virtual-dom
virtual-dom的历史
react最早研究virtual-dom,后来react火了之后,大家纷纷研究react的高性能实现,出现了2个流派,一是研究react算法的算法派,(virtual-dom.js,cito.js,kivi.js,snabbdom.js,inferno),二是研究react的形态,react的迷你版-preact, inferno, react-lite, dio, rax。
算法派virtual-dom最开始研究react的diff算法,它通过深度优先搜索与in-order tree来实现高效的diff。它与React后来公开出来的算法是很不一样。
然后是cito.js,它采用两端同时进行比较的算法,将diff速度拉高到几个层次。
紧随其后的是kivi.js,在cito.js的基出提出两项优化方案,使用key实现移动追踪及基于key的编辑长度矩离算法应用(算法复杂度 为O(n^2))。
但这样的diff算法太过复杂了,于是后来者snabbdom将kivi.js进行简化,去掉编辑长度矩离算法,调整两端比较算法。速度略有损失,但可读性大大提高。再之后,就是著名的vue2.0 把sanbbdom整个库整合掉了。
当然算法派的老大是inferno,它使用多种优化方案将性能提至最高,因此其作者便邀请进react core team,负责react的性能优化了。
司徒正美《去哪儿网迷你React的研发心得》 https://segmentfault.com/a/1190000011235844
优点
相比于频繁的手动去操作dom而带来性能问题,vdom很好的将dom做了一层映射关系,进而将在我们本需要直接进行dom的一系列操作,映射到了操作vdom。
这一系列操作都是单纯依赖js,使得服务端渲染ssr得到更好的解决方案。
通过操作vdom来提高直接操作的dom的效率和性能。
有人会问为啥运行js会比直接操作更快呢?
在我理解,react并没说virtual-dom比原生更快阿。得到dom diff最后还是要通过操作原生dom render到浏览器上,所以肯定是原生更快的,但是这里说的快是指的react的batchUpdate机制。
- 大概理解就是每次setState并不会立即执行,它会整合多个setState一起进行操作。
- 大概原理就是react给函数封装了一层Transaction,它可以让react在函数执行前后执行一个钩子,initialize(函数执行前)阶段下创建一个update queue,setState把状态推入update queue,close(函数执行后)阶段update queue被flush。
vue的实现就比较简单,直接push进update queue,利用micro-task队列(异步操作),尽快的执行update queue flush。
snabbdom.js的实现(vue diff算法)
snabbdom 主要的接口有:
- h(type, data, children),返回 Virtual DOM 树。
- patch(oldVnode, newVnode),比较新旧 Virtual DOM 树并更新。
vnode
const VNODE_TYPE = Symbol('virtual-node')
function vnode(type, key, data, children, text, elm) {
const element = {
__type: VNODE_TYPE,
type, key, data, children, text, elm
}
return element
}
function isVnode(vnode) {
