特征选择:Filter/Wrapper/Embedded
一、特征的来源
在做数据分析的时候,特征的来源一般有两块,一块是业务已经整理好各种特征数据,我们需要去找出适合我们问题需要的特征;另一块是我们从业务特征中自己去寻找高级数据特征。我们就针对这两部分来分别讨论。
二、选择合适的特征
我们首先看当业务已经整理好各种特征数据时,我们如何去找出适合我们问题需要的特征,此时特征数可能成百上千,哪些才是我们需要的呢?
第一步是找到该领域懂业务的专家,让他们给一些建议。比如我们需要解决一个药品疗效的分类问题,那么先找到领域专家,向他们咨询哪些因素(特征)会对该药品的疗效产生影响,较大影响的和较小影响的都要。这些特征就是我们的特征的第一候选集。
这个特征集合有时候也可能很大,在尝试降维之前,我们有必要用特征工程的方法去选择出较重要的特征结合,这些方法不会用到领域知识,而仅仅是统计学的方法。
最简单的方法就是方差筛选。方差越大的特征,那么我们可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。在实际应用中,我们会指定一个方差的阈值,当方差小于这个阈值的特征会被我们筛掉。sklearn中的VarianceThreshold类可以很方便的完成这个工作。
特征选择方法有很多,一般分为三类:第一类过滤法比较简单,它按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征。上面我们提到的方差筛选就是过滤法的一种。第二类是包装法,根据目标函数,通常是预测效果评分,每次选择部分特征,或者排除部分特征。第三类嵌入法则稍微复杂一点,它先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征。类似于过滤法,但是它是通过机器学习训练来确定特征的优劣,而不是直接从特征的一些统计学指标来确定特征的优劣。下面我们分别来看看3类方法。
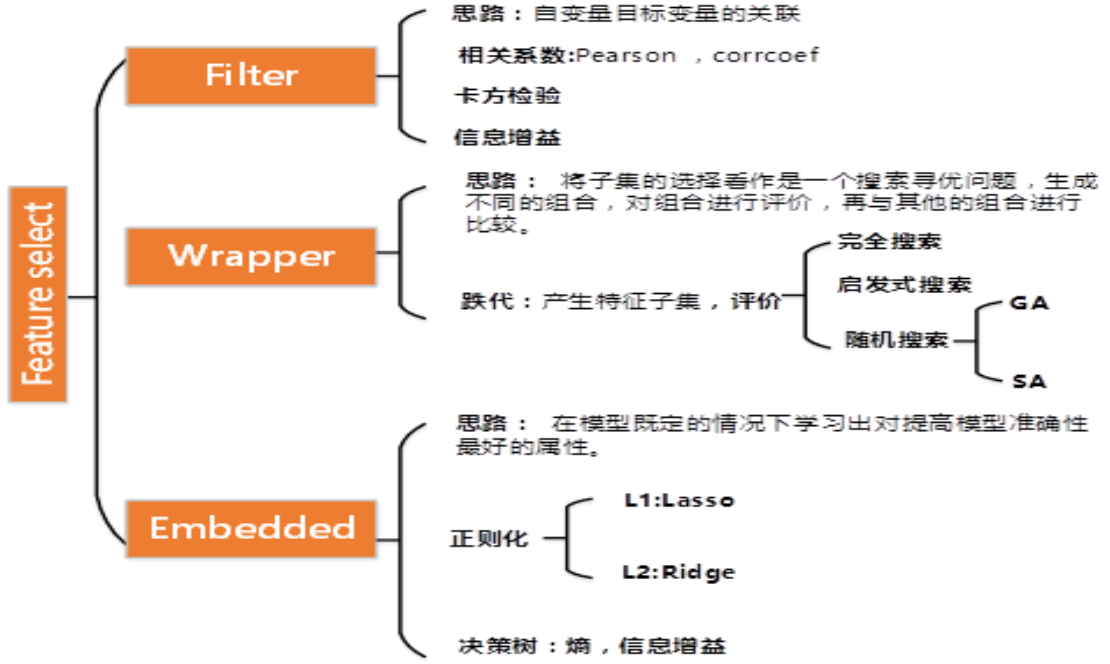
1. 过滤法选择特征
第二个可以使用的是相关系数。这个主要用于输出连续值的监督学习算法中。我们分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。
第三个可以使用的是假设检验,比如卡方检验。卡方检验可以检验某个特征分布和输出值分布之间的相关性。个人觉得它比粗暴的方差法好用。如果大家对卡方检验不熟悉,可以参看这篇卡方检验原理及应用,这里就不展开了。在sklearn中,可以使用chi2这个类来做卡方检验得到所有特征的卡方值与显著性水平P临界值,我们可以给定卡方值阈值, 选择卡方值较大的部分特征。
除了卡方检验,我们还可以使用F检验和t检验,它们都是使用假设检验的方法,只是使用的统计分布不是卡方分布,而是F分布和t分布而已。在sklearn中,有F检验的函数f_classif和f_regression,分别在分类和回归特征选择时使用。
第四个是互信息,即从信息熵的角度分析各个特征和输出值之间的关系评分。在决策树算法中我们讲到过互信息(信息增益)。互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。在sklearn中,可以使用mutual_info_classif(分类)和mutual_info_regression(回归)来计算各个输入特征和输出值之间的互信息。
以上就是过滤法的主要方法,个人经验是,在没有什么思路的时候,可以优先使用卡方检验和互信息来做特征选择。
