Zookeeper 三台主机 Ha集群的搭建
前期准备
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
######注意######如果你们公司是租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
集群规划:
server01
namenode(active)
zkfc
nodemanager
datanode
zookeeper
journal node
server02
namenode(standby)
resourcemanager(active)
zkfc
nodemanager
datanode
zookeeper
journal node
server03
resourcemanager(standby)
datanode
nodemanager
zookeeper
journal node
说明:
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。
Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。
在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。
通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,
会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,
hadoop-2.7.2解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
安装步骤:
1.安装配置zooekeeper集群(在hadoop-001上)
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/bigdatasoftware/
1.2修改配置
cd /home/hadoop/bigdatasoftware/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/home/hadoop/bigdatasoftware/zookeeper-3.4.5/zkdata
在最后添加:
server.1=hadoop-001:2888:3888
server.2=hadoop-002:2888:3888
server.3=hadoop-003:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /home/hadoop/bigdatasoftware/zookeeper-3.4.5/zkdata
echo 1 > /home/hadoop/bigdatasoftware/zookeeper-3.4.5/zkdata/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop-002、hadoop-001根目录下创建一个hadoop目录:mkdir /bigdatasoftware)
scp -r /home/hadoop/bigdatasoftware/zookeeper-3.4.5/ hadoop-002:/home/hadoop/bigdatasoftware/
scp -r /home/hadoop/bigdatasoftware/zookeeper-3.4.5/ hadoop-003:/home/hadoop/bigdatasoftware/
注意:修改hadoop-002、hadoop-003对应/hadoop/zookeeper-3.4.5/zkdata/myid内容
hadoop-002:
echo 2 > /home/hadoop/bigdatasoftware/zookeeper-3.4.5/zkdata/myid
hadoop-003:
echo 3 > /home/hadoop/bigdatasoftware/zookeeper-3.4.5/zkdata/myid
2.安装配置hadoop集群(在hadoop-001上操作)
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/bigdatasoftware/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/home/hadoop/bigdatasoftware/jdk1.8.0_161
export HADOOP_HOME=/home/hadoop/bigdatasoftware/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/bigdatasoftware/hadoop-2.7.2/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/bigdatasoftware/jdk1.8.0_161
###############################################################################
2.2.2
修改core-site.xml
<configuration>
<!--
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-001:2181,hadoop-002:2181,hadoop-003:2181</value>
</property> -->
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bi/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-001:2181,hadoop-002:2181,hadoop-003:2181</value>
</property>
</configuration>
###############################################################################
2.2.3修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- cmeservice为bi,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>bi</value>
</property>
<!-- bi下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.bi</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn1</name>
<value>hadoop-001:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn1</name>
<value>hadoop-001:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn2</name>
<value>hadoop-002:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn2</name>
<value>hadoop-002:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-001:8485;hadoop-002:8485;hadoop-003:8485/bi</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.bi</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
###############################################################################
2.2.4修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
###############################################################################
2.2.5修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-002</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-003</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-001:2181,hadoop-002:2181,hadoop-003:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.2.6修改slaves(slaves是指定子节点的位置,因为要在hadoop-001上启动HDFS、在hadoop-002启动yarn,所以hadoop-001上的slaves文件指定的是datanode的位置,hadoop-002上的slaves文件指定的是nodemanager的位置)
2.2.7配置免密码登陆
#首先要配置hadoop-001到hadoop-003、hadoop-003的免密码登陆
#在hadoop-001上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id hadoop-001
ssh-coyp-id hadoop-002
ssh-coyp-id hadoop-003
#配置hadoop-002到hadoop-033的免密码登陆
#在hadoop-002上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-coyp-id hadoop-003
#注意:两个namenode之间要配置ssh免密码登陆,
在 hadoop-002上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i hadoop-001
2.4将配置好的hadoop拷贝到其他节点
scp -r ~/bigdatasoftware/hadoop-2.7.2/etc hadoop@hadoop-002:/home/hadoop/bigdatasoftware/hadoop-2.7.2
scp -r ~/bigdatasoftware/hadoop-2.7.2/etc hadoop@hadoop-003:/home/hadoop/bigdatasoftware/hadoop-2.7.2
###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
2.5
启动zookeeper集群(分别在hadoop-001、hadoop-002、hadoop-03上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.6
手动启动journalnode(分别在在hadoop-001、hadoop-002、hadoop-03上执行)
hadoop-daemon.sh start journalnode
#运行jps命令检验,hhadoop-001、hadoop-002、hadoop-03上多了JournalNode进程
2.7
格式化namenode
#在hadoop00上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/home/hadoop//tmp,然后将/home/hadoop//tmp拷贝到hadoop-002的/home/hadoop/下。
scp -r ~/tmp/ hadoop@hadoop-002:/home/hadoop/
##也可以这样,建议hdfs namenode -bootstrapStandby
2.8
格式化ZKFC(在hadoop-001上执行即可)
hdfs zkfc -formatZK
2.9启动HDFS(在hadoop-001上执行)
sbin/start-dfs.sh
2.10
启动YARN(#####注意#####:是在hadoop-002上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
到此,hadoop-2.7.2配置完毕,可以统计浏览器访问:
http://hadoop-001:50070
NameNode 'hadoop-001:9000' (active)
http://hadoop-002:50070
NameNode 'hadoop-002:9000' (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:hadoop-002:50070
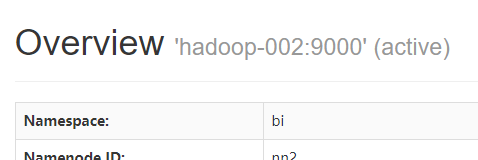
NameNode 'hadoop-002:9000' (active)
这个时候hadoop-002上的NameNode变成了active
在执行命令:
hadoop fs -ls /
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:
hadoop-001:50070
NameNode 'hadoop-001:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
OK,大功告成!!!
