高可用hadoop的hdfs启动的时候namenode启动不了
启动的时候,一直要求输入namenode密码:
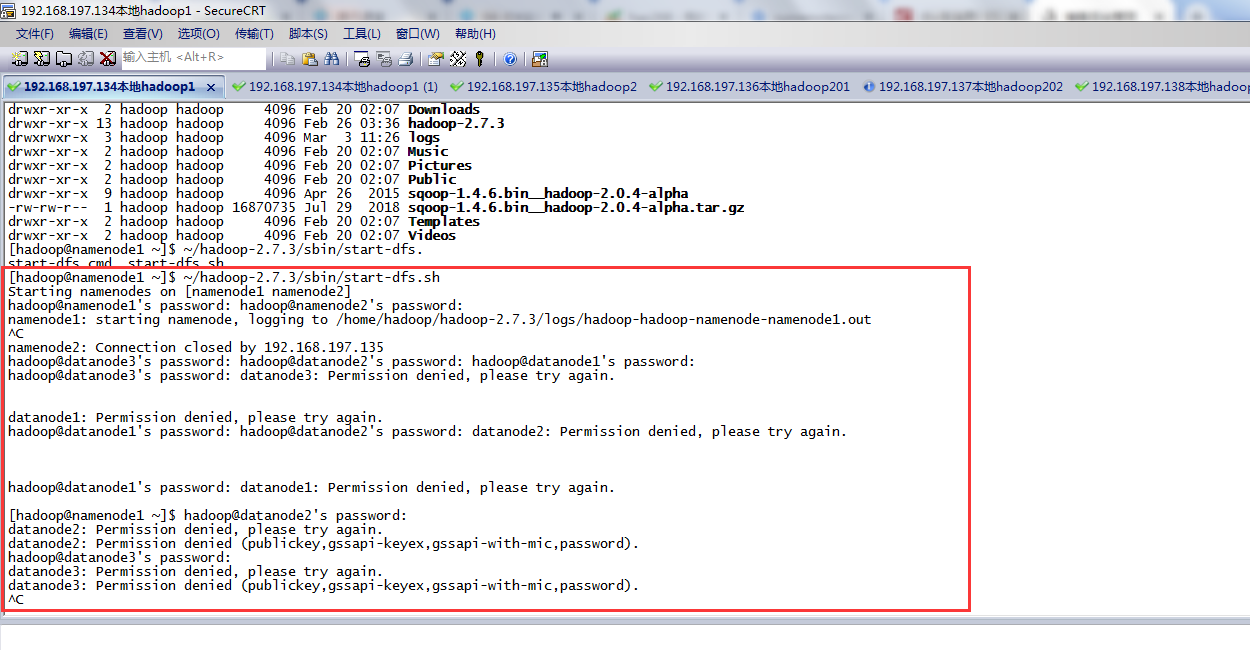
查看namenode的日志如下:
2019-03-28 18:38:08,961 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: datanode1/192.168.197.136:8485. Already tried 47 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=100, sleepTime=10000 MILLISECONDS)
2019-03-28 18:38:09,208 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: namenode2/192.168.197.135:8030. Already tried 29 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=100, sleepTime=10000 MILLISECONDS)
2019-03-28 18:38:18,958 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: datanode2/192.168.197.137:8485. Already tried 48 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=100, sleepTime=10000 MILLISECONDS)
