tf一些函数
1.
tf.reduce_mean(a) : 求平均值
2.
tf.truncated_normal([3,2],stddev=0.1) : 从正态分布中输出随机值,标准差为0,1,构造矩阵为3*2的
3.
tf.argmax(vector, 1):返回的是vector中的最大值的索引号,如果vector是一个向量,那就返回一个值,如果是一个矩阵,那就返回一个向量,这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号。
A = [[1,3,4,5,6]]
B = [[1,3,4], [2,4,1]]
with tf.Session() as sess:
print(sess.run(tf.argmax(A, 1)))
print(sess.run(tf.argmax(B, 1)))
输出:
[4]
[2 1]
4.
tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
A = [[1,3,4,5,6]]
B = [[1,3,4,3,2]]
with tf.Session() as sess:
print(sess.run(tf.equal(A, B)))
输出:
[[ True True True False False]]
5.
tf.cast()
强制转换类型
使用案例:
import tensorflow as tf
x = tf.constant([1.8, 2.2], dtype=tf.float32)
r = tf.cast(x, tf.int32)
sess = tf.Session()
print(sess.run(r)) # [1, 2], dtype=tf.int32
6.
mnist.train.next_batch(100):拿出100个样本来
7.
Dropout就是在不同的训练过程中随机扔掉一部分神经元。
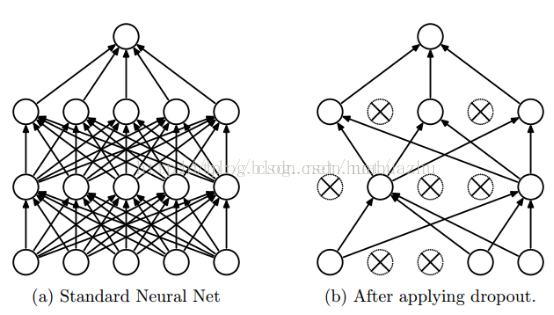
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
上面方法中常用的是前两个参数:
第一个参数x:指输入
第二个参数keep_prob: 设置神经元被选中的概率
8.
transpose函数
import tensorflow as tf
#x = tf.constant([[1, 2 ,3],[4, 5, 6]])
x = [[[1,2,3,4],[5,6,7,8],[9,10,11,12]],[[21,22,23,24],[25,26,27,28],[29,30,31,32]]]
#a=tf.constant(x)
a=tf.transpose(x, [0, 1, 2]) # 正常情况下,0,1,2
b=tf.transpose(x, [0, 2, 1]) # 将1和2的位置换了一下,原来是2*(3*4),后面的2个3和4换了一下以后,现在是2*(4*3)
c=tf.transpose(x, [1, 0, 2]) # 所有矩阵的第一行拼成一个矩阵,第二行。。。。。
with tf.Session() as sess:
print ('---------------')
print (sess.run(a))
print ('---------------')
print (sess.run(b))
print ('---------------')
print (sess.run(c))
print ('---------------')
输出:
---------------
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[21 22 23 24]
[25 26 27 28]
[29 30 31 32]]]
---------------
[[[ 1 5 9]
[ 2 6 10]
[ 3 7 11]
[ 4 8 12]]
[[21 25 29]
[22 26 30]
[23 27 31]
[24 28 32]]]
---------------
[[[ 1 2 3 4]
[21 22 23 24]]
[[ 5 6 7 8]
[25 26 27 28]]
[[ 9 10 11 12]
[29 30 31 32]]]
---------------------
9.
tf.split
a=[[1,2,3,4,5,6],[7,8,9,10,11,12]]
s=tf.split(a,2,0) # 2是切割的数量,0是维度,对a的第0个维度切割成2份(矩阵中,第0个维度即行,第1个维度即列,如果是1维数组,只有一个维度0),这里是对行进行切割,切割完后就是1行1行的了,然后他说是2份,那就独立成份
print(tf.Session().run(s))
a=[1,2,3,4,5,6]
s=tf.split(a,3,0) # 因为是1维数组,默认是0,因为要切成3份,所以结果是[array([1, 2]), array([3, 4]), array([5, 6])]
print(tf.Session().run(s))
10.
tf.nn.embedding_lookup
a = [[0.1, 0.2, 0.3], [1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3]]
a = np.asarray(a)
print(a)
idx1 = tf.Variable([0, 2, 3, 1], tf.int32)
idx2 = tf.Variable([[0, 2, 3, 1], [4, 0, 2, 2]], tf.int32)
out1 = tf.nn.embedding_lookup(a, idx1) # 取a的第0个序号,第2个序号,第3个序号,第1个序号对应的行
out2 = tf.nn.embedding_lookup(a, idx2) # 总共取了2个矩阵,每行取法一样
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(out1))
print(out1)
print('==================')
print(sess.run(out2))
print(out2)
11.
tf.nn.bias_add
a=tf.constant([[1,1],[2,2],[3,3]],dtype=tf.float32)
b=tf.constant([1,-1],dtype=tf.float32)
with tf.Session() as sess:
print(sess.run(a))
print(sess.run(b))
print('bias_add:')
print(sess.run(tf.nn.bias_add(a, b))) # 将后一项加到前一项
12.
tf.one_hot
classes = 4
labels = tf.constant([0,0,2])
output = tf.one_hot(labels,classes)
# 后面表示输出的尺寸,前面的labels,如果是0,则表示1 0 0 0 0 ...,
# 如果是1,则表示:0 1 0 0 0 0....(即one-hot编码)
# 这个例子中,输出的长为4,
sess = tf.Session()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(output)
print(output)
out:
[[1. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 0. 1. 0.]]
13.
