机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点。
决策树:是一种基本的分类和回归方法。在分类问题中,是基于特征对实例进行分类。既可以认为是if-then规则的集合,也可以认为是定义在特征空间和类空间上的条件概率分布。
决策树模型:决策树由结点和有向边组成。结点一般有两种类型,一种是内部结点,一种是叶节点。内部结点一般表示一个特征,而叶节点表示一个类。当用决策树进行分类时,先从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到子结点。而子结点这时就对应着该特征的一个取值。如此递归对实例进行测试分配 ,直至达到叶结点,则该实例属于该叶节点的类。
决策树分类的主要算法有ID3,C4.5。回归算法为CART算法,该算法既可以分类也可以进行回归。
(一)特征选择与信息增益准则
特征选择在于选取对训练数据具有分类能力的 特征,而且是分类能力越强越好,这样子就可以提高决策 树 的效率。如果利用一个特征进行分类,分类的结果与随机分类的结果没有差异,那么这个特征是没有分类能力的。那么用什么来判别一个特征的分类能力呢?那就是信息增益准则。
何为信息增益?首先,介绍信息论中熵的概念。
熵度量了随机变量的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵定义如下:
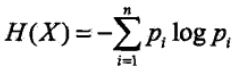
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵为H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
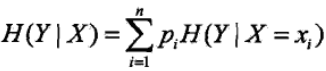
信息增益表示在已知特征X的情况下,而使得Y的信息的不确定性减少的程度。信息增益的定义 式如下:

g(D,A)表示特征A对训练集D的信息增益,其为集合D的经验熵H(D)与在特征A给定条件下D的经验条件熵H(D|A)之差。一般熵与条件熵之差,称为互信息。在决策树中,信息增益就等价于训练数据集中的类与特征的互信息。
具体信息增益的计算
(1)计算数据集D的经验熵H(D)
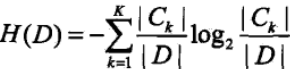
(2)计算特征A对数据集D的经验条件熵H(D|A):
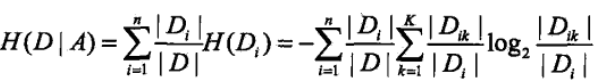
(3)计算信息增益
(二)ID3算法
ID3算法以信息增益作为选择特征的准则
输入:训练数据集D,特征集A(可以从训练集中提取出来),阀值ε(用来实现提前终止);
(1)若当前节点中所有实例属于同一类Ck,则该结点作为叶子节点,并将类别Ck作为该结点的输出类;
(2)若A为空,则将当前结点作为叶子节点,并将数据集中数量最多的类作为该结点输出类;
(3)否则,计算所有特征的信息增益,若此时最大的信息增益小于阀值ε,则将当前结点作为叶子节点,并将数据集中数量最多的类作为该结点输出类;
(4)若当前的最大信息增益大于阀值ε,则将最大信息增益对应的特征A作为最优划分特征对数据集进行划分,根据特征A的取值将数据集划分为若干个子结点;
(5)对第i个结点,以Di为训练集,以Ai为特征集(之前用过的特征从特征集中去除),递归的调用前面的1- 4 步。
ID3算法的缺点:
(1)ID3算法会偏向于选择类别较多的属性(形成分支较多会导致信息增益大)
(2)ID3算法没有考虑连续值,对与连续值的特征无法进行划分
(3) ID3算法对于缺失值的情况没有做考虑。
(4)ID3算法只有树的生成,容易产生过拟合。
(5)ID3算法采用贪心算法,每次划分都是考虑局部最优化,而局部最优化并不是全局最优化,通常需对其进行剪枝,而决策树剪枝是对模型进行整体优化。
(三)C4.5算法
C4.5算法与ID3算法相似,不过在生成树的过程中,采用信息增益比来作为选择特征的准则。
增益比:
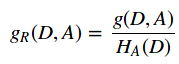
其中 为特征熵,n为特征取值的数目。
为特征熵,n为特征取值的数目。
C4.5算法的训练过程与ID3相似,见ID3算法。
C4.5其实是针对ID3算法的不足改进后的算法,采用信息增益比,是为了解决ID3算法会偏向于选择类别多的属性的问题。而对于ID3算法不能对连续值进行划分的问题 ,C4.5采用连续值特征离散化的。此外,C4.5还从以下两方面考虑了缺失值的问题:一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。对于ID3存在的过拟合问题,C4.5采用了引进正则化系数,对决策树进行剪枝。
(四)CART算法
CART树既可以用于 分类 ,也可以用于回归。CART树的生成过程同样包括特征选择,树的生成及剪枝。