2. 包装法选择特征
包装法的解决思路没有过滤法这么直接,它会选择一个目标函数来一步步的筛选特征。
最常用的包装法是递归消除特征法(recursive feature elimination,以下简称RFE)。递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数的对应的特征,再基于新的特征集进行下一轮训练。在sklearn中,可以使用RFE函数来选择特征。
我们下面以经典的SVM-RFE算法来讨论这个特征选择的思路。这个算法以支持向量机来做RFE的机器学习模型选择特征。它在第一轮训练的时候,会选择所有的特征来训练,得到了分类的超平面wx˙+b=0后,如果有n个特征,那么RFE-SVM会选择出w中分量的平方值wi2最小的那个序号i对应的特征,将其排除,在第二类的时候,特征数就剩下n-1个了,我们继续用这n-1个特征和输出值来训练SVM,同样的,去掉wi2最小的那个序号i对应的特征。以此类推,直到剩下的特征数满足我们的需求为止。
3. 嵌入法选择特征
最常用的是使用L1正则化和L2正则化来选择特征。在之前讲到的用scikit-learn和pandas学习Ridge回归第6节中,我们讲到正则化惩罚项越大,那么模型的系数就会越小。当正则化惩罚项大到一定的程度的时候,部分特征系数会变成0,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0. 但是我们会发现一部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。也就是说,我们选择特征系数较大的特征。常用的L1正则化和L2正则化来选择特征的基学习器是逻辑回归。
此外也可以使用决策树或者GBDT。那么是不是所有的机器学习方法都可以作为嵌入法的基学习器呢?也不是,一般来说,可以得到特征系数coef或者可以得到特征重要度(feature importances)的算法才可以做为嵌入法的基学习器。
三、寻找高级特征
在Kaggle之类的算法竞赛中,高分团队主要使用的方法除了集成学习算法,剩下的主要就是在高级特征上面做文章。所以寻找高级特征是模型优化的必要步骤之一。当然,在第一次建立模型的时候,我们可以先不寻找高级特征,得到以后基准模型后,再寻找高级特征进行优化。
寻找高级特征最常用的方法有:
- 若干项特征加和: 我们假设你希望根据每日销售额得到一周销售额的特征。你可以将最近的7天的销售额相加得到。
- 若干项特征之差: 假设你已经拥有每周销售额以及每月销售额两项特征,可以求一周前一月内的销售额。
- 若干项特征乘积: 假设你有商品价格和商品销量的特征,那么就可以得到销售额的特征。
- 若干项特征除商: 假设你有每个用户的销售额和购买的商品件数,那么就是得到该用户平均每件商品的销售额。
四、特征选择小结
特征选择是特征工程的第一步,它关系到我们机器学习算法的上限。因此原则是尽量不错过一个可能有用的特征,但是也不滥用太多的特征。
参考文献:
【1】特征工程之特征选择
【2】卡方检验原理及应用
特征选择:Filter/Wrapper/Embedded的更多相关文章
- 基于模型的特征选择详解 (Embedded & Wrapper)
目录 基于模型的特征选择详解 (Embedded & Wrapper) 1. 线性模型和正则化(Embedded方式) 2. 基于树模型的特征选择(Embedded方式) 3. 顶层特征选择算 ...