>>>a = np.array([[1,2,3],[4,5,6]])
>>>np.reshape(a,(3,-1)) # -1表示不知道该填什么值的时候让它自己计算出来
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.reshape(a,(1,-1))
array([[1, 2, 3, 4, 5, 6]])
>>> np.reshape(a,(6,-1))
array([[1],
[2],
[3],
[4],
[5],
[6]])
>>> np.reshape(a,(-1,1))
array([[1],
[2],
[3],
[4],
[5],
[6]])
14.
tf.expand_dims(input, axis=None, name=None, dim=None)
在第axis位置增加一个维度,比如:
# 't' is a tensor of shape [2]
shape(expand_dims(t, 0)) ==> [1, 2]
shape(expand_dims(t, 1)) ==> [2, 1]
shape(expand_dims(t, -1)) ==> [2, 1]
# 't2' is a tensor of shape [2, 3, 5]
shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5]
shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5]
shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1]15.
tf.concat
# a的第0个维度有2个元素:[1,2,3],[4,5,6],a的第1个维度有3个元素
a=[[[1,2,3],[4,5,6]]] # 维度:123
b=[[[7,8,9],[10,11,12]]] # 维度:123
# a的维度是1*2*3,b的维度是1*2*3,在第0个维度拼接的结果是:(1+1)*2*3 = 2*2*3
print(tf.concat([a,b],axis=0).shape)
print(tf.concat([a,b],axis=1).shape)
print(tf.concat([a,b],axis=2).shape)
print(tf.concat([a,b],axis=-1).shape)
16.
tf.device()
在tensorflow中,我们可以使用 tf.device() 指定模型运行的具体设备,可以指定运行在GPU还是CUP上,以及哪块GPU上。
例如:使用 tf.device('/gpu:1') 指定Session在第二块GPU上运行:
tf一些函数的更多相关文章
- tensorflow 笔记14:tf.expand_dims和tf.squeeze函数
tf.expand_dims和tf.squeeze函数 一.tf.expand_dims() Function tf.expand_dims(input, axis=None, name=None, ...
- TensorFlow随机值:tf.random_normal函数
tf.random_normal 函数 random_normal( shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=No ...
- tf.transpose函数的用法讲解
tf.transpose函数中文意思是转置,对于低维度的转置问题,很简单,不想讨论,直接转置就好(大家看下面文档,一看就懂). tf.transpose(a, perm=None, name='tra ...
- tensorflow中 tf.reduce_mean函数
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值. reduce_mean(input_ ...
- tf.transpose函数解析
tf.transpose函数解析 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.transpose(a, perm = None, name = 'transpose') 解释 将a进 ...
- tf.slice函数解析
tf.slice函数解析 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.slice(input_, begin, size, name = None) 解释 : 这个函数的作用是从输入 ...
- tf.random_normal()函数
tf.random_normal()函数用于从服从指定正太分布的数值中取出指定个数的值. tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf. ...
- Tensorflow函数——tf.placeholder()函数
tf.placeholder()函数 Tensorflow中的palceholder,中文翻译为占位符,什么意思呢? 在Tensoflow2.0以前,还是静态图的设计思想,整个设计理念是计算流图,在编 ...
- tf.Session()函数的参数应用(tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/dcrmg/article/details ...
- 【tensorflow基础】tensorflow中 tf.reduce_mean函数
参考 1. tensorflow中 tf.reduce_mean函数: 完
随机推荐
- linux git 报错提示 fatal: 'origin' does not appear to be a git repository 解决办法
输入: git pull origin master git报错提示 fatal: 'origin' does not appear to be a git repository fatal: Cou ...
- P1501 [国家集训队]Tree II(LCT)
P1501 [国家集训队]Tree II 看着维护吧2333333 操作和维护区间加.乘线段树挺像的 进行修改操作时不要忘记吧每个点的点权$v[i]$也处理掉 还有就是$51061^2=2607225 ...
- shell脚本作为cgi程序--以web版man为例
man.cgi源码 #! /bin/sh eval `sh proccgi.sh $*` echo "Content-type: text/html" echo echo echo ...
- easyui以及js前端开发常见问题、用法整理(最重要的样式和图标自定义)
自定义图标 iconCls 所有属性值枚举: icon-add icon-print icon-mini-add icon-cvs icon-play icon-refresh icon-edit i ...
- 基础_模型迁移_CBIR_augmentation
在之前我们做过这样的研究:5图分类CBIR问题 各不相同的 5类的图形,每类100张 import numpy as npfrom keras.datasets import mnistimport ...
- nginx: [error] invalid PID number "" in "/var/run/nginx/nginx.pid"
一.出现这个的情况 解决方法一: 1.添加正在运行pid号到/var/run/nginx/nginx.pid就可以解决问题了(这个情况是在重启的情况下发现的) 2.如果是重启机器之后,系统有时会删掉/ ...
- Overture 5入门之如何设置延音线
延音线作为五线谱标记符合之一,是大家使用Overture时需要常用的一个基本标记符号.延音线是一条向上或向下弯曲的弧线,它的作用是将两个或两个以上的具有相同高音的音符来进行相连. 延音线作为再编曲演唱 ...
- 【Python019--函数与过程】
一.函数与过程 1.Python只有函数没有过程 >>> def hello(): print('Hello fishC!')>>> temp = hell ...
- 16 级高代 II 思考题九的七种解法
16 级高代 II 思考题九 设 $V$ 是数域 $\mathbb{K}$ 上的 $n$ 维线性空间, $\varphi$ 是 $V$ 上的线性变换, $f(\lambda),m(\lambda)$ ...
- topcoder srm 455 div1
problem1 link 令$f[x1][y1][x2][y2]$表示矩形(x1,y1)(x2,y2)中能选出的最大值.dp即可. problem2 link 这个题应该有更好的递推公式. 我的做法 ...