与ID3,C4.5算法不同的是,首先,CART进行特征选择时,回归树用的平方误差最小化的准则,而对于分类树用基尼系数。对于平方误差好理解。主要介绍下分类时用的基尼系数,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。具体的,在分类问题中,假设有K个类别,第k个类别的概率为pk, 则基尼系数的表达式为:
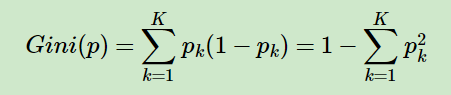
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是p,则基尼系数的表达式为:

简单明了的理解基尼系数那就是,从集合中随机选取两个样本,两个样本的类别不一致的概率,所以这概率越低,说明划分的集合的不纯度就越低。
对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为:
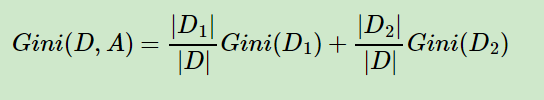
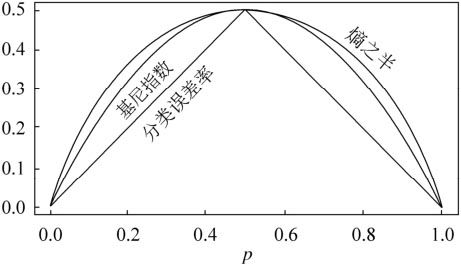
基尼系数用于度量时,与熵之半,分类误差率的关系。可见,基尼系数和熵之半的曲线非常接近,都可以近似的代表分类误差率
此外,CART树在生成过程中,生成的是二叉树。即CART树在生成过程中仅仅是对特征的值进行二分,而不是多分。
CART分类树建立的过程:
对于给定训练数据集D,从根结点开始递归的建立二叉决策树:
1)根据数据集D中每个特征A,以及其可能的取值a,按照取值的‘是‘和‘否’将数据集分成两部分,然后计算基尼系数 。
2)在所有可能的特征A以及他们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征的与最优切分点。
依最优特征和最优切分点,将现结点生成两个子结点,将训练数据集依特征分配到两个子结点中。
3)递归的调用1)2)步骤,直至达到停止条件
停止条件有:结点中的样本数小于预定的阈值,或者样本集的基尼系数小于预定的阈值(此时基尼系数已经非常小,样本基本属于同一 类),
或者结点样本中没有更多的特征。
CART回归树建立的过程:
首先说下分类树和回归树的区别吧,分类树样本输出的值为离散的类别值(如二分类输出的值为0和1),而回归树样本输出的是连续值。
在分类树中,采用基尼系数 来对特征进行划分。而在CART回归树用的平方误差最小化准则,具体就是对于任意划分特征A,
对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时将D1和D2的均方差之和最小所对应的特征和特征值作为划分点。
表达式如下:

其中,c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值
1)对于数据集D,通过平方误差准则(上面式子),选择最优的切分变量和切分点;
2)用选定的最优切分变量和切分点划定两个子区域区域,并输出该区域数据集样本的均值。
3)继续对两个子区域进行调用步骤1)和2),直至满足停止条件
4)最后将样本空间划分成M个区域,即M个叶结点,以及M个与叶结点对应的输出值。
CART树的剪枝
CART树的剪枝就是加入先验的过程,其损失函数如下:
Cα(T)=C(T)+α|T|
其中T为任意子树,C(T)为对训练数据的预测误差(如基尼系数),|T|为叶结点的个数,α>=0为参数,Cα(T)为整体损失。
正则化项的加入能够起到剪枝的作用 ,从而降低了模型的复杂度。而α参数起到了平衡模型复杂度与训练数据拟合度的 作用。
(五)总结
决策树的缺点
1)决策树算法属于贪心的算法,在生成树的过程中只考虑局部最优形成,而不考虑整体最优,所以生成的树容易产生过拟合,
(即对训练集的分类很正确,但是对未知的数据分类却没那么准确,泛化能力不强)。所以需要在决策树生成后对其进行剪枝,
也就是说简化模型的复杂度,一般通过加正则化项来进行剪枝。
2)决策树对训练数据的变化敏感,数据集变化,树就会发生变化;该缺点可以通过集成树来解决。譬如随机森林,随机森林的数据样本扰动。
3)决策树没有考虑变量之间相关性,每次筛选都只考虑一个变量(因此不需要归一化)
决策树的优点:
1)简单直观,模型解释性好
2)基本不需要预处理,不需要提前归一化,处理缺失值
3)使用决策树预测的代价是O(log2m)。 m为样本数
4)既可以处理离散值也可以处理连续值
5) 对于异常点的容错能力好,健壮性高
6)可以处理多维度输出的分类问题
机器学习总结(八)决策树ID3,C4.5算法,CART算法的更多相关文章
- 决策树(ID3,C4.5,CART)原理以及实现
决策树 决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布. [图片上传失败...(image ...