- 特征选择 - Filter、Wrapper、Embedded
Filter methods: information gain chi-square test fisher score correlation coefficient variance thres ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- Structure preserving unsupervised feature selection
Abstract • 使用自表示模型提取特征间的关系,结构保留约束来保持数据的局部流形结构: 1 Introduction • Contributions: (1)提出基于自表示模型的特征选择: ( ...
- 特征选择 (feature_selection)
目录 特征选择 (feature_selection) Filter 1. 移除低方差的特征 (Removing features with low variance) 2. 单变量特征选择 (Uni ...
- 谁动了我的特征?——sklearn特征转换行为全记录
目录 1 为什么要记录特征转换行为?2 有哪些特征转换的方式?3 特征转换的组合4 sklearn源码分析 4.1 一对一映射 4.2 一对多映射 4.3 多对多映射5 实践6 总结7 参考资料 1 ...
- [Feature] Feature selection
Ref: 1.13. Feature selection Ref: 1.13. 特征选择(Feature selection) 大纲列表 3.1 Filter 3.1.1 方差选择法 3.1.2 相关 ...
- sklearn特征工程
目录 一. 特征工程是什么? 2 ①特征使用方案 3 ②特征获取方案 4 ③特征处理 4 1. 特征清洗 4 2. 数据预处理 4 3. 特 ...
- SQL盲注修订建议
一般有多种减轻威胁的技巧: [1] 策略:库或框架 使用不允许此弱点出现的经过审核的库或框架,或提供更容易避免此弱点的构造. [2] 策略:参数化 如果可用,使用自动实施数据和代码之间的分离的结构化机 ...
随机推荐
- cm5.9.2安装spark启动报错解决办法
[root@db02 scala-2.11.5]# spark-shell Setting default log level to "WARN". To adjust loggi ...
- Exception 02 : java.lang.ClassNotFoundException: Could not load requested class : com.mysql.jdbc.Driver
异常名称 java.lang.ClassNotFoundException: Could not load requested class : com.mysql.jdbc.Driver 异常详细信息 ...
- Xcode报错Expected selector for Objective-C and Expected method body
昨天把键盘拿起来拍一下清清灰,然后就发现Xcode报错了,Xcode报错Expected selector for Objective-C and Expected method body,也不知道什 ...
- [skill] C与C++对于类型转换的验证
不多说了,代码说明一切. /home/tong/Src/copyleft/test [tong@T7] [:] > gcc .c /home/tong/Src/copyleft/test [to ...
- 文件处理----Properties文件处理
properties是一种属性文件,这种文件以key=value格式存储内容,代码中可以使用Properties类来读取这个文件,然后得到数据. 当配置文件用,由于难以表达层次,复杂点可以使用xml做 ...
- oracle 11g/12c 密码复杂度验证设置
############################################################################### ###### 11g ###### ## ...
- 20165225《Java程序设计》第三周学习总结
20165225<Java程序设计>第三周学习总结 1.视频与课本中的学习: 遇到的问题: 问题如下,无法编译. 最后经同学点出要放在同一个打包的文件夹里,于是就运行成功了,下面是4_15 ...
- java 线程(七)等待与唤醒
package cn.sasa.demo5; public class Resources { private String name; private boolean gender; //标记 pu ...
- java 线程 (一) Thread
package cn.sasa.demo1; public class Test { public static void main(String[] args) throws Interrupted ...
- linux根文件系统制作,busybox启动流程分析
分析 busybox-1.1.6 启动流程,并 制作一个小的根文件系统 源码百度云链接:https://pan.baidu.com/s/1tJhwctqj4VB4IpuKCA9m1g 提取码 :l10 ...