Strom在本地运行调试出现的错误
1.错误日志
31385 [main] WARN backtype.storm.daemon.nimbus - Topology submission exception. (topology name='webloganalyse2') #<InvalidTopologyException InvalidTopologyException(msg:Component: [countIpBolt] subscribes from non-existent stream: [ipCountStream] of component [webLogParserBolt])>
31385 [main] ERROR org.apache.storm.zookeeper.server.NIOServerCnxnFactory - Thread Thread[main,5,main] died
backtype.storm.generated.InvalidTopologyException: null
at backtype.storm.daemon.common$validate_structure_BANG_.invoke(common.clj:172) ~[storm-core-0.9.6.jar:0.9.6]
at backtype.storm.daemon.common$system_topology_BANG_.invoke(common.clj:307) ~[storm-core-0.9.6.jar:0.9.6]
at backtype.storm.daemon.nimbus$fn__4261$exec_fn__1104__auto__$reify__4274.submitTopologyWithOpts(nimbus.clj:948) ~[storm-core-0.9.6.jar:0.9.6]
at backtype.storm.daemon.nimbus$fn__4261$exec_fn__1104__auto__$reify__4274.submitTopology(nimbus.clj:966) ~[storm-core-0.9.6.jar:0.9.6]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_144]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_144]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_144]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_144]
at clojure.lang.Reflector.invokeMatchingMethod(Reflector.java:93) ~[clojure-1.5.1.jar:na]
at clojure.lang.Reflector.invokeInstanceMethod(Reflector.java:28) ~[clojure-1.5.1.jar:na]
at backtype.storm.testing$submit_local_topology.invoke(testing.clj:264) ~[storm-core-0.9.6.jar:0.9.6]
at backtype.storm.LocalCluster$_submitTopology.invoke(LocalCluster.clj:43) ~[storm-core-0.9.6.jar:0.9.6]
at backtype.storm.LocalCluster.submitTopology(Unknown Source) ~[storm-core-0.9.6.jar:0.9.6]
at com.jun.it2.WebLogStatictis.main(WebLogStatictis.java:31) ~[classes/:na]
2.出现这个问题的原因
下游Bolt未定义数据流错误
在下游Bolt接收数据时,往往会忽略具体的接收数据流名称,例如
builder.setBolt(devInter, new InterBolt().shuffleGrouping(dev);
3.分析本日志
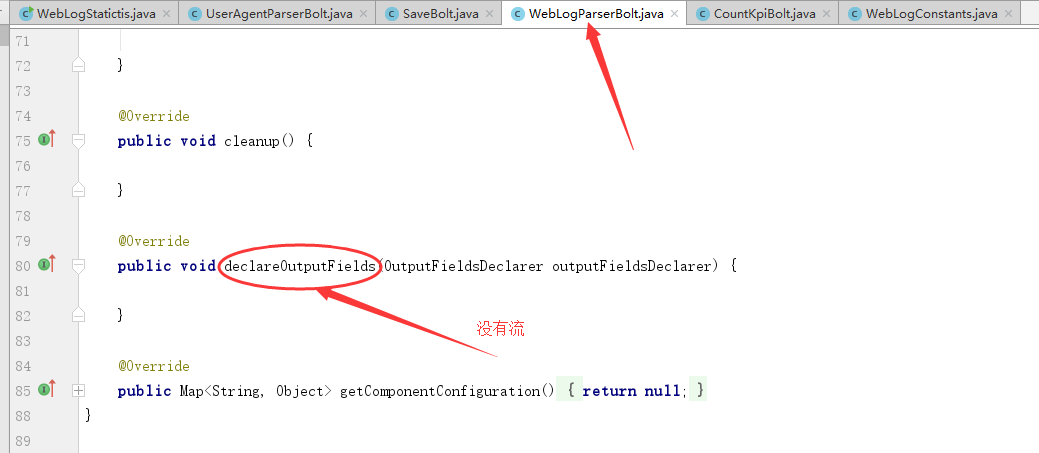
可以看到在webLogParserBolt.java中。
同时说明,在countIpBolt中不存在ipCountStream流名称。
4.看自己的程序、
5.修改后的程序
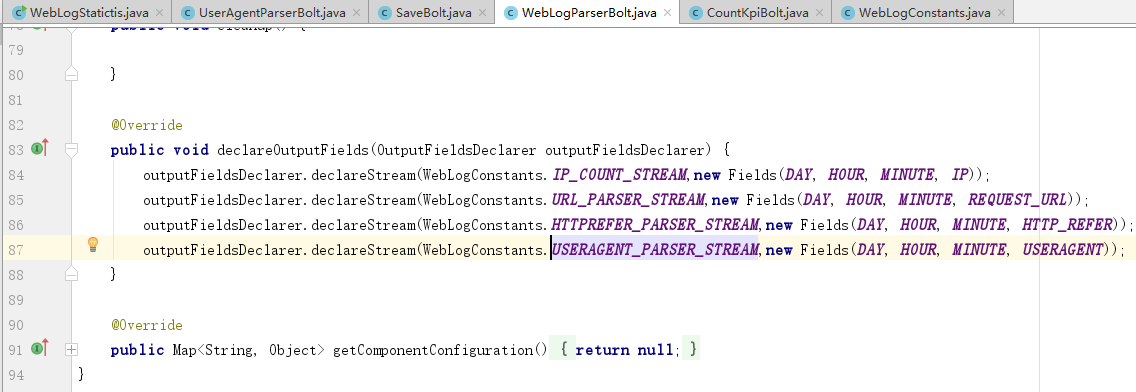
6.效果
这个时候,就不会再报错了。
Strom在本地运行调试出现的错误的更多相关文章
- Windows本地运行调试Spark或Hadoop程序失败:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
报错内容 ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOExce ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 开发函数计算的正确姿势 —— 使用 Fun Local 本地运行与调试
前言 首先介绍下在本文出现的几个比较重要的概念: 函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传.函数计算 ...