2019-03-28 18:38:18,961 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: datanode3/192.168.197.138:8485. Already tried 48 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=100, sleepTime=10000 MILLISECONDS)
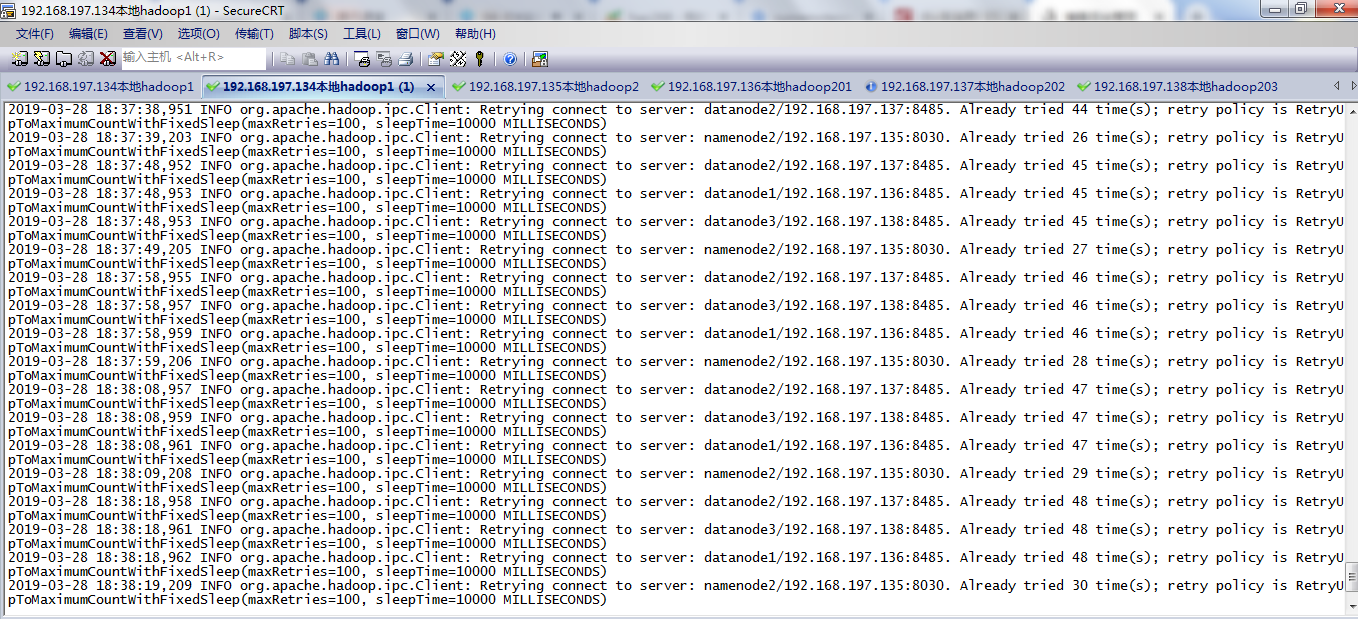
怀疑是其他服务器,namenode2/192.168.197.135,datanode1/192.168.197.136,datanode2/192.168.197.137,datanode3/192.168.197.138
上面没有authorized_keys文件中namenode1/192.1682.197.134的公钥不对。
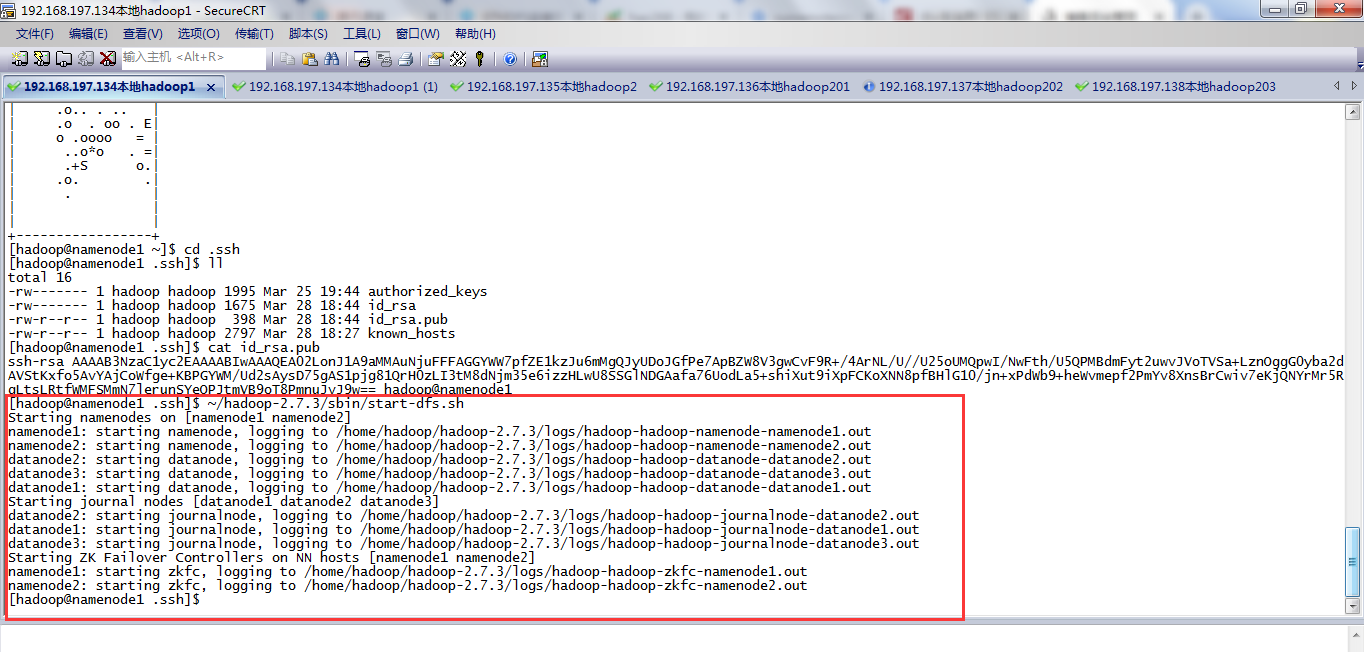
在namenode1/192.1682.197.134中重新执行ssh-keygen -t rsa,生成公钥和私钥,发现私钥真的和其他服务器上存储的namenode1/192.1682.197.134的公钥不匹配。
更改其他服务器上authorized_keys中namenode1/192.1682.197.134的公钥后,重启hdfs正常启动。
高可用hadoop的hdfs启动的时候namenode启动不了的更多相关文章
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- 高可用Hadoop平台-Oozie工作流之Hadoop调度
1.概述 在<高可用Hadoop平台-Oozie工作流>一篇中,给大家分享了如何去单一的集成Oozie这样一个插件.今天为大家介绍如何去使用Oozie创建相关工作流运行与Hadoop上,已 ...