return vnode && vnode.__type === VNODE_TYPE
}
function isSameVnode(oldVnode, vnode) {
return oldVnode.key === vnode.key && oldVnode.type === vnode.type
}
利用__type是Symbol的特性来校验vnode。
生成了这样一个js对象
{
type, // String,DOM 节点的类型,如 'div'/'span'
data, // Object,包括 props,style等等 DOM 节点的各种属性
children // Array,子节点(子 vnode)
}
生成dom树
function h(type, config, ...children) {
const props = {}
// 省略用 config 填充 props 的过程
return vnode(
type,
key,
props,
flattenArray(children).map(c => {
return isPrimitive(c) ? vnode(undefined, undefined, undefined, undefined, c) : c
})
)
}
dom diff-两端比较法
通常找到两棵任意的树之间最小修改的时间复杂度是 O(n^3),但是我们可以对dom做一些特别的假设:
如果oldVnode 和 vnode 不同(如 type 从 div 变到 p,或者 key 改变),意味着整个 vnode 被替换(因为我们通常不会去跨层移动 vnode ),所以我们没有必要去比较 vnode 的 子 vnode(children) 了。
基于这个假设,我们可以 按照层级分解 树,这大大简化了复杂度,大到接近 O(n) 的复杂度。
function patchVnode(oldVnode, vnode, insertedVnodeQueue) {
// 因为 vnode 和 oldVnode 是相同的 vnode,所以我们可以复用 oldVnode.elm。
const elm = vnode.elm = oldVnode.elm
let oldCh = oldVnode.children
let ch = vnode.children
// 如果 oldVnode 和 vnode 是完全相同,说明无需更新,直接返回。
if (oldVnode === vnode) return
// 调用 update hook
if (vnode.data) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
}
// 如果 vnode.text 是 undefined
if (vnode.text === undefined) {
// 比较 old children 和 new children,并更新
if (oldCh && ch) {
if (oldCh !== ch) {
// 核心逻辑(最复杂的地方):怎么比较新旧 children 并更新,对应上面
// 的数组比较
updateChildren(elm, oldCh, ch, insertedVnodeQueue)
}
}
// 添加新 children
else if (ch) {
// 首先删除原来的 text
if (oldVnode.text) api.setTextContent(elm, '')
// 然后添加新 dom(对 ch 中每个 vnode 递归创建 dom 并插入到 elm)
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
}
