学习笔记--python中使用多进程、多线程加速文本预处理
一.任务描述
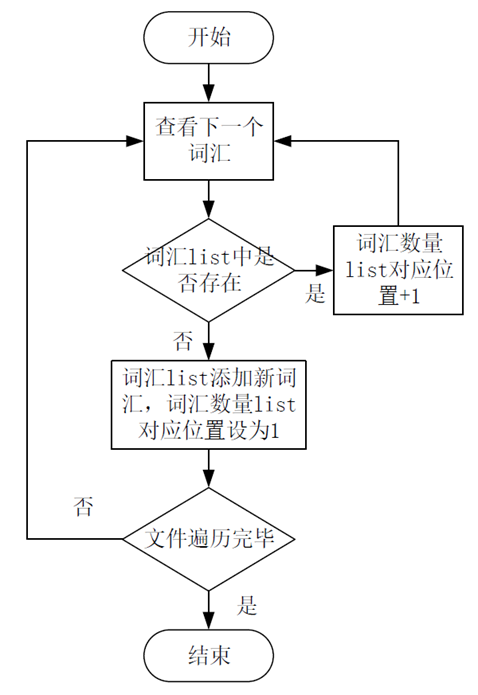
最近尝试自行构建skip-gram模型训练word2vec词向量表。其中有一步需要统计各词汇的出现频率,截取出现频率最高的10000个词汇进行保留,形成常用词词典。对于这个问题,我建立了两个list,词汇list 和 词汇数量list,分别记录新出现的词汇和该词汇出现的次数。遍历整个语料文件,收集各个词汇并计算其出现次数。最后,对词汇数量list进行降序排序,留下出现频率最高的10000个词汇。流程大致如下图:
二.问题描述
在程序实际运行的过程中,发现程序运行的速度实在是太慢。对于一个4000行的示例语料文件,分词+统计词频一共花费384秒。而此次目标的语料文件一共有上百万行,随着语料的扩充,词汇量也势必增大,每次对词汇list的检索开销也会有所上升。那么如何提高程序的运行速度呢?
三.问题解决思路
在未优化的程序运行过程中,我们发现电脑的CPU利用率一直处于20%左右,远未达到其最大负载功率,因此便想到使用多线程、多进程来并行的对文本进行处理,以提高处理效率。
思路如下:
由于我的电脑是八核CPU,因此我将语料文件平均分成八份,开启8个线程/进程来对这些语料数据进行处理。待八个进程/线程的工作结束后,再对结果进行拼接。
四.使用多线程程序处理语料文件。
python中多线程可以使用threading模块进行调用
具体调用语句为threading.Thread(target=函数名,args=(参数列tuple)),因此,首先的工作就是编写线程工作函数。
1.预设如下全局变量用于存储每个线程的输出结果。
# TODO 全局变量 TODO
pured_file = '../dataset/news_sohusite_xml_pure_200M_lines_content.txt' # 未切分语料地址
corp_list_all = [] # jieba分词过后的语料文件
for i in range(8):
corp_list_all.append([])
dict_list_all = [] # 用于每个进程的词汇列表
for i in range(8):
dict_list_all.append([])
dict_list_index_all = [] #用于每个进程的 词汇列表对于的出现次数。
for i in range(8):
dict_list_index_all.append([])
finish_tag = [0,0,0,0,0,0,0,0]
# TODO 全局变量 TODO
线程工作函数如下
def cut_content_to_dict(c_lines,thread_index):
print("thread %s, length %s"%(str(thread_index),str(len(c_lines))))
splited_list = []
for sentences in c_lines:
words = jieba.cut(sentences,cut_all=False)
words = ' '.join(words) # 使用 空格 将每一个词汇隔开 此时是str类型变量。
splited_list.append(words[:-1]) # 去除句末的 '\n'
corp_list_all[thread_index] = splited_list # 将分词结果存入全局变量
word_index_list = [] #临时存储词汇列表
word_num_list = [] #临时存储词汇出现次数
count = 0
for item in splited_list:
words = item.split(' ')
for wd in words:
if wd in word_index_list:
word_num_list[word_index_list.index(wd)] += 1 # 有这个单词,则对应计数加1
else:
word_index_list.append(wd)
word_num_list.append(1)
if count%250==0:
print("thread %s, finished %s"%(str(thread_index),str(count)))
count+=1
dict_list_all[thread_index] = word_index_list #将词汇表存入全局变量对应位置
dict_list_index_all[thread_index] = word_num_list #将词汇频率存入全局变量对应位置
finish_tag[thread_index] = 1
if 0 not in finish_tag: # finish_tag 全为1 时,启用拼接函数
put_together()
其中,finish_tag全局变量用于检测是否所有线程都已工作完毕,其初始化为[0,0,0,0,0,0,0,0],待所有线程工作完毕后会成为全1向量,此时调用拼接函数put_together()对dict_list_all中的词汇进行拼接。
在main函数中,将语料数据分成8块,分别分配给各个线程,再对线程轮流进行启动:
with open(pured_file,'r',encoding='utf-8') as content_file:
lines = content_file.readlines()
lines = lines[:4000]
block_size = int(len(lines)/8)
tasks_8 = []
for i in range(7):
tasks_8.append(lines[i*block_size:(i+1)*block_size])
tasks_8.append(lines[7*block_size:])
thread_list = []
for i in range(8):