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- Jfinal本地eclipse+tomcat运行项目时候遇到错误Exception starting filter
今天想在本地eclipse上启动tomcat让项目在本地运行,但是老是报错类找不到异常. 也可能报其它错误,大概都是classNotFoundException. 九月 19, 2018 5:42:2 ...
- spark window本地运行wordcount错误
在运行本地运行spark或者hadoop代码时可能会遇到一下三种问题 1.Exception in thread "main" java.lang.UnsatisfiedLin ...
- Android 开发之深入理解安卓调试桥各种错误解决办法
摘要: Android开发调试项目使用到安卓调试桥工具,Android Debug Bridge(ADB)位于sdk路径platform-tools文件夹,使用Android Studio或Eclip ...
- gdb调试PHP扩展错误
有时候,使用PHP的第三方扩展之后,可能会发生一些错误,这个时候,可能就需要更底层的方式追踪调试程序发生错误的地方和原因,熟悉linux下C编程的肯定不陌生gdb 首先,使用ulimit -c命令,查 ...
- IDEA开发spark本地运行
1.建立spakTesk项目,建立scala对象Test 2.Tesk对象的代码如下 package sparkTest /** * Created by jiahong on 15-8-2. */ ...
随机推荐
- bzoj1477: 青蛙的约会(exgcd)
昨天打code+的时候发现自己已经不大会exgcd了..赶紧复习一下QAQ 求$ax+by=gcd(a,b)$的解 初始条件 $gcd(a, 0)=a$ $x=1,y=0$ 推导过程 $gcd(a,b ...
- Java添加过期注解
加上 @Deprecated 后方法名称显示: 中划线(删除线)意为:发生这些变化并不会影响编译,只是提醒一下程序员,这个方法以后是要被删除的,最好别用.就是如果一个类从另外一个类继承,并且overr ...
- Python中str()和repr()函数的区别
在 Python 中要将某一类型的变量或者常量转换为字符串对象通常有两种方法,即 str() 或者 repr() . 区别与使用函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供 ...
- [转]xargs命令详解,xargs与管道的区别
为什么要用xargs,问题的来源 在工作中经常会接触到xargs命令,特别是在别人写的脚本里面也经常会遇到,但是却很容易与管道搞混淆,本篇会详细讲解到底什么是xargs命令,为什么要用xargs命令以 ...
- 从前端和后端两个角度分析jsonp跨域访问(完整实例)
一.什么是跨域访问 举个栗子:在A网站中,我们希望使用Ajax来获得B网站中的特定内容.如果A网站与B网站不在同一个域中,那么就出现了跨域访问问题.你可以理解为两个域名之间不能跨过域名来发送请求或者请 ...
- eMMC基础技术6:eMMC data读写
1. 前言 data可以经data线从host发往device,也可以从device发往host 数据线以是1线(DATA0),4线(DATA0~DATA3),8线(DATA0~DATA7) 对每条数 ...
- mysql系列十、mysql索引结构的实现B+树/B-树原理
一.MySQL索引原理 1.索引背景 生活中随处可见索引的例子,如火车站的车次表.图书的目录等.它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的 ...
- Centos6.5使用yum安装svn
1.测试环境 centos5.5 2.安装svn yum -y install subversion //测试SVN是否安装成功,执行:svnserve --version 3.配置 mkdir /w ...
- Python-百度经纬度转高德经纬度
import math def bdToGaoDe(lon,lat): """ 百度坐标转高德坐标 :param lon: :param lat: :return: &q ...
- OCM_第八天课程:Section4 —》数据管理
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...