// 相反地,如果原来有 children 而现在没有,那么我们要删除 children。
else if (oldCh) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
}
// 最后,如果 oldVnode 有 text,删除。
else if (oldVnode.text) {
api.setTextContent(elm, '');
}
}
// 否则 (vnode 有 text),只要 text 不等,更新 dom 的 text。
else if (oldVnode.text !== vnode.text) {
api.setTextContent(elm, vnode.text)
}
}
function updateChildren(parentElm, oldCh, newCh, insertedVnodeQueue) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
// 遍历 oldCh 和 newCh 来比较和更新
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 1⃣️ 首先检查 4 种情况,保证 oldStart/oldEnd/newStart/newEnd
// 这 4 个 vnode 非空,左侧的 vnode 为空就右移下标,右侧的 vnode 为空就左移 下标。
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
}
/**
* 2⃣️ 然后 oldStartVnode/oldEndVnode/newStartVnode/newEndVnode 两两比较,
* 对有相同 vnode 的 4 种情况执行对应的 patch 逻辑。
* - 如果同 start 或同 end 的两个 vnode 是相同的(情况 1 和 2),
* 说明不用移动实际 dom,直接更新 dom 属性/children 即可;
* - 如果 start 和 end 两个 vnode 相同(情况 3 和 4),
* 那说明发生了 vnode 的移动,同理我们也要移动 dom。
*/
// 1. 如果 oldStartVnode 和 newStartVnode 相同(key相同),执行 patch
else if (isSameVnode(oldStartVnode, newStartVnode)) {
// 不需要移动 dom
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
// 2. 如果 oldEndVnode 和 newEndVnode 相同,执行 patch
else if (isSameVnode(oldEndVnode, newEndVnode)) {
// 不需要移动 dom
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}
// 3. 如果 oldStartVnode 和 newEndVnode 相同,执行 patch
else if (isSameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
// 把获得更新后的 (oldStartVnode/newEndVnode) 的 dom 右移,移动到
// oldEndVnode 对应的 dom 的右边。为什么这么右移?
// (1)oldStartVnode 和 newEndVnode 相同,显然是 vnode 右移了。
// (2)若 while 循环刚开始,那移到 oldEndVnode.elm 右边就是最右边,是合理的;