thread_list.append(threading.Thread(target=cut_content_to_dict, args=(tasks_8[i],i)))
for i in range(8):
thread_list[i].start()
经过这番改造,使用多线程处理4000行的示例语料文件共花费197秒,比未优化的代码速度提高了几乎一倍。但是通过观察CPU使用率,发现CPU并未全功率运行,占用率仍在20%多徘徊。因此尝试使用多进程来完成语料分词、统计任务。
五.使用多进程处理语料文件
python中多进程可以使用multiprocessing模块进行调用,与多线程的不同之处在于,每个子进程会单独划分一份资源,因此不能使用全局变量的方式来对子进程输出结果进行存储。multiprocessing模块提供了特殊的变量类型multiprocessing.Manager().list(),multiprocessing.Value()来获取子进程的输出结果。
首先编写进程工作函数:
# array_c,array_di,array_dn 是三个multiprocessing.Manager().list 类型变量,可以用于返回输出结果
def cut_content_to_dict(c_lines,proc_index,array_c,array_di,array_dn):
print("process %s, length %s"%(str(proc_index),str(len(c_lines))))
for sentences in c_lines:
words = jieba.cut(sentences,cut_all=False)
words = ' '.join(words) # 使用 空格 将每一个词汇隔开 此时是str类型变量。
array_c.append(words[:-1]) # 去除句末的 '\0'
count = 0
for item in array_c:
words = item.split(' ')
for wd in words:
if wd in array_di:
array_dn[array_di.index(wd)] += 1 # 有这个单词,则对应计数加1
else:
array_di.append(wd)
array_dn.append(1)
if count%250==0:
print("process %s, finished %s"%(str(proc_index),str(count)))
count+=1
与之前的线程函数相比,这个进程函数多了很多参数,其中,array_c代表传入的语料数据,array_di,array_dn对应多线程代码中dict_list_all和dict_list_index_all,分别表示词汇list和词汇数量list。这种传递返回值的方式类似C语音中的指针调用。另外,multiprocessing.Value()类型的变量proc_index用于对子进程进行标注,记录该进程的执行进度。
在main函数中,需要额外一步初始化multiprocessing.Manager().list()类型和multiprocessing.Value()变量。
proc_id = []
corp_list_all = [] # jieba分词过后的语料文件
dict_list_all = [] # 用于每个进程的词汇列表
dict_list_index_all = [] #用于每个进程的 词汇列表对于的出现次数。
for i in range(8):
corp_list_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list
for i in range(8):
dict_list_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list
for i in range(8):
dict_list_index_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list
for i in range(8):
proc_id.append(multiprocessing.Value("i",i)) # "i" 表示int类型, 第二个i表示初始数值
在对每个进程进行调用时,分别传入这些参数。
p_list = [] # 用于存储8个进程
for i in range(8):
p = multiprocessing.Process(target=cut_content_to_dict,args=(tasks_8[i],proc_id[i],\
corp_list_all[i],dict_list_all[i],dict_list_index_all[i]))
p_list.append(p)
for p in p_list:
p.start()
for p in p_list:
p.join()
# 所有进程结束后,调用拼接函数
put_together(corp_list_all,dict_list_all,dict_list_index_all)
经过测试,使用多进程运行的代码处理4000行语料数据共花费159秒的时间,比多线程代码的运行速度又有所提高,同时CPU利用率也提升到了100%。
以上代码可用在我的GitHub中找到(https://github.com/NosenLiu/DIY_Word2Vec)。后续还将根据此次预处理结果构建一个skip-gram以训练出一个word2vec词向量表,有兴趣的同学可以下载进行参考。
学习笔记--python中使用多进程、多线程加速文本预处理的更多相关文章
- 聊聊Python中的多进程和多线程
今天,想谈一下Python中的进程和线程. 最近在学习Django的时候,涉及到了多进程和多线程的知识点,所以想着一下把Python中的这块知识进行总结,所以系统地学习了一遍,将知识梳理如下. 1. ...
