源免费
支持多种语言:Java、Python、Ruby、C#、JavaScript、C++等。
直接让测试工具调用浏览器和操作系统本身提供的内置方法,以此绕过JavaScript环境的沙盒限制。
支持多种浏览器。包括:Chrome、ie6-11、Firefox大部分版本、Mac操作系统的Safari默认版本、Opera、HtmlUnit、Android手机操作系统的默认浏览器、iOS手机操作系统的默认浏览器。
3. 实现原理
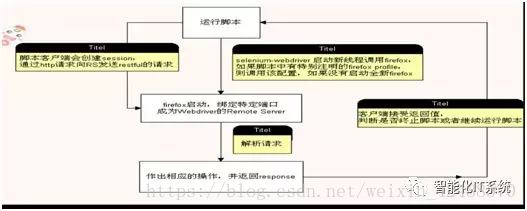
如图,测试脚本作为客户端,在运行脚本的时候,
调用浏览器各自的webdriver(如Firefox的geckodriver)并创建session
webdriver启动浏览器,并绑定某端口成为Webdriver的Remote Server(作为服务端)
测试脚本发送基于selenium自己设计的The WebDriverWire Protocol协议的命令请求到Remote Server(这套协议几乎可以操作浏览器做任何事情,如打开、关闭、最大化、最小化、元素定位、元素点击、上传文件等。)
Remote Server将Web Service的命令转化成浏览器native的调用,在浏览器中找到元素的坐标位置,并在这个坐标点触发一个鼠标或键盘操作,从而操作浏览器。
4. 基本的元素定位方式
根据上述的实现原理,可知用selenium对浏览器进行页面操作的关键就是定位出页面上相应的元素,然后发送基于selenium自己设计的The WebDriver Wire Protocol协议的命令请求。
浏览器中,按F12或者各个浏览器提供的开发者工具,可查看页面元素。
Selenium提供了八种定位方式:
--id定位
§用法:find_element_by_id(“id对应的值”)
--name定位
§用法:find_element_by_name(“name对应的值”)
--class定位
§用法:find_element_by_class_name(“class对应的值”)
--tag定位
§用法:find_element_by_tag_name(“tag对应的值”)
--link定位(用于定位文本链接)
§用法:find_element_by_link_text(“链接的文本内容”)
--partial link定位(link定位的补充,可取链接部分文本内容进行定位)
§用法:find_element_by_partial_link_text(“链接的部分文本内容”)
--XPath定位
§用法:find_element_by_xpath(“xpath的值,可选中元素后,鼠标右键复制xpath”)
--CSS定位
§用法:find_element_by_css_selector(“CSS路径,同样可选中元素后,鼠标右键复制CSS路径”)
还可以用By定位元素(其实就是8种定位方法的另一种较灵活的写法):
--统一调用find_element()方法,通过By来声明定位方法(前面提到的8中定位方法),并传入对应定位方法的定位参数。
§用法:find_element(By.定位方法,“定位参数”)
e.g. find_element(By.ID,“txtAcc”)
二. Linux服务器环境部署注意事项
桌面环境使用Selenium默认会打开浏览器界面,但是如果要部署到无桌面环境的服务器环境,使用普通方法没法运行Selenium。解决方法有:
使用HtmlUnitDriver或者PhantomJSDriver
使用XVFB(X virtual frame buffer)虚拟显示服务器,不需要借助任何显示设备,在内存中执行所有的图形操作。
本文采用安装Xvfb的方式。部署步骤如下:
1. 安装pyvirtualdisplay
pip install pyvirtualdisplay
2. 安装Xvfb(作为后端)
yum install xorg-x11-server-Xvfb
3. 安装Firefox
cd /usr/local
Wget https://ftp.mozilla.org/pub/firefox/releases/56.0.2/linux-x86_64/en-US/firefox-56.0.2.tar.bz2
tar xjvf firefox-56.0.2.tar.bz2
ln -s /usr/local/firefox/firefox /usr/bin/firefox
4. 下载geckodriver
wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz
5. 解压geckodriver-v0.19.1-linux64.tar.gz
tar xvzf geckodriver-*.tar.gz
6. 在环境变量目录/usr/bin/中添加geckodriver的硬链接
ln -s /usr/local/geckodriver /usr/bin/geckodriver
7. 测试脚本中添加代码
导入Display模块
from pyvirtualdisplay import Display
在创建webdriver实例前,设置Display环境变量。visible传0表示使用Xvfb作为后端,size传的参数就是设置浏览器页面大小。
Display = Display(visible=0, size=(1280, 1024))
启动虚拟显示服务
Display.start()
执行完用例后,关闭浏览器后,也需要终止Xvfb进程。
display.sendstop() # 先发送SIGTERM信号给Xvfb,让Xvfb自行了断,如果Xvfb进程还在,则继续发送SIGKILL强制结束Xvfb进程。
部署时可能遇到的坑:
1. 运行webdriver.Firefox()后等待很久报错并退出,显示selenium.common.exceptions.WebDriverException: Message: other os error:
可能是版本不兼容,可以把firefox,geckodriver以及selenium全部升级到新版本。
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。

【自动化测试&爬虫系列】Selenium Webdriver的更多相关文章
- Python爬虫系列-Selenium详解
自动化测试工具,支持多种浏览器.爬虫中主要用来解决JavaScript渲染的问题. 用法讲解 模拟百度搜索网站过程: from selenium import webdriver from selen ...