// (3)若循环不是刚开始,因为比较过程是两头向中间,那么两头的 dom 的位置已经是
// 合理的了,移动到 oldEndVnode.elm 右边是正确的位置;
// (4)记住,oldVnode 和 vnode 是相同的才 patch,且 oldVnode 自己对应的 dom
// 总是已经存在的,vnode 的 dom 是不存在的,直接复用 oldVnode 对应的 dom。
api.insertBefore(parentElm, oldStartVnode.elm, api.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}
// 4. 如果 oldEndVnode 和 newStartVnode 相同,执行 patch
else if (isSameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
// 这里是左移更新后的 dom,原因参考上面的右移。
api.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}
// 3⃣️ 最后一种情况:4 个 vnode 都不相同,那么我们就要
// 1. 从 oldCh 数组建立 key --> index 的 map。
// 2. 只处理 newStartVnode (简化逻辑,有循环我们最终还是会处理到所有 vnode),
// 以它的 key 从上面的 map 里拿到 index;
// 3. 如果 index 存在,那么说明有对应的 old vnode,patch 就好了;
// 4. 如果 index 不存在,那么说明 newStartVnode 是全新的 vnode,直接
// 创建对应的 dom 并插入。
else {
// 如果 oldKeyToIdx 不存在,创建 old children 中 vnode 的 key 到 index 的
// 映射,方便我们之后通过 key 去拿下标。
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
// 尝试通过 newStartVnode 的 key 去拿下标
idxInOld = oldKeyToIdx[newStartVnode.key]
// 下标不存在,说明 newStartVnode 是全新的 vnode。
if (idxInOld == null) {
// 那么为 newStartVnode 创建 dom 并插入到 oldStartVnode.elm 的前面。
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
// 下标存在,说明 old children 中有相同 key 的 vnode,
else {
elmToMove = oldCh[idxInOld]
// 如果 type 不同,没办法,只能创建新 dom;
if (elmToMove.type !== newStartVnode.type) {
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm)
}
// type 相同(且key相同),那么说明是相同的 vnode,执行 patch。
else {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined
api.insertBefore(parentElm, elmToMove.elm, oldStartVnode.elm)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