- 高可用Hadoop平台-Hue In Hadoop
1.概述 前面一篇博客<高可用Hadoop平台-Ganglia安装部署>,为大家介绍了Ganglia在Hadoop中的集成,今天为大家介绍另一款工具——Hue,该工具功能比较丰富,下面是今 ...
- 高可用Hadoop平台-集成Hive HAProxy
1.概述 这篇博客是接着<高可用Hadoop平台>系列讲,本篇博客是为后面用 Hive 来做数据统计做准备的,介绍如何在 Hadoop HA 平台下集成高可用的 Hive 工具,下面我打算 ...
- 高可用Hadoop平台-启航
1.概述 在上篇博客中,我们搭建了<配置高可用Hadoop平台>,接下来我们就可以驾着Hadoop这艘巨轮在大数据的海洋中遨游了.工欲善其事,必先利其器.是的,没错:我们开发需要有开发工具 ...
- 高可用Hadoop平台-实战尾声篇
1.概述 今天这篇博客就是<高可用Hadoop平台>的尾声篇了,从搭建安装到入门运行 Hadoop 版的 HelloWorld(WordCount 可以称的上是 Hadoop 版的 Hel ...
- 高可用Hadoop平台-实战
1.概述 今天继续<高可用的Hadoop平台>系列,今天开始进行小规模的实战下,前面的准备工作完成后,基本用于统计数据的平台都拥有了,关于导出统计结果的文章留到后面赘述.今天要和大家分享的 ...
- 高可用Hadoop平台-探索
1.概述 上篇<高可用Hadoop平台-启航>博客已经让我们初步了解了Hadoop平台:接下来,我们对Hadoop做进一步的探索,一步一步的揭开Hadoop的神秘面纱.下面,我们开始赘述今 ...
随机推荐
- LeetCode - Boundary of Binary Tree
Given a binary tree, return the values of its boundary in anti-clockwise direction starting from roo ...
- CSVN(SVN)命令入门及使用过程中遇到的错误问题汇总
首先进入web管理界面新建一个版本库 新建一个文件text svn add text #如果提示错误,在后面增加–force svn ci -m 'add text' #如果提示错误,将csvn下的目 ...
- curl常用传参方式
1.传header参数curl --header 'Token:40d7c342c110414888cc2a0e1284c636' "127.0.0.1/api/user/baseInfo& ...
- 日志插件 log4net 的配置和使用
文本格式说明 可以记载的日志类别包括:FATAL(致命错误).ERROR(一般错误).WARN(警告).INFO(一般信息).DEBUG(调试信息). 文本参数说明 %m(message):输出的日志 ...
- 使用cmake编译luabind
编写了一下cmakelists.txt文件 根目录 cmake_minimum_required(VERSION 2.8)project (Test) add_definitions( "/ ...
- Package has no installation candidate解决方法
今天在安装软件的时候出现了Package has no installation candidate的问题,如:# apt-get install <packagename>Reading ...
- Python画图代码
X1D=np.linspace(-4, 4, 9).reshape(-1,1) X2D=np.c_[X1D, X1D**2] y = np.array([0, 0, 1, 1, 1, 1, 1, 0, ...
- hadoop不同版本有哪些
一.Hadoop是什么? 首次听到hadoop这次单词,相信很多人跟我当时是一样,不免心中画上一个大大的问号——这是什么东西?Hadoop是什么?百度百科的解释是:Hadoop是一个由Apache基金 ...
- OpenCV相机标定坐标系详解
在OpenCV中,可以使用calibrateCamera函数,通过多个视角的2D/3D对应,求解出该相机的内参数和每一个视角的外参数. 使用C++接口时的输入参数如下: objectPoints - ...
- Vivado HLS初识---阅读《vivado design suite tutorial-high-level synthesis》
Vivado HLS初识---阅读<vivado design suite tutorial-high-level synthesis> 1.启动 2.创建工程 3.添加源文件 4.添加测 ...