测试集群工作状态的一些指令 :
bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息
bin/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
Zookeeper 三台主机 Ha集群的搭建的更多相关文章
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- Hadoop HA集群的搭建
HA 集群搭建的难度主要在于配置文件的编写, 心细,心细,心细! ha模式下,secondary namenode节点不存在... 集群部署节点角色的规划(7节点)------------------ ...
- ZooKeeper 系列(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 1.2 解压 1.3 配置环境变量 1.4 修改配置 1.5 启动 1. ...
- ZooKeeper —— 单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本Zookeeper,这里我下载的版本3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # w ...
- ZooKeeper学习之路(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本Zookeeper,这里我下载的版本3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # w ...
- ZooKeeper系列(二)—— Zookeeper 单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # ...
- mesos+marathon+zookeeper的docker管理集群亲手搭建实例(环境Centos6.8)
资源:3台centos6.8虚拟机 4cpu 8G内存 ip 10.19.54.111-113 1台centos6.8虚拟机2cpu 8G ip 10.19.53.55 1.System Requir ...
- HBase HA 集群环境搭建
安装准备 确定已安装并启动 HDFS(HA)集群 角色分配如下: node-01: namenode datanode regionserver hmaster zookeeper node-02: ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
随机推荐
- delete CDU
function DeletePDU(){ global $person; $this->MakeSafe(); // Do not attempt anything else if the l ...
- maven项目中的pom.xml
需要配置的内容 1.配置头(自动生成) 2.maven项目的坐标(自动生成) <modelVersion>4.0.0</modelVersion> <groupId> ...
- HDU1166-敌兵布阵 (线段树)
题目传送门:http://acm.hdu.edu.cn/showproblem.php?pid=1166 敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) ...
- JS/JavaScript简介及基本常识
JavaScript (JS)以客户端事件为驱动的弱类型脚本语言 JS脚本一般写在<head>内部 流:文本流.html流 回避关键字的基本策略:单词合并(v_function) null ...
- 2.4 CSS定位
前言 大部分人在使用selenium定位元素时,用的是xpath定位,因为xpath基本能解决定位的需求.css定位往往被忽略掉了,其实css定位也有它的价值,css定位更快,语法更简洁.这一篇css ...
- 【转】【计算机视觉】opencv靶标相机姿态解算2 根据四个特征点估计相机姿态 及 实时位姿估计与三维重建相机姿态
https://blog.csdn.net/kyjl888/article/details/71305149
- textarea去掉右下三角号
/*去掉textarea右下角三角符号*/ resize : none; 修改样式直接覆盖就行,会把默认样式覆盖掉.如border,width,height,border-radius
- 洛谷P4147 玉蟾宫(动规:最大子矩形问题/悬线法)
题目链接:传送门 题目大意: 求由F构成的最大子矩阵的面积.输出面积的三倍. 1 ≤ N,M ≤ 1000. 思路: 悬线法模板题. #include <bits/stdc++.h> us ...
- 再回首 基本数据类型和 if语句
一 变量:(使用变量是不能加引号,要不就变成字符串了) 变量的命名规则: 1.数字,字母,下划线组成. 2.变量不能是数字开头 3.区分大小写 4.不要使用中文或者拼音 5.要有相应的意义 6.不能使 ...
- 第8次Scrum会议(10/20)【欢迎来怼】
一.小组信息 队名:欢迎来怼 小组成员 队长:田继平 成员:李圆圆,葛美义,王伟东,姜珊,邵朔,冉华 小组照片 二.开会信息 时间:2017/10/20 17:20~17:45,总计25min. 地点 ...