numpy鸢尾花
import numpy
from sklearn.datasets import load_iris
#从sklearn包自带的数据集中读出鸢尾花数据集data
iris_data = load_iris()
# 查看data类型,包含哪些数据
print("数据类型: ", type(iris_data))
print("包含数据: ", iris_data.keys()) # 看包含哪些数据
iris_feature = data.feature_names,data.data
#鸢尾花特征:
print(iris_feature)
#iris_feature数据类型
print(type(iris_feature))
iris_target = data.target
#鸢尾花数据类别:
print(iris_target)
#iris_target数据类型:
print(type(iris_target))

sepal_len = np.array(list(len[0] for len in data.data))
#取出所有花的花萼长度(cm)的数据
print(sepal_len)

# 6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
petal_len = numpy.array(list(len[2] for len in iris_data['data'])) # 取花瓣长
petal_len.resize(5, 30)
petal_wid = numpy.array(list(wid[3] for wid in iris_data['data'])) # 取花瓣宽
petal_wid.resize((5, 30))
petal_len_wid = numpy.array(dict(length=petal_len, width=petal_wid)) # 形成新数组
print("花瓣长宽: ", petal_len_wid)

# 取出某朵花的四个特征及其类别
print("某朵花数据: ", iris_data['data'][0], iris_data['target'][0])
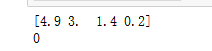
iris_one = []
iris_two = []
iris_three = [] for i in range(0,150):
if data.target[i] == 0:
Data = data.data[i].tolist()
Data.append('setose')
iris_one.append(Data)
elif data.target[i] ==1:
Data = data.data[i].tolist()
Data.append('color')
iris_two.append(Data)
else:
Data = data.data[i].tolist()
Data.append('flower')
iris_three.append(Data)

# 生成新的数组,每个元素包含四个特征+类别
iris_result = numpy.array([iris_setosa, iris_versicolor, iris_virginica]) print("分类结果", iris_result)

numpy鸢尾花的更多相关文章
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- numpy数据集练习
#1. 安装scipy,numpy,sklearn包 import numpy as np #2. 从sklearn包自带的数据集中读出鸢尾花数据集data from sklearn.datasets ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- 第七次作业——numpy统计分布显示
用np.random.normal()产生一个正态分布的随机数组,并显示出来. np.random.randn()产生一个正态分布的随机数组,并显示出来. 显示鸢尾花花瓣长度的正态分布图,曲线图,散点 ...
- 第六次作业———numpy数据集练习
1. 安装scipy,numpy,sklearn包 2. 从sklearn包自带的数据集中读出鸢尾花数据集data 3.查看data类型,包含哪些数据 4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及 ...
- numpy统计分布显示
#导包 import numpy as np #导入鸢尾花数据 from sklearn.datasets import load_iris data = load_iris() pental_len ...
- pytorch解决鸢尾花分类
半年前用numpy写了个鸢尾花分类200行..每一步计算都是手写的 python构建bp神经网络_鸢尾花分类 现在用pytorch简单写一遍,pytorch语法解释请看上一篇pytorch搭建简单网 ...
- numpy数据集练习 ----------sklearn类
# 1. 安装scipy,numpy,sklearn包 import numpy from sklearn.datasets import load_iris # 2. 从sklearn包自带的数据集 ...
- Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 概率p与因变量往 ...
随机推荐
- 小白的python之路Linux部分10/28&29
属主属组其他人对文件的rwx权限 1.userdel删东西不全,会有残留,
- Django数据同步过程中遇到的问题:
1.raise ImproperlyConfigured('mysqlclient 1.3.13 or newer is required; you have %s.' % Database.__ve ...
- flask基础--第二篇
1.Flask中的HTTPResponse,Redirect, render #导入render_template和redirect from flask import Flask,render_te ...
- Kali Linux Vmware虚拟机(新手)安装
准备工作: 1.安装VMware workstation 软件 2.下载好kali linux 的ios系统文件 3.打开电脑的虚拟化支持(Intel VT-x/EPT或AMD-V/RVI(V)) 虚 ...
- 一般处理程序、Ajax多图片上传带进度条
<!DOCTYPE html><html><head> <meta charset="utf-8" /> <tit ...
- BPM与OA区别
核心差异: OA解决的是流程有无问题 BPM解决的是流程更好更优的问题 主要差异如下: 1.BPM有更好的广度跟深度 这里的广度是指应用场景的广度. BPM一般都会以端到端的方式衔接企业运营过程的上下 ...
- Angular cli 发布自定义组件
建立工作空间 ng new Test --style=scss //Angular6.x及以下可以使用这个命令指定使用.scss样式表 ng new Test ...
- 关于FFmpeg工具的使用总结
FFmpeg官网:http://ffmpeg.org/ 安装ffmpeg: http://www.cnblogs.com/freeweb/p/6897907.html 主要参数: -i 设定输入流 - ...
- Object.prototype.toString.call() 、 instanceof 以及 Array.isArray()判断数组的方法的优缺点
1. Object.prototype.toString.call() 每一个继承 Object 的对象都有 toString 方法,如果 toString 方法没有重写的话,会返回 [Object ...
- weblogic中部署项目通常有三种方式
在weblogic中部署项目通常有三种方式:第一,在控制台中安装部署:第二,将部署包放在domain域中autodeploy目录下部署:第三,使用域中配置文件config.xml 进行项目的部署. 控 ...