【页面置换算法】LRC算法和FIFS算法
- 算法介绍
- FIFO:该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针,使它总是指向最老的页面。但该算法与进程实际运行的规律不相适应,因为在进程中,有些页面经常被访问,比如,含有全局变量、常用函数、例程等的页面,FIFO 算法并不能保证这些页面不被淘汰。
- LRU(least recently used)是将近期最不会访问的数据给淘汰掉,LRU是认为最近被使用过的数据,那么将来被访问的概率也多,最近没有被访问,那么将来被访问的概率也比较低。LRU算法简单,存储空间没有被浪费,所以还是用的比较广泛的。
- 实现思路
- 数组作为内存块,另一个数组存储页号
- FIFS:
读入的页号首先在内存块中查找,没有查找到,当前物理块若为空,则调入页号,若非空,则按照先到先出的顺序,调入调出,若查找到页号,则继续查找下一个。
- LUR:
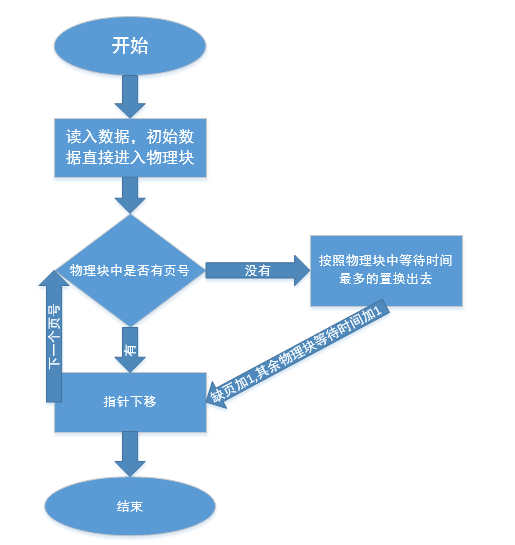
内存块为空时,先读入的页号进入内存块直到内存块满,将其等待时间都置为0,接下来的页号,如果在内存块中找到,则将该页号的等待时间置为0,若找不到,则查找内存块中等待时间最长的页号置换出去,新进来的页号等待时间置为0。然后将内存块中其余页号的等待时间都加1。
流程图:
lur:
FIFS:

- 代码
#include<iostream>
using namespace std;
//伪代码: 内存大小,作业号,
//物理块,
int a[],len,b[],i,j,n;
int c[][]; void readn(int n){ cout<<"请输入页面号(-1结束)";
len=;
int m=;
while(m!=-){
cin>>a[len];
m=a[len];
len++;
}
len=len-;
cout<<"输入完毕"<<endl;
// for( j=0;j<len;j++){
// cout<<a[j];
// }
} void FIFO(int n,int a[]){
int cnum=;
for( j=;j<n;j++){
b[j]=a[j]; }
//输出第一个b[n],
cout<<"当前物理块存放的页号:";
for( j=;j<n;j++){
cout<<b[j]<<" ";
}
cout<<endl;
int x=,flag=,sum=;
for( i=n-;i<len;i++){ for( j=;j<n;j++){
if(a[i]==b[j])
break;
}
int q=x;
if(j>=n){
b[x]=a[i];
x=(x+)%n; flag=;
sum++;
}
if(flag==){
cout<<"置换了b["<<q<<"]"<<endl;
}
cout<<"当前物理块存放的页号:";
for( j=;j<n;j++){
cout<<b[j]<<" ";
}
cout<<endl;
flag=;
}
//计算缺页率
cout<<"FIFO缺页次数:"<<sum+n<<endl;
cout<<"FIFO置换次数:"<<sum <<endl;
cout<<"FIFO缺页率:"<<(double)(sum+n)/len<<endl; } void LRU(int n,int a[]){ int cnum=;
for( j=;j<n;j++){
c[j][]=a[j];
c[j][]=;
}
//输出第一个b[n],
cout<<"当前物理块存放的页号:";
for( j=;j<n;j++){
cout<<c[j][]<<" ";
}
cout<<endl;
int x=,flag=,sum=;
for( i=n-;i<len;i++){
//查找在不在内存里面
for( j=;j<n;j++){
if(a[i]==c[j][]){
c[j][]=;//将时间恢复为0 //等待的时间加1
for(int k=;k<n;k++){
if(c[k][]!=a[i]){
c[k][]++;
}
}
break;
} }
int q;
if(j>=n){//不在内存里面,找最久没用的
int tmp=c[x][],zhen=x;
for(int l=;l<n;l++){
if(c[l][]>tmp){
tmp=c[l][];
zhen=l;
}
}
x=zhen;
q=x;
c[x][]=a[i];
c[x][]=;
for(int k=;k<n;k++){
if(c[k][]!=a[i]){
c[k][]++;
}
}
x=(x+)%n;
flag=;
sum++;
}
if(flag==){
cout<<"置换了c["<<q<<"]"<<endl;
}
cout<<"当前物理块存放的页号:";
for( j=;j<n;j++){
cout<<c[j][]<<" ";
}
cout<<endl;
flag=;
}
//计算缺页率
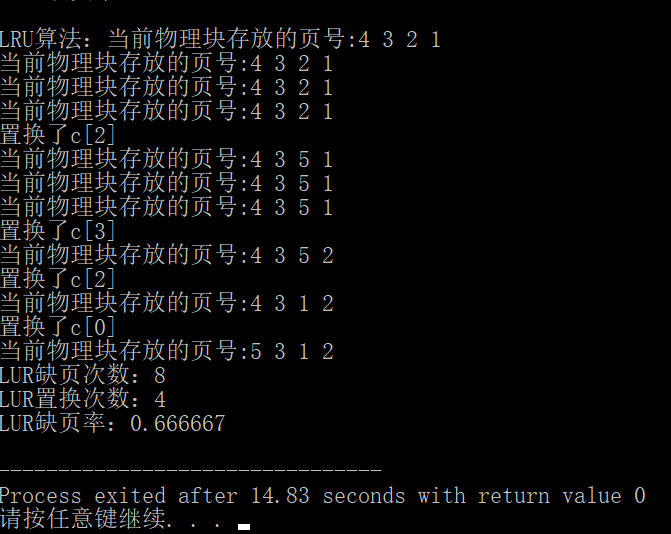
cout<<"LUR缺页次数:"<<sum+n<<endl;
cout<<"LUR置换次数:"<<sum <<endl;
cout<<"LUR缺页率:"<<(double)(sum+n)/len<<endl; } int main(){
//物理块
cout<<"请输入物理块大小";
cin>>n;
readn(n);
cout<<"FIFO算法:";
FIFO(n,a);
cout<<endl;
cout<<"LRU算法:";
LRU(n,a); return ;
}- 运行结果

【页面置换算法】LRC算法和FIFS算法的更多相关文章
- 网络流之最大流算法(EK算法和Dinc算法)
最大流 网络流的定义: 在一个网络(有流量)中有两个特殊的点,一个是网络的源点(s),流量只出不进,一个是网络的汇点(t),流量只进不出. 最大流:就是求s-->t的最大流量 假设 u,v 两个 ...
