MapReduce的工作原理
MapReduce简介
MapReduce有哪些角色?各自的作用是什么?
MapReduce程序执行流程
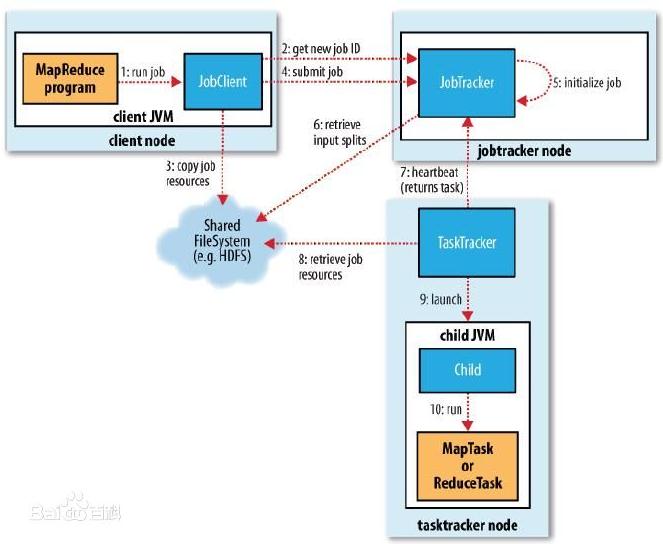
MapReduce工作原理
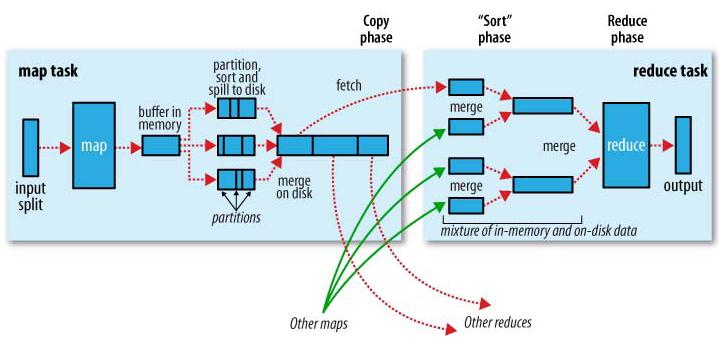
reduce task
MapReduce中Shuffle过程


MapReduce编程主要组件
针对MapReduce的缺点,YARN解决了什么?
MapReduce的工作原理的更多相关文章
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- 【hadoop】细读MapReduce的工作原理
前言:中秋节有事外加休息了一天,今天晚上重新拾起Hadoop,但感觉自己有点烦躁,不知后续怎么选择学习Hadoop的方法. 干脆打开电脑,决定: 1.先将Hadoop的MapReduce和Yarn基本 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
随机推荐
- 关于npm镜像,发布,内网搭建等
npm config set registry http://registry.npmjs.org npm config set registry https://registry.npm.taoba ...
- 解释内存中的栈(stack)、堆(heap)和静态区(static area)的用法
堆区:专门用来保存对象的实例(new 创建的对象和数组),实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型标记等,并不保存对象的方法(方法是指令,保存在Stack中) 1.存储的全部是对象 ...
- python vs C++ 类
1. 什么是动态语言(wikipedia) 在运行时,可以进行一些操作(静态语言在编译时执行),比如扩展对象的定义.修改类型等 2. 定义类和创建对象 C++ python class A{ publ ...
- spring+myBatis 配置多数据源,切换数据源
注:本文来源于 tianzhiwuqis <spring+myBatis 配置多数据源,切换数据源> 一个项目里一般情况下只会使用到一个数据库,但有的需求是要显示其他数据库的内容,像这样 ...
- (转载)配置 Linux 操作系统的 JDK
系统Ubuntu,下载jdk-9.0.1 1,切换到root ,创建文件夹 xxxx@ubuntu:~$ sudo su root@ubuntu:~# mkdir /usr/java 2,找到下载 ...
- MySQL/Oracle数据库优化总结
MySQL数据库优化的八种方式 1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能 ...
- C语言作业3
一.实验目的与要求 1.用for语句实现循环 (1)求数列前n项和 掌握for语句实现循环的方法 (2)求数列前n项和 掌握for语句实现循环的方法 循环嵌套的使用 2.用while循环语句实现循环 ...
- Finally! I do understand "flex-basis"
Long, long, long ago,CSS3就支持了flex布局,现在各家浏览器都支持标准的语法了,这里推荐一篇比较全面的图文化教程A Complete Guide to Flexbox. 关于 ...
- Gradle 下载的依赖包在什么位置?
Mac系统默认下载到:/Users/(用户名)/.gradle/caches/modules-2/files-2.1Windows系统默认下载到:C:\Users\(用户名)\.gradle\cach ...
- DevExpress控件库 开发使用经验总结3 制作项目安装包
2015-01-27 使用DevExpress控件包开发C/S项目完成后,部署前需要制作本地安装包.本文还是使用“SetupFactory”安装工厂来制作安装包.在以前的系列文章中详细介绍过该工具的使 ...