// 上面的循环结束后(循环条件有两个),处理可能的未处理到的 vnode。
// 如果是 new vnodes 里有未处理的(oldStartIdx > oldEndIdx
// 说明 old vnodes 先处理完毕)
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx+1] == null ? null : newCh[newEndIdx+1].elm
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
}
// 相反,如果 old vnodes 有未处理的,删除 (为处理 vnodes 对应的) 多余的 dom。
else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
首先,比较新老dom,如果都有,就进行diff,如果没有老的,直接插入新dom,如果没有新的有老dom,就删掉老dom。
主要逻辑是在updateChildren,进行新老dom的diff。
通过索引,遍历oldCh和newCh,这里新老两个队列分为5个情况去处理。
- 同 start不需要移动dom,直接更新 dom 属性/children
- 同 end 同上
- oldstart === newend,把老dom移到oldend的右边。
- oldend === oldstart, 老dom移到oldstart的左边。
- 如果4个都不同,从oldCh 数组建立 key --> index 的 map。取老dom的key,如果没有再重建。
例如:不带key的dom diff过程:
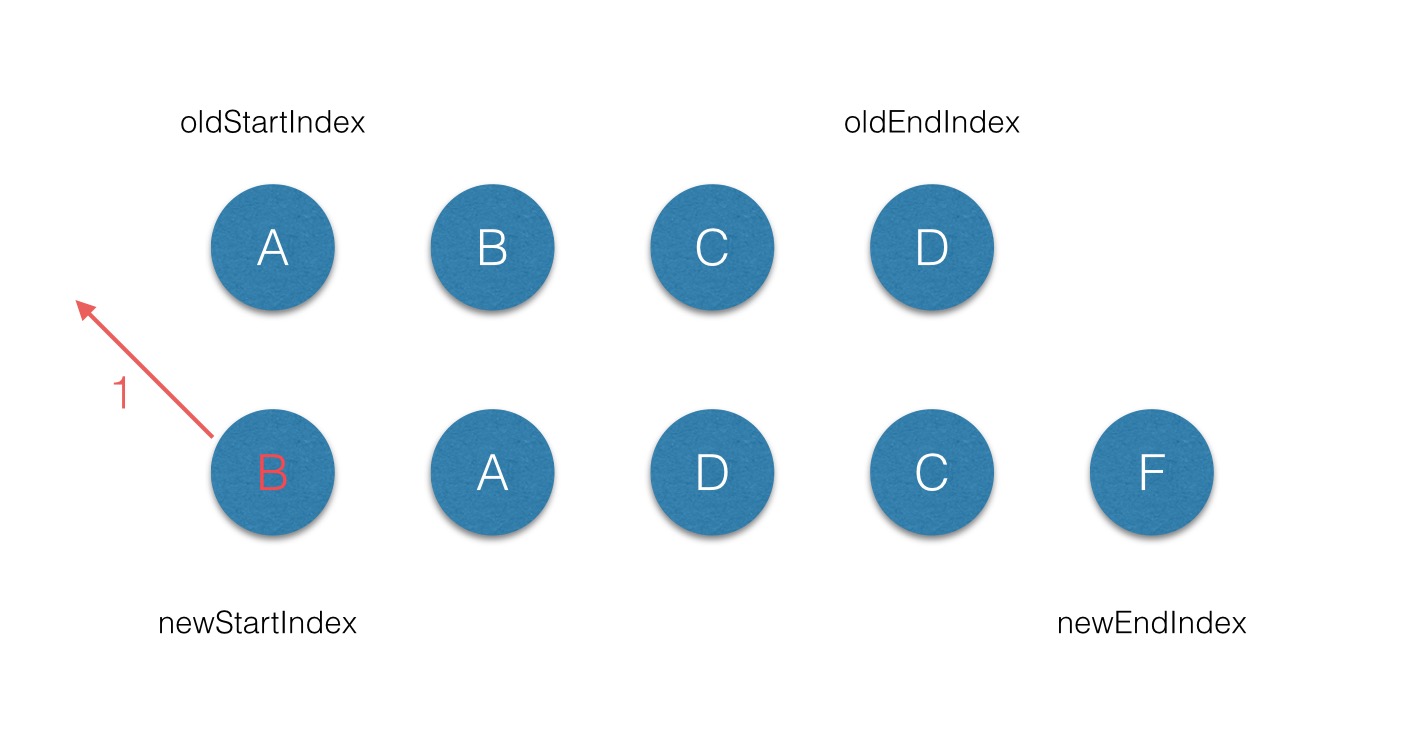
第一次遍历,发现b不等于oldstart也不等于oldend,新建b dom,插入最前面
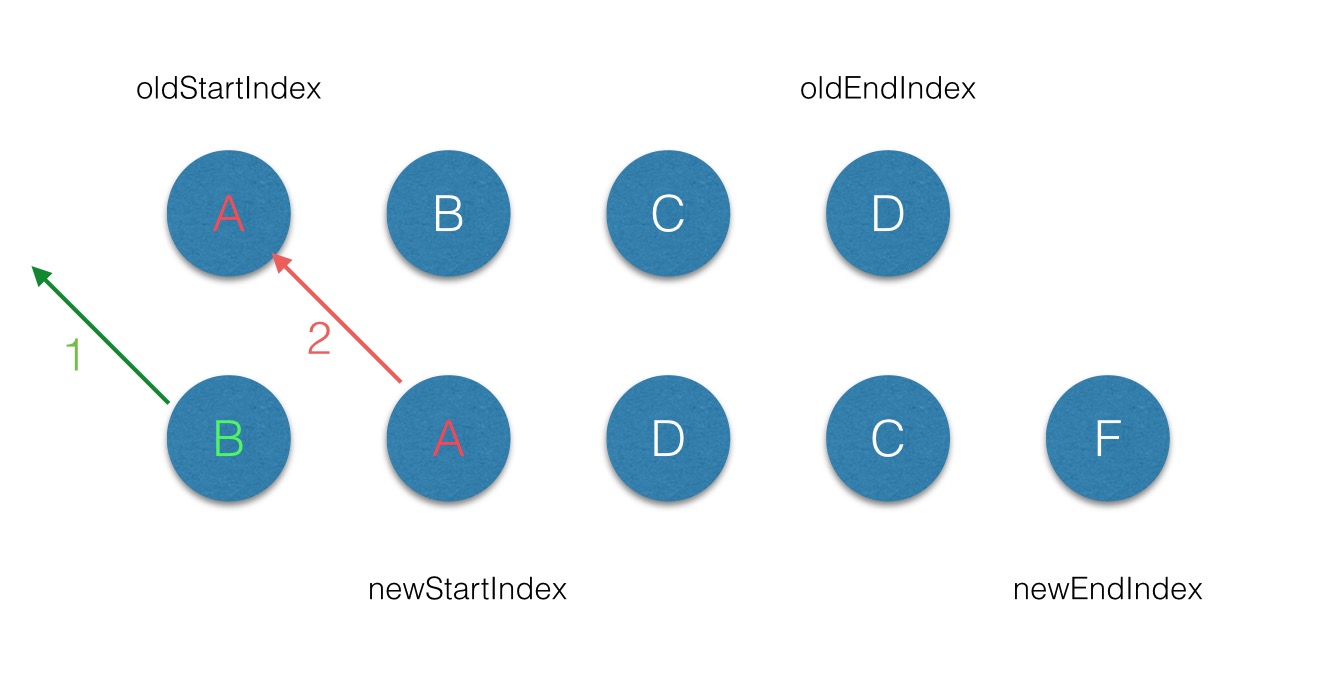
第二次遍历,oldstart === newstart,不移动dom。
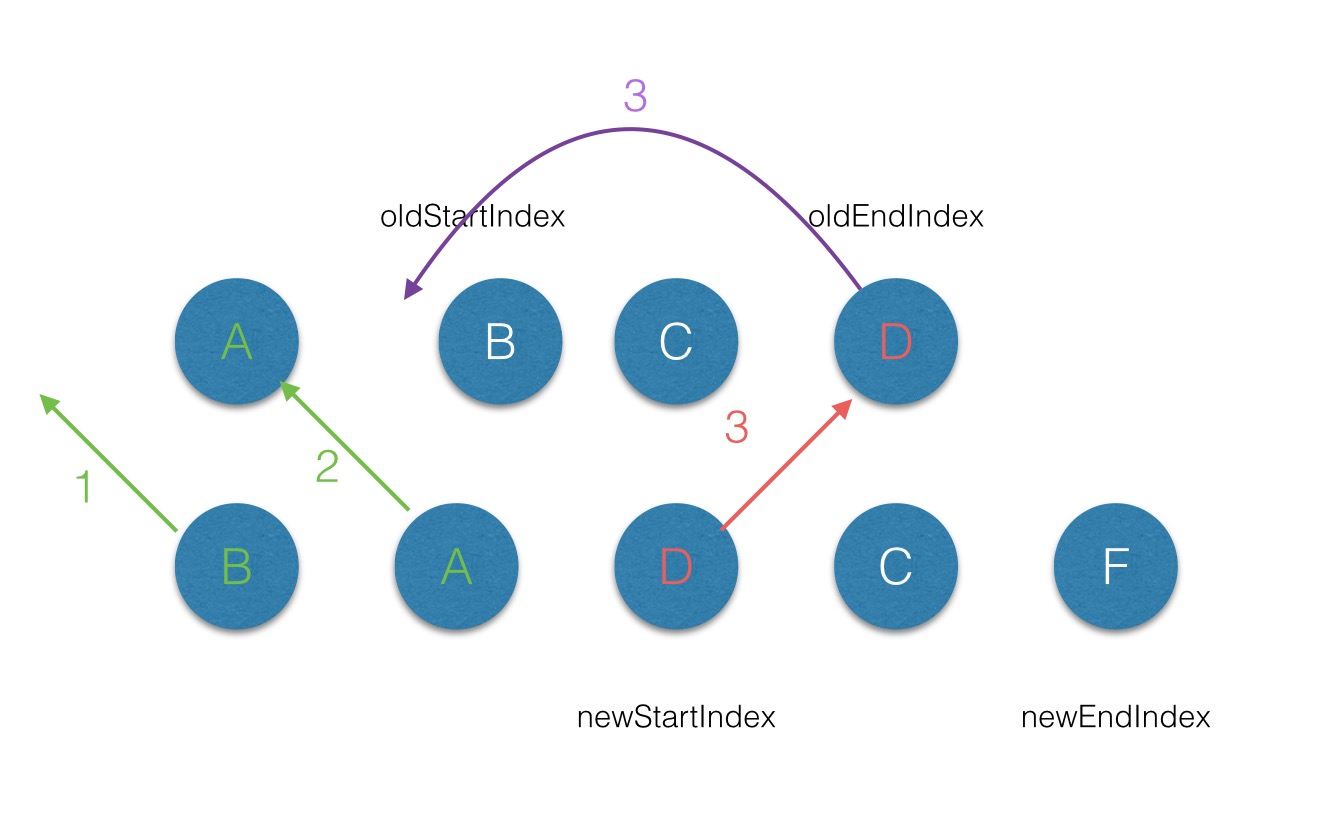
第三次遍历,newstart === oldend,就把end移到前面。
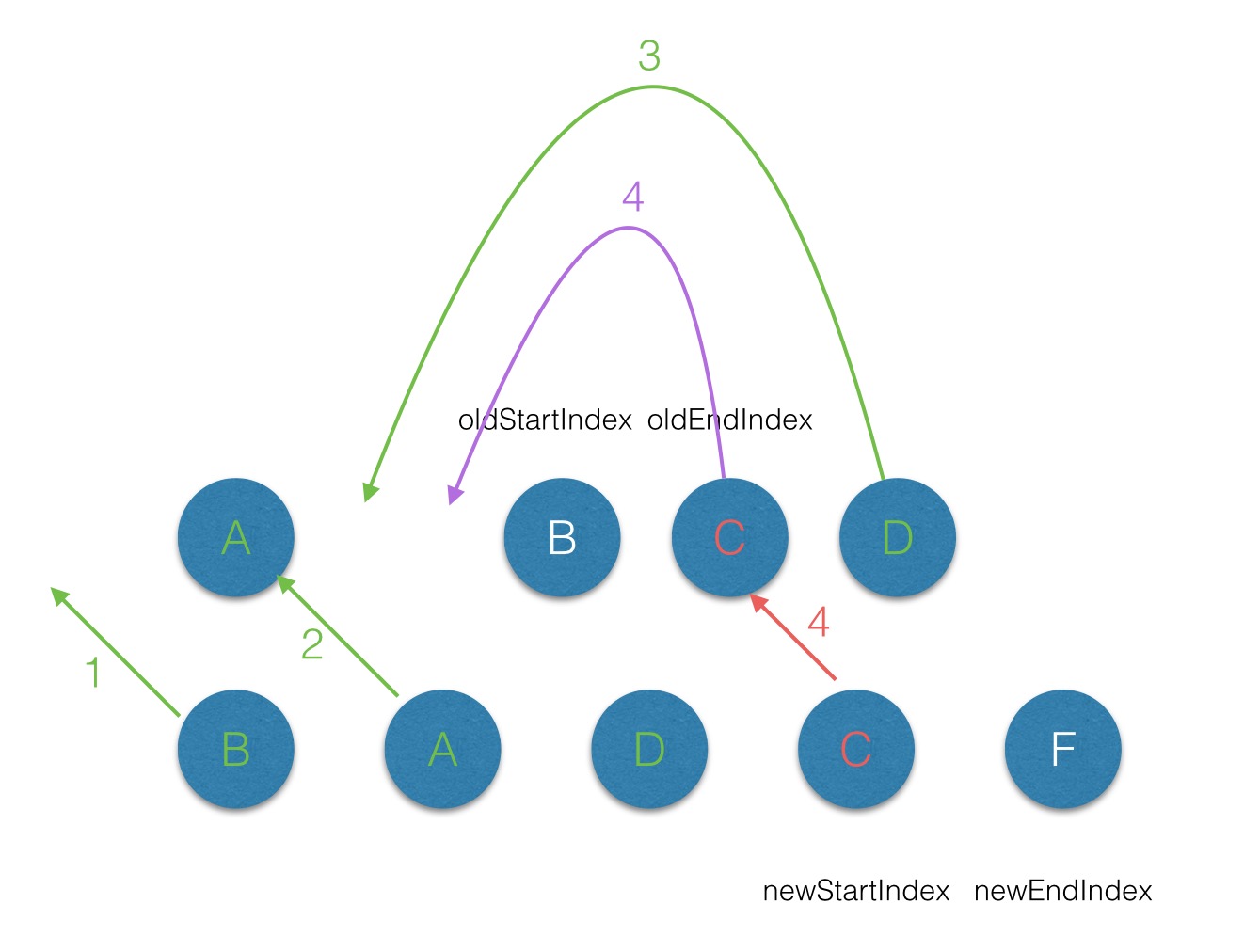
第四次遍历,newstart === oldend,就把end移到前面。
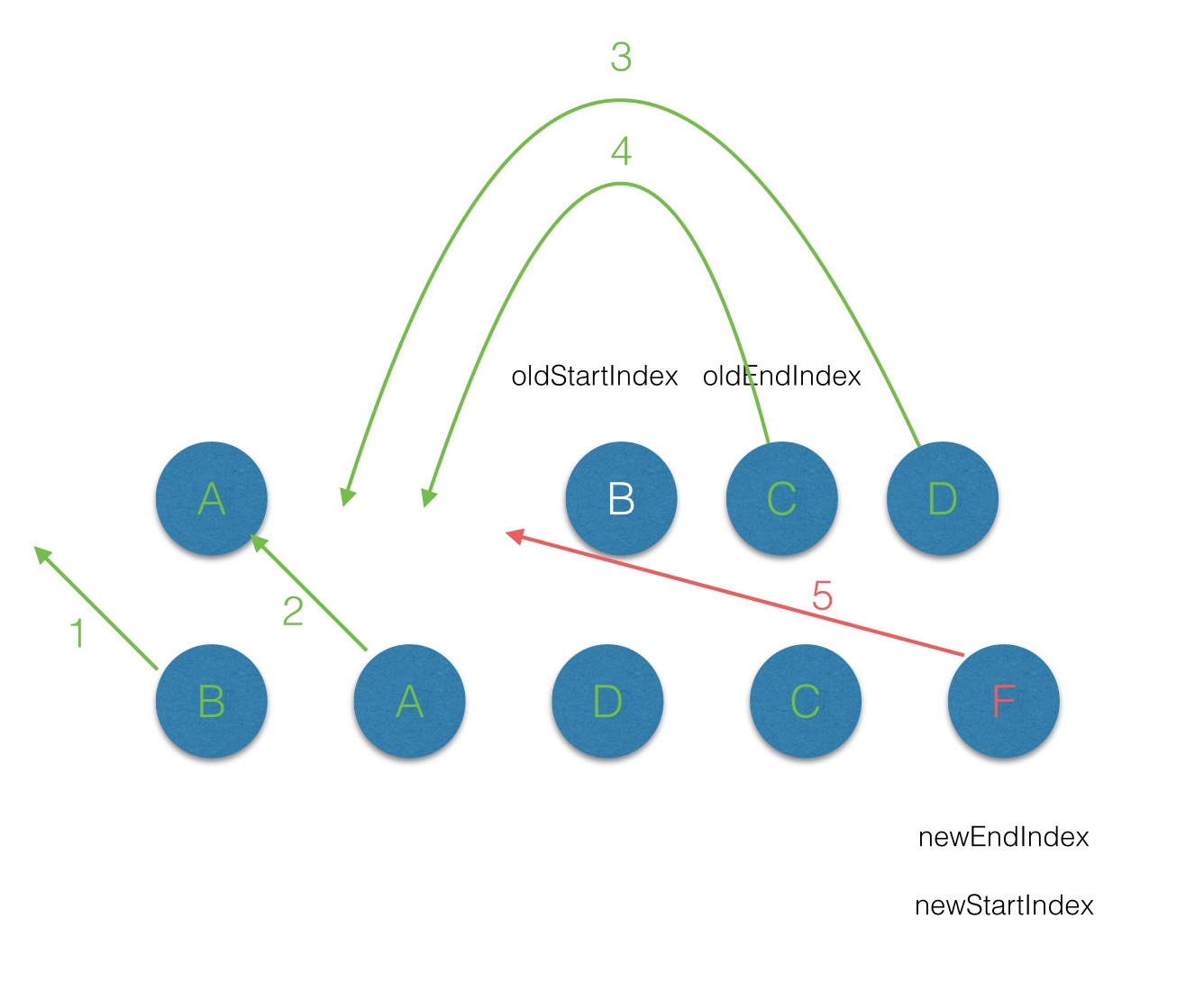
第五次遍历,发现没有f,新建f,移动到最后面。
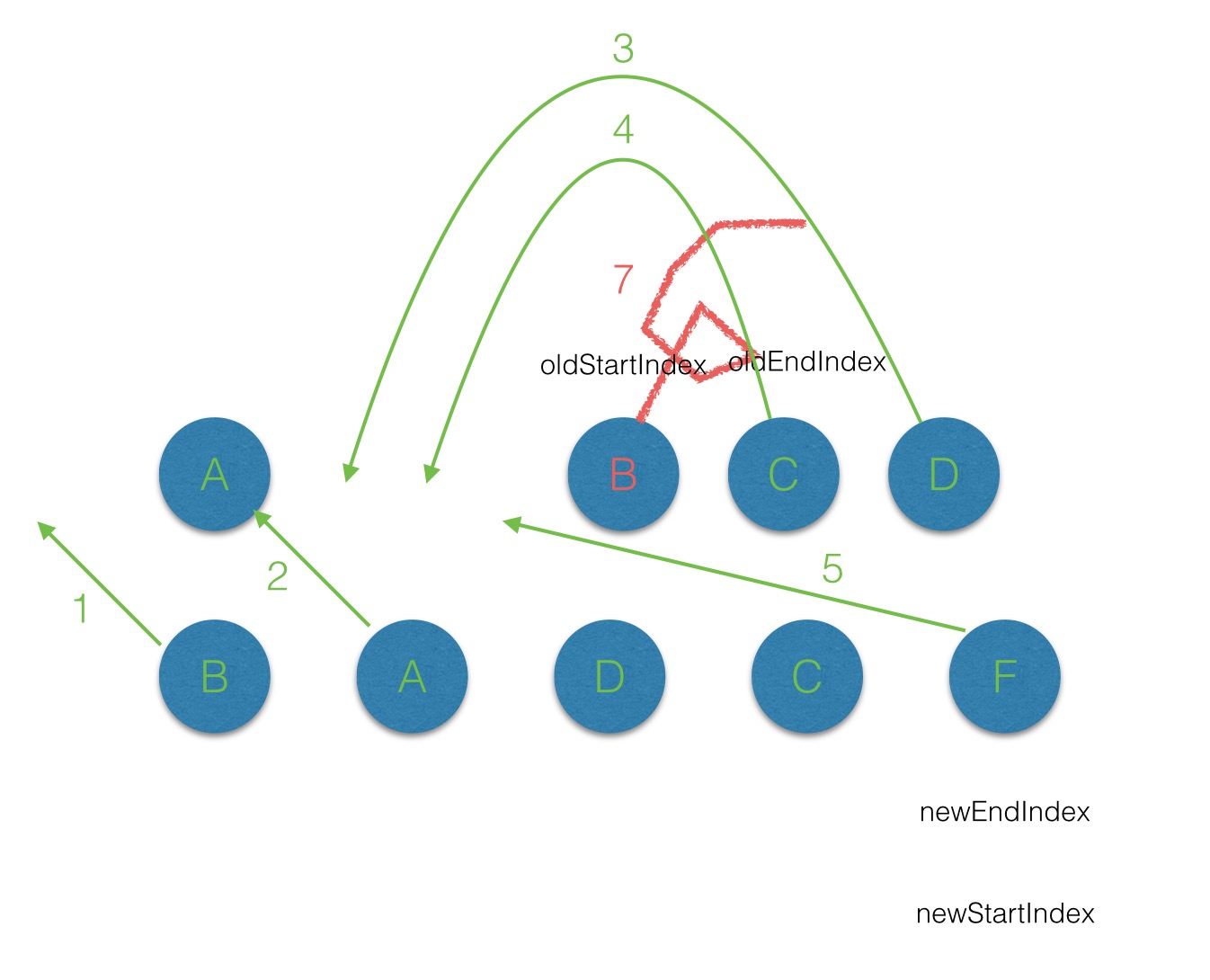
第六次遍历,发现老的里面还有b,删掉。
带key的情况下,第一次遍历的发现4个都不相等,然后从oldch的map里面取对应的dom。这样就只需要新建一次f的dom。
render
render比较简单,根据 type 生成对应的 DOM,把 data 里定义的 各种属性设置到 DOM 上。
function createElm(vnode, insertedVnodeQueue) {
let data = vnode.data
let i
// 省略 hook 调用
let children = vnode.children
let type = vnode.type
/// 根据 type 来分别生成 DOM
// 处理 comment
if (type === 'comment') {
if (vnode.text == null) {
vnode.text = ''
}
vnode.elm = api.createComment(vnode.text)