- 单源最短路径算法——Bellman-ford算法和Dijkstra算法
BellMan-ford算法描述 1.初始化:将除源点外的所有顶点的最短距离估计值 dist[v] ← +∞, dist[s] ←0; 2.迭代求解:反复对边集E中的每条边进行松弛操作,使得顶点集V ...
- TCP_NODELAY和TCP_CORK nagle算法和cork算法
TCP_NODELAY 默认情况下,发送数据採用Nagle 算法.这样尽管提高了网络吞吐量,可是实时性却减少了,在一些交互性非常强的应用程序来说是不同意的.使用TCP_NODELAY选项能够禁止Nag ...
- FIFO调度算法和LRU算法
一.理论 FIFO:先进先出调度算法 LRU:最近最久未使用调度算法 两者都是缓存调度算法,经常用作内存的页面置换算法. 打一个比方,帮助你理解.你有很多的书,比如说10000本.由于你的书实在太多了 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- 转载:最小生成树-Prim算法和Kruskal算法
本文摘自:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/30/2615542.html 最小生成树-Prim算法和Kruskal算法 Prim算 ...
- 0-1背包的动态规划算法,部分背包的贪心算法和DP算法------算法导论
一.问题描述 0-1背包问题,部分背包问题.分别实现0-1背包的DP算法,部分背包的贪心算法和DP算法. 二.算法原理 (1)0-1背包的DP算法 0-1背包问题:有n件物品和一个容量为W的背包.第i ...
随机推荐
- # 20175333曹雅坤《Java程序设计》第四周学习总结
教材学习内容总结 第五章:子类与继承 5.1子类与父类:关键字extends 5.2子类的继承性:如果子类与父类在一个包中,除了private其他都可以继承:如果不在一个包中,则private和友好都 ...
- 【转】一文掌握 Linux 性能分析之内存篇
[转]一文掌握 Linux 性能分析之内存篇 前面我们已经学习了 CPU 篇,这篇来看下内存篇. 01 内存信息 同样在分析内存之前,我们得知到怎么查看系统内存信息,有以下几种方法. 1.1 /pro ...
- ubuntu系统检测端口占用情况
参考链接: https://blog.csdn.net/qwfys200/article/details/80837036 命令: $ sudo netstat -tupln
- 奇yin技巧
关于一些奇yin技巧 关于删除字符串中的一些字串,并且考虑新的字串 例题:luogu4824 luogu3121 方法:开一个栈记录,发现字串后剪去字串长度. for(int i=1;i<=le ...
- 微服务杂谈--EureKa及自我保护
时值初夏,各位老官的心也有所悸动,这不,众看官搬好小板凳,沏一壶清茶,待听Jerry话谈Eureka,以此静心.话不多少,且听: 一.微服务的产生 单体应用:一个jar或者一个war包交给运维,运行在 ...
- mysql_config not found和error: command 'gcc' failed with exit status 1
要想使python可以操作mysql 就需要MySQL-python驱动,它是python 操作mysql必不可少的模块. 下载地址:https://pypi.python.org/pypi/MySQ ...
- jQuery概念
- JAVA -数据类型与表达式---字符串
字符串 Java中,字符串就是对象,它由 String类定义.字符串是计算机程序设计中非常基础的类型,因此Java允许定义字符串常量(string literal),并以双引号作为字符串的定界符. 一 ...
- tp5 修改默认的分页url
默认分页url:xx.com/xxx?page=1 个人主要感觉不美观,想变成xx.com/xxx/list_1.html这样的 框架本身默认使用的boostrap分页类,目录位置 simplewin ...
- 仓位管理 V4.3
之前设计的仓位管理算法一直比较有效,往往能在市场的不断的上涨下跌中获利.不过感觉短期变动的仓位占整体的仓位较低,使得盈利较低.所以这个月对仓位管理算法进行了升级,尝试了几个版本.这里做一个记录. V4 ...