- python中的多进程与多线程(二)
1.使用多线程可以有效利用CPU资源,线程享有相同的地址空间和内存,这些线程如果同时读写变量,导致互相干扰,就会产生并发问题,为了避免并发问题,绝不能让多个线程读取或写入相同的变量,因此python中 ...
- 深入浅析python中的多进程、多线程、协程
深入浅析python中的多进程.多线程.协程 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源 ...
- Python学习笔记6-Python中re(正则表达式)模块学习
今天学习了Python中有关正则表达式的知识.关于正则表达式的语法,不作过多解释,网上有许多学习的资料.这里主要介绍Python中常用的正则表达式处理函数. re.match re.match 尝试从 ...
- Python中使用多进程来实现并行处理的方法小结
进程和线程是计算机软件领域里很重要的概念,进程和线程有区别,也有着密切的联系,先来辨析一下这两个概念: 1.定义 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和 ...
- MongoDB学习笔记:Python 操作MongoDB
MongoDB学习笔记:Python 操作MongoDB Pymongo 安装 安装pymongopip install pymongoPyMongo是驱动程序,使python程序能够使用Mong ...
- Python中的鸡肋多线程
作者:DarrenChan陈驰链接:https://www.zhihu.com/question/23474039/answer/269526476来源:知乎著作权归作者所有.商业转载请联系作者获得授 ...
- ArcGIS案例学习笔记-点集中最近点对和最远点对
ArcGIS案例学习笔记-点集中最近点对和最远点对 联系方式:谢老师,135-4855-4328,xiexiaokui@qq.com 目的:对于点图层,查找最近的点对和最远的点对 数据: 方法: 1. ...
- 《Cocos2d-x游戏开发实战精解》学习笔记3--在Cocos2d-x中播放声音
<Cocos2d-x游戏开发实战精解>学习笔记1--在Cocos2d中显示图像 <Cocos2d-x游戏开发实战精解>学习笔记2--在Cocos2d-x中显示一行文字 之前的内 ...
随机推荐
- [转]关于Megatops BinCalc RPN计算器的说明
最近收到几个好心人发来的邮件,指出我的BinCalc存在低级BUG,即1+1算出来不等于2--鉴于存在这种误解的人之多,俺不得不爬出来澄清一下--我的Megatops BinCalc当中的计算器是RP ...
- SQL Server 2005 企业版没有 Microsoft SQL Server Management
我从网上下载的:SQL Server 2005 集成sp2的 企业版安装后没发现 Management Studio管理工具,起初以为是自己安装时没装上,昨天试了全部安装后还是没找到,很是郁闷,在网上 ...
- python_内置函数
#内置函数 #1.abs 获取绝对值 # abs(-10) # --->10 # # abs(10) # --->10 # # abs(0) # --->0 #2.all() 参数为 ...
- Ubuntu gitlab安装文档及邮件通知提醒配置
1.安装依赖包,运行命令 sudo apt-get install curl openssh-server ca-certificates postfix 2.由于gitlab官方源可能被“墙”,首先 ...
- 八大排序算法——快速排序(动图演示 思路分析 实例代码Java 复杂度分析)
一.动图演示 二.思路分析 快速排序的思想就是,选一个数作为基数(这里我选的是第一个数),大于这个基数的放到右边,小于这个基数的放到左边,等于这个基数的数可以放到左边或右边,看自己习惯,这里我是放到了 ...
- 《Python量化交易教程》第一部分新手入门 第1天:谁来给我讲讲Python?
一.量化投资视频学习课程 二.Python手把手教学 第1天:谁来给我讲讲Python? PS: 1.注意使用方法,这个以后都有大用 2.注意符号的使用方式 3.尽量用英文表达 4.本日学习内容以及其 ...
- week6
面向对象编程 class类(新式类:class xx(obj):,经典类 class xx:) 构造函数 __init__(self,ret1,ret2...) 在实例化时做一些类的初始化工作 析构函 ...
- Python P图
Python PIL PIL (Python Image Library) 库是Python 语言的一个第三方库,PIL库支持图像存储.显示和处理,能够处理几乎所有格式的图片. 一.PIL库简介 1. ...
- 使用Selenium IDE和webDriver进行自动化软件测试
1.Selenium IDE 在Chrome浏览器上登录谷歌应用商店可以安装Selenium IDE插件(3.0以上版本的Selenium IDE不支持录制的脚本导出,所以这里使用到的是应用商店上的另 ...
- 2、CentOS下编译安装Python2.7.6(转)
CentOS系统下面Python在升级到2.7.6的时候,没有找到安装包直接安装,只能通过源代码编译的方式来安装Python 2.7.6版本.这篇是编译和安装Python2.7.6的过程记录. Cen ...