}
// 处理其它 type
else if (type) {
const elm = vnode.elm = data.ns
? api.createElementNS(data.ns, type)
: api.createElement(type)
// 调用 create hook
for (let i = 0; i < cbs.create.length; ++i) cbs.create[i](emptyNode, vnode)
// 分别处理 children 和 text。
// 这里隐含一个逻辑:vnode 的 children 和 text 不会/应该同时存在。
if (isArray(children)) {
// 递归 children,保证 vnode tree 中每个 vnode 都有自己对应的 dom;
// 即构建 vnode tree 对应的 dom tree。
children.forEach(ch => {
ch && api.appendChild(elm, createElm(ch, insertedVnodeQueue))
})
}
else if (isPrimitive(vnode.text)) {
api.appendChild(elm, api.createTextNode(vnode.text))
}
// 调用 create hook;为 insert hook 填充 insertedVnodeQueue。
i = vnode.data.hook
if (i) {
i.create && i.create(emptyNode, vnode)
i.insert && insertedVnodeQueue.push(vnode)
}
}
// 处理 text(text的 type 是空)
else {
vnode.elm = api.createTextNode(vnode.text)
}
return vnode.elm
}
详见https://github.com/creeperyang/blog/issues/33
react16的diff算法
可以先看下react16的结构(https://www.cnblogs.com/dh-dh/p/9361555.html),react16架构已经全改,新架构是利用了两个fiber链表进行dom的diff。
因为改成了链表不再是树结构,就采用了简单的两端比较法。而且它也拿不到两个链表的尾标进行比较。
跟之前的react处理方式大概一样,都是给diff打tag,然后一块commit,这点跟vue有些不同,vue是找到diff直接处理。
react这种打tag的做法比较好的把dom diff跟dom render分开了,使得跨平台得到比较好的处理。
const PLACEMENT = 1
const DELETION = 2
const UPDATE = 3
function placeChild(currentFiber, newChild) {
const type = newChild.type
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 如果这个节点没有 type ,这个节点就可能是 number 或者 string
return createFiber(tag.HostText, null, newChild, currentFiber, PLACEMENT)
}
if (typeof type === 'string') {
// 原生节点
return createFiber(tag.HOST_COMPONENT, newChild.type, newChild.props, currentFiber, PLACEMENT)
