机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择。
但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。
包装法在初始特征集上训练评估器,并且通过coef_属性或通过feature_importances_属性获得每个特征的重要性。
然后,从当前的一组特征中修剪最不重要的特征。
在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
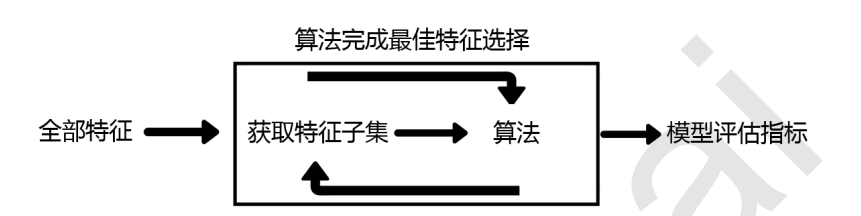
注意,在这个图中的“算法”,指的不是我们最终用来导入数据的分类或回归算法(即不是随机森林),而是专业的数据挖掘算法,即我们的目标函数。
这些数据挖掘算法的核心功能就是选取最佳特征子集。
最典型的目标函数是递归特征消除法(Recursive feature elimination, 简写为RFE)。它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。
它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。
然后,它根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。
包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。
除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更见缓慢,所以也不适用于太大型的数据。相比之下,包装法是最能保证模型效果的特征选择方法。
feature_selection.RFE
class sklearn.feature_selection.RFE (estimator, n_features_to_select=None, step=1, verbose=0)
参数estimator是需要填写的实例化后的评估器,n_features_to_select是想要选择的特征个数,step表示每次迭代中希望移除的特征个数。
除此之外,RFE类有两个很重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,以及.ranking_返回特征的按数次迭代中综合重要性的排名。
类feature_selection.RFECV会在交叉验证循环中执行RFE以找到最佳数量的特征,增加参数cv,其他用法都和RFE一模一样。
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =10,random_state=0)
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y) selector.support_.sum() selector.ranking_ X_wrapper = selector.transform(X) cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
我们也可以对包装法画学习曲线:
#======【TIME WARNING: 15 mins】======# score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()
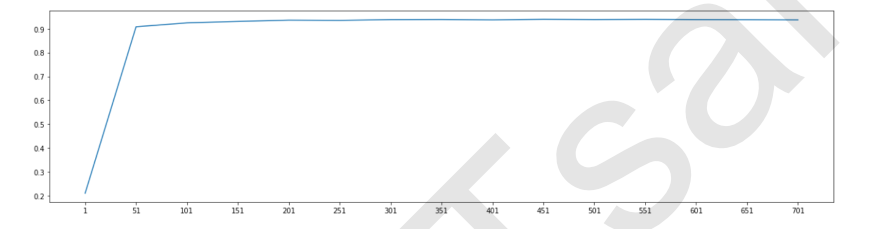
明显能够看出,在包装法下面,应用50个特征时,模型的表现就已经达到了90%以上,比嵌入法和过滤法都高效很多。我们可以放大图像,寻找模型变得非常稳定的点来画进一步的学习曲线(就像我们在嵌入法中做的那样)。
如果我们此时追求的是最大化降低模型的运行时间,我们甚至可以直接选择50作为特征的数目,这是一个在缩减了94%的特征的基础上,还能保证模型表现在90%以上的特征组合,不可谓不高效。
同时,我们提到过,在特征数目相同时,包装法能够在效果上匹敌嵌入法。
试试看如果我们也使用340作为特征数目,运行一下,可以感受一下包装法和嵌入法哪一个的速度更加快。
由于包装法效果和嵌入法相差不多,在更小的范围内使用学习曲线,我们也可以将包装法的效果调得很好,大家可以去试试看。
特征选择总结
至此,我们讲完了降维之外的所有特征选择的方法。这些方法的代码都不难,但是每种方法的原理都不同,并且都涉及到不同调整方法的超参数。经验来说,过滤法更快速,但更粗糙。包装法和嵌入法更精确,比较适合具体到算法去调整,但计算量比较大,运行时间长。
当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
使用逻辑回归时,优先使用嵌入法。
使用支持向量机时,优先使用包装法。
迷茫的时候,从过滤法走起,看具体数据具体分析。
其实特征选择只是特征工程中的第一步。真正的高手,往往使用特征创造或特征提取来寻找高级特征。在Kaggle之类的算法竞赛中,很多高分团队都是在高级特征上做文章,而这是比调参和特征选择更难的,提升算法表现的高深方法。特征工程非常深奥,虽然我们日常可能用到不多,但其实它非常美妙。若大家感兴趣,也可以自己去网上搜一搜,多读多看多试多想,技术逐渐会成为你的囊中之物。
机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法的更多相关文章
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
随机推荐
- @bzoj - 5104@ Fib数列
目录 @description@ @solution@ @accepted code@ @details@ @description@ Fib数列为1,1,2,3,5,8... 求在Mod10^9+9 ...
- ios判断当前设备是否是ipad
+ (BOOL)getIsIpad { NSString *deviceType = [UIDevice currentDevice].model; if([deviceType isEqualToS ...
- python+selenium识别图片验证码
import timeimport pytesseractfrom PIL import Image, ImageEnhancefrom selenium import webdriver url = ...
- 人声提取工具Spleeter安装教程(linux)
在安装之前,要确保运行Spleeter的计算机系统是64位,Spleeter不支持32位的系统.如何查看? 因为在linux环境下安装spleeter相对要简单很多,这篇教程先以Ubuntu20.04 ...
- MOJITO 发布一周,爬一波弹幕分析下
MOJITO 最近一直啥都没写,追个热点都赶不上热乎的,鄙视自己一下. 周董的新歌 「MOJITO」 发售(6 月 12 日的零点)至今大致过去了一周,翻开 B 站 MV 一看,播放量妥妥破千万,弹幕 ...
- 万级TPS亿级流水-中台账户系统架构设计
万级TPS亿级流水-中台账户系统架构设计 标签:高并发 万级TPS 亿级流水 账户系统 背景 业务模型 应用层设计 数据层设计 日切对账 背景 我们需要给所有前台业务提供统一的账户系统,用来支撑所有前 ...
- ZooKeeper开机启动的俩种方式
两种方式可以实现开机自启动 第一种:直接修改/etc/rc.d/rc.local文件 在/etc/rc.d/rc.local文件中需要输入两行, 其中export JAVA_HOME=/usr/jav ...
- JavaWeb网上图书商城完整项目--day02-7.提交注册表单功能之流程分析
1.点击注册之后将提交的信息传递到UserServlet的public String regist方法进行处理,然后将东西通过service进行处理 业务流程:
- Selenium+Python调Chrome浏览器时报Traceback (most recent call last): File "C:/Users/EDZ/Desktop/selenium_demo/demo001.py", line 12, in <module>
上次使用Selenium+Python还是好几个月前了 今天想再用一下,结果写个打开网站的小demo报错,报错如下: 检查了一下,查看报错日志,应该是chrome版本和driver版本不一致导致的. ...
- robot framework使用小结(二)
robot framework关键字驱动采用分层,结合Template做成数据驱动 我个人觉得不管是关键字驱动还是数据驱动,都是基于模块(或者是函数)的概念 新建测试案例baidu02,添加Libra ...