numpy鸢尾花
import numpy
from sklearn.datasets import load_iris
#从sklearn包自带的数据集中读出鸢尾花数据集data
iris_data = load_iris()
# 查看data类型,包含哪些数据
print("数据类型: ", type(iris_data))
print("包含数据: ", iris_data.keys()) # 看包含哪些数据
iris_feature = data.feature_names,data.data
#鸢尾花特征:
print(iris_feature)
#iris_feature数据类型
print(type(iris_feature))
iris_target = data.target
#鸢尾花数据类别:
print(iris_target)
#iris_target数据类型:
print(type(iris_target))

sepal_len = np.array(list(len[0] for len in data.data))
#取出所有花的花萼长度(cm)的数据
print(sepal_len)

# 6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
petal_len = numpy.array(list(len[2] for len in iris_data['data'])) # 取花瓣长
petal_len.resize(5, 30)
petal_wid = numpy.array(list(wid[3] for wid in iris_data['data'])) # 取花瓣宽
petal_wid.resize((5, 30))
petal_len_wid = numpy.array(dict(length=petal_len, width=petal_wid)) # 形成新数组
print("花瓣长宽: ", petal_len_wid)

# 取出某朵花的四个特征及其类别
print("某朵花数据: ", iris_data['data'][0], iris_data['target'][0])
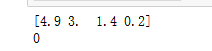
iris_one = []
iris_two = []
iris_three = [] for i in range(0,150):
if data.target[i] == 0:
Data = data.data[i].tolist()
Data.append('setose')
iris_one.append(Data)
elif data.target[i] ==1:
Data = data.data[i].tolist()
Data.append('color')
iris_two.append(Data)
else:
Data = data.data[i].tolist()
Data.append('flower')
iris_three.append(Data)

# 生成新的数组,每个元素包含四个特征+类别
iris_result = numpy.array([iris_setosa, iris_versicolor, iris_virginica]) print("分类结果", iris_result)

numpy鸢尾花的更多相关文章
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- numpy数据集练习
#1. 安装scipy,numpy,sklearn包 import numpy as np #2. 从sklearn包自带的数据集中读出鸢尾花数据集data from sklearn.datasets ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- 第七次作业——numpy统计分布显示
用np.random.normal()产生一个正态分布的随机数组,并显示出来. np.random.randn()产生一个正态分布的随机数组,并显示出来. 显示鸢尾花花瓣长度的正态分布图,曲线图,散点 ...
- 第六次作业———numpy数据集练习
1. 安装scipy,numpy,sklearn包 2. 从sklearn包自带的数据集中读出鸢尾花数据集data 3.查看data类型,包含哪些数据 4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及 ...
- numpy统计分布显示
#导包 import numpy as np #导入鸢尾花数据 from sklearn.datasets import load_iris data = load_iris() pental_len ...
- pytorch解决鸢尾花分类
半年前用numpy写了个鸢尾花分类200行..每一步计算都是手写的 python构建bp神经网络_鸢尾花分类 现在用pytorch简单写一遍,pytorch语法解释请看上一篇pytorch搭建简单网 ...
- numpy数据集练习 ----------sklearn类
# 1. 安装scipy,numpy,sklearn包 import numpy from sklearn.datasets import load_iris # 2. 从sklearn包自带的数据集 ...
- Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 概率p与因变量往 ...
随机推荐
- HTML、CSS(小笔记)
这是我自己在学习html.css时觉得要记的东西太多总结一些较为常用的标签. HTML <p></p>段落标签 <hn></hn>标题标签n数值为1~6 ...
- 复杂xml格式报文和实体类之间的转化
pom.xml中引入如下依赖: <dependency> <groupId>org.eclipse.persistence</groupId> <artifa ...
- winfrom程序文本框第一次选中问题
想实现这样的功能: 就是在panel中的文本框,当第一次点击文本框时,全选文本框的内容:再次选择时,可以全选,也可以部分选中, 可是文本框总是从左全部选中,还不能从右边选择,在Enter或Down事件 ...
- python 多进程多线程的对比
link:http://www.cnblogs.com/whatisfantasy/p/6440585.html mark一下,挺详细
- vue 路由(1)
路由的使用 (5步) 1.首先安装路由 npm install vue-router2.引入 vue-router import VueRouter from 'vue-router' 3.使用 ...
- Write CSV file for a dataset
import numpy as np import cv2 as cv2 import os import csv dataste_path = 'datasets/pascal-parts/pasc ...
- Docker Toolbox
Toolbox包含以下Docker工具: 用于运行docker-machine命令的Docker Machine 用于运行docker命令的Docker Engine Docker Compose用于 ...
- [c++]关于strcpy函数溢出解决方案
必须包含的头文件:<string.h> 可改写成安全函数strcpy_s 找到[项目属性],点击[C++]里的[预处理器],对[预处理器]进行编辑,在里面加入一段代码:_CRT_SECUR ...
- php字符串转数组
下面代码包括了含有中文汉字的字符. function str2arr($str) { $length = mb_strlen($str, 'utf-8'); $array = []; for ($i= ...
- Selenium常用API详解介绍
转至元数据结尾 由 黄从建创建, 最后修改于一月 21, 2019 转至元数据起始 一.selenium元素定位 1.selenium定位方法 2.定位方法的用法 二.控制浏览器操作 1.控制 ...