- 爬虫系列---selenium详解
一 安装 pip install Selenium 二 安装驱动 chrome驱动文件:点击下载chromedriver (yueyu下载) 三 配置chromedrive的路径(仅添加环境变量即可) ...
- 爬虫-【selenium—Webdriver元素定位的八种常用方式
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下 ...
- Python爬虫系列-Selenium+Chrome/PhantomJS爬取淘宝美食
1.搜索关键字 利用Selenium驱动浏览器搜索关键字,得到查询后的商品列表 2.分析页码并翻页 得到商品页码数,模拟翻页,得到后续页面的商品列表 3.分析提取商品内容 利用PyQuery分析源码, ...
- python 全栈开发,Day136(爬虫系列之第3章-Selenium模块)
一.Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全 ...
- 爬虫系列(十二) selenium的基本使用
一.selenium 简介 随着网络技术的发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载 对于爬取这些网站,一般有两种思路: 分析 Ajax 请 ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- 转载 基于Selenium WebDriver的Web应用自动化测试
转载原地址: https://www.ibm.com/developerworks/cn/web/1306_chenlei_webdriver/ 对于 Web 应用,软件测试人员在日常的测试工作中, ...
- Selenium WebDriver + python 自动化测试框架
目标 组内任何人都可以进行自动化测试用例的编写 完全分离测试用例和自动化测试代码,就像写手工测试用例一下,编写excel格式的测试用例,包括步骤.检查点,然后执行自动化工程,即可执行功能自动化测试用例 ...
随机推荐
- [Swift]LeetCode148. 排序链表 | Sort List
Sort a linked list in O(n log n) time using constant space complexity. Example 1: Input: 4->2-> ...
- python之pickle模块
1 概念 pickle是python语言的标准模块,安装python后以包含pickle库,不需要再单独安装. pickle提供了一种简单的持久化功能,可以将对象以文件的形式存放在磁盘上. pickl ...
- Mysql的两种偏移量分页写法
当一个查询语句偏移量offset很大的时候,如select * from table limit 10000,10 , 先获取到offset的id后,再直接使用limit size来获取数据,效率会有 ...
- idea设置代码颜色主题(同Sublime Text 3的代码颜色一样)
1.下载主题的网址:http://color-themes.com,主题种类多,总有适合你的主题.在这个网址下载的主题是jar文件,直接导入,如下图file->import Setting,找 ...
- Python内置函数(52)——range
英文文档: range(stop) range(start, stop[, step]) Rather than being a function, range is actually an immu ...
- 关于pycharm安装出现的interpreter field is empty,无法创建项目存储位置
关于pycharm安装出现的interpreter field is empty(解释器为空) 关于pycharm安装出现的interpreter field is empty,无法创建项目存储的位置 ...
- TypeError: unorderable types: str() >= int()
1.问题描述 age=input('please enter your age') if age >=18: print('your age is',age) print('adult') el ...
- 从锅炉工到AI专家(2)
大数据 上一节说到,大多的AI问题,会有很多个变量,这里深入的解释一下这个问题. 比如说某个网站要做用户行为分析,从而指导网站建设的改进.通常而言如果没有行为分析,并不需要采集用户太多的数据. 比如用 ...
- SpringBoot入门教程(七)整合themeleaf+bootstrap
Thymeleaf是用于Web和独立环境的现代服务器端Java模板引擎.Thymeleaf的主要目标是将优雅的自然模板带到您的开发工作流程中—HTML能够在浏览器中正确显示,并且可以作为静态原型,从而 ...
- SpringCloud Feign的分析
Feign是一个声明式的Web Service客户端,它使得编写Web Serivce客户端变得更加简单.我们只需要使用Feign来创建一个接口并用注解来配置它既可完成. @FeignClient(v ...