- 决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习 决策树是一种依托决策而建立起来的一种树. 在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某 ...
- 21.决策树(ID3/C4.5/CART)
总览 算法 功能 树结构 特征选择 连续值处理 缺失值处理 剪枝 ID3 分类 多叉树 信息增益 不支持 不支持 不支持 C4.5 分类 多叉树 信息增益比 支持 ...
- ID3,C4.5和CART三种决策树的区别
ID3决策树优先选择信息增益大的属性来对样本进行划分,但是这样的分裂节点方法有一个很大的缺点,当一个属性可取值数目较多时,可能在这个属性对应值下的样本只有一个或者很少个,此时它的信息增益将很高,ID3 ...
- 机器学习实战python3 决策树ID3
代码及数据:https://github.com/zle1992/MachineLearningInAction 决策树 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特 ...
- ID3、C4.5和cart算法比较(转)
转自:https://www.zhihu.com/question/27205203
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树ID3算法--python实现
参考: 统计学习方法>第五章决策树] http://pan.baidu.com/s/1hrTscza 决策树的python实现 有完整程序 决策树(ID3.C4.5.CART ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
随机推荐
- Autofac之依赖注入
这里主要学习一下Autofac的依赖注入方式 默认构造函数注入 class A { public B _b; public A() { } public A(B b) { this._b = b; } ...
- 【Python全栈-CSS】CSS实现网页背景图片自适应全屏
CSS实现网页背景图片自适应全屏 功能:实现能自适应屏幕大小又不会变形的背景大图,而且背景图片不会随着滚动条滚动而滚动. 以下是用CSS实现的方法: <html> <head> ...
- VUE-005-axios常用请求参数设置方法
在前后端分离的开发过程中,经常使用 axios 进行后端接口的访问. 个人习惯常用的请求参数设置方法如下所示: // POST方法:data在请求体中 addRow(data) { return th ...
- linux netcat 命令详解
功能说明:强大的网络工具语 法:nc [-hlnruz][-g<网关...>][-G<指向器数目>][-i<延迟秒数>][-o<输出文件>][-p< ...
- php中的echo 与print 、var_dump 的区别
· echo - 可以输出一个或多个字符串 · print - 只允许输出一个字符串,返回值总为 1 提示:echo 输出的速度比 print 快, echo 没有返回值,print有返回值1. ...
- FEX(Fabric Extender)
一.FEX Cisco Nexus 2000 FEX作为N5K.N6K.N7K.FI的一个远程线卡,单独的2K是没有网管功能的,必须配合父系交换机使用. 主要解决TOR和EOR的问题,TOR,接线简单 ...
- jeecg自定义按钮使用exp属性不起作用
为什么要写这篇文章? 之前写过一篇类似的文章 jeecg笔记之自定义显示按钮exp属性,但是有些小伙伴留言参考后不起作用,当时我的 jeecg 版本为3.7.5,最终以版本不同,暂时搁浅了.今天,重新 ...
- JAVA学习笔记 (okHttp3的用法)
最近的项目中有个接口是返回文件流数据,根据我们这边一个验签的插件,我发现里面有okHttpClient提供了Call.Factory,所以就学习了下okHttp3的用法. 1.概述 okhttp是一个 ...
- oracle 表空间,用户的创建及授权,表空间基本操作
参考地址:https://www.cnblogs.com/zhaideyou/articles/5845271.html Oracle安装完后,其中有一个缺省的数据库,除了这个缺省的数据库外,我们还可 ...
- 阿里云mysql安装配置(CentOS 7.3 64)
自建目录并且加载yum资源mysql 安装 回车之后竟然出现不可以的情况(原因是原来的镜像里面默认装好了mysql5.7) 然后只能尝试跳过密码登录 #vim /etc/my.cnf 在文档内搜索my ...