}
if (typeof type === 'function') {
const _tag = type.prototype.isReactComponent ? tag.CLASS_COMPONENT : tag.FunctionalComponent
return {
type: newChild.type,
tag: _tag,
props: newChild.props,
return: currentFiber,
effectTag: PLACEMENT
}
}
}
function reconcileChildrenArray(currentFiber, newChildren) {
// 对比节点,相同的标记更新
// 不同的标记 替换
// 多余的标记删除,并且记录下来
const arrayfiyChildren = arrayfiy(newChildren)
let index = 0
let oldFiber = currentFiber.alternate ? currentFiber.alternate.child : null
let newFiber = null
while (index < arrayfiyChildren.length || oldFiber !== null) {
const prevFiber = newFiber
const newChild = arrayfiyChildren[index]
const isSameFiber = oldFiber && newChild && newChild.type === oldFiber.type
if (isSameFiber) {
newFiber = {
type: oldFiber.type,
tag: oldFiber.tag,
stateNode: oldFiber.stateNode,
props: newChild.props,
return: currentFiber,
alternate: oldFiber,
partialState: oldFiber.partialState,
effectTag: UPDATE
}
}
if (!isSameFiber && newChild) {
newFiber = placeChild(currentFiber, newChild)
}
if (!isSameFiber && oldFiber) {
// 这个情况的意思是新的节点比旧的节点少
// 这时候,我们要将变更的 effect 放在本节点的 list 里
oldFiber.effectTag = DELETION
currentFiber.effects = currentFiber.effects || []
currentFiber.effects.push(oldFiber)
}
if (oldFiber) {
oldFiber = oldFiber.sibling || null
}
if (index === 0) {
currentFiber.child = newFiber
} else if (prevFiber && newChild) {
prevFiber.sibling = newFiber
}
index++
}
return currentFiber.child
}
大体过程就是遍历一下新链表,看一下新老链表的当前结点是不是同一个,如果是就打个update的标签,如果不同,直接替换当前fiber结构,打PLACEMENT标签。
如果没有新结点,老的存在,那就打个DELETION的tag。
可能会有一个问题,我没看到老fiber是从哪来的啊?
每个fiber会通过alternate连接另一个fiber,就是说我们操作的currentFiber是新fiber,currentFiber.alternate就是老fiber。
新fiber:newChild = arrayfiyChildren[index],老fiber用oldFiber.sibling遍历。
react有2个fiber 链表,一个做dom diff用,另一个做中断的备份用
virtual-dom的更多相关文章
- 窥探Vue.js 2.0 - Virtual DOM到底是个什么鬼?
引言 你可能听说在Vue.js 2.0已经发布,并且在其中新添加如了一些新功能.其中一个功能就是"Virtual DOM". Virtual DOM是什么 在之前,React和Em ...
- 个人对于Virtual DOM的一些理解
之前一直认为react的Virtual DOM操作会比传统的操作DOM要快,这其实是错误的,React 从来没有说过 "React 比原生操作 DOM 快".如果没有 Virtua ...
- 抛开react,如何理解virtual dom和immutability
去年以来,React的出现为前端框架设计和编程模式吹来了一阵春风.很多概念,无论是原本已有的.还是由React首先提出的,都因为React的流行而倍受关注,成为大家研究和学习的热点.本篇分享主要就聚焦 ...
- 深度剖析:如何实现一个 Virtual DOM 算法
本文转载自:https://github.com/livoras/blog/issues/13 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步 ...
- Virtual DOM 算法
前端 virtual-dom react.js javascript 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步骤一:用JS对象模拟DOM ...
- React v16-alpha 从virtual dom 到 dom 源码简读
一.物料准备 1.克隆react源码, github 地址:https://github.com/facebook/react.git 2.安装gulp 3.在react源码根目录下: $npm in ...
- React源码解析-Virtual DOM解析
前言:最近一直在研究React,看了陈屹先生所著的深入React技术栈,以及自己使用了这么长时间.对React应该说有比较深的理解了,正好前阵子也把两本关于前端设计模式的书看完了,总感觉有一种知识错综 ...
- virtual dom的实践
最近基于virtual dom 写了一个小框架-aoy. aoy是一个轻量级的mvvm框架,基于Virtual DOM.虽然现在看起来很单薄,但我做了完善的单元测试,可以放心使用.aoy的原理可以说和 ...
- 深度理解 Virtual DOM
目录: 1 前言 2 技术发展史 3 Virtual DOM 算法 4 Virtual DOM 实现 5 Virtual DOM 树的差异(Diff算法) 6 结语 7 参考链接 1 前言 我会尽量把 ...
- vue的Virtual Dom实现- snabbdom解密
vue在官方文档中提到与react的渲染性能对比中,因为其使用了snabbdom而有更优异的性能. JavaScript 开销直接与求算必要 DOM 操作的机制相关.尽管 Vue 和 React 都使 ...
随机推荐
- 如何正确使用Espresso来测试你的Android程序
UI测试在Android平台上一直都是一个令人头痛的事情, 由于大家平时用的很少, 加之很多文档的缺失, 如果很多东西从头摸索,势必踩坑无数. 自Android24正式淘汰掉了Instrumentat ...
- Android studio设置文件头,定制代码注释
一.说明 在下载或者看别人的代码我们常会看见,每一个文件的上方有个所属者的备注.如果要是一个一个备注那就累死了. 二.设置方法 File >>> Setting >>&g ...
- Android PAI (PlayAutoInstall)预装APK 功能
最近刚找到工作,是手机方案公司,刚接触手机系统预装的APP,以及解决方案MTK平台下预装APP的bug,也接触到了Launcher的东西. 然后接触到了第一个需求 PAI预装APK功能 下面是我用到的 ...
- hadoop1.0 和 Hadoop 2.0 的区别
1.Hadoop概述 在Google三篇大数据论文发表之后,Cloudera公司在这几篇论文的基础上,开发出了现在的Hadoop.但Hadoop开发出来也并非一帆风顺的,Hadoop1.0版本有诸多局 ...
- 如何制作中文Javadoc包,并导入到Eclipse
原理:使用chm转换工具将chm文件转换为zip文件,导入eclipse中即可. 准备 JDK1.9 API 中文 谷歌翻译版:http://www.pc6.com/softview/SoftView ...
- Linux Collection:软件配置
PAS Debian 9安装最新版Firefox( Firefox 58+/Quantum) Debian 9(Strech)的仓库包含的是firefox-esr(52)版本:需要安装最新版,有如下两 ...
- RabbitMQ远程执行任务RPC。
如果想发一条命令给远程机器,再把结果返回 这种模式叫RPC:远程过程调用 发送方将发送的消息放在一个queue里,由接收方取. 接收方再把执行结果放在另外一个queue里,由发送方取 实际上,发送方把 ...
- ThreadLocal的使用及原理分析
文章简介 ThreadLocal应该都比较熟悉,这篇文章会基于ThreadLocal的应用以及实现原理做一个全面的分析 内容导航 什么是ThreadLocal ThreadLocal的使用 分析Thr ...
- Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1)
Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1) In this Document Symptoms Cause ...
- BZOJ3711 Druzyny 最大值分治、线段树
传送门 被暴力包菜了,然而还不会卡-- 有一个很暴力的DP:设\(f_i\)表示给\(1\)到\(i\)分好组最多可以分多少组,转移枚举最后一个组.接下来考虑优化这个暴力. 考虑:对于每一个位置\(i ...