大模型 Token 究竟是啥:图解大模型Token
前几天,一个朋友问我:“大模型中的 Token 究竟是什么?”
这确实是一个很有代表性的问题。许多人听说过 Token 这个概念,但未必真正理解它的作用和意义。思考之后,我决定写篇文章,详细解释这个话题。

我说:像 DeepSeek 和 ChatGPT 这样的超大语言模型,都有一个“刀法精湛”的小弟——分词器(Tokenizer)。

当大模型接收到一段文字。
会让分词器把它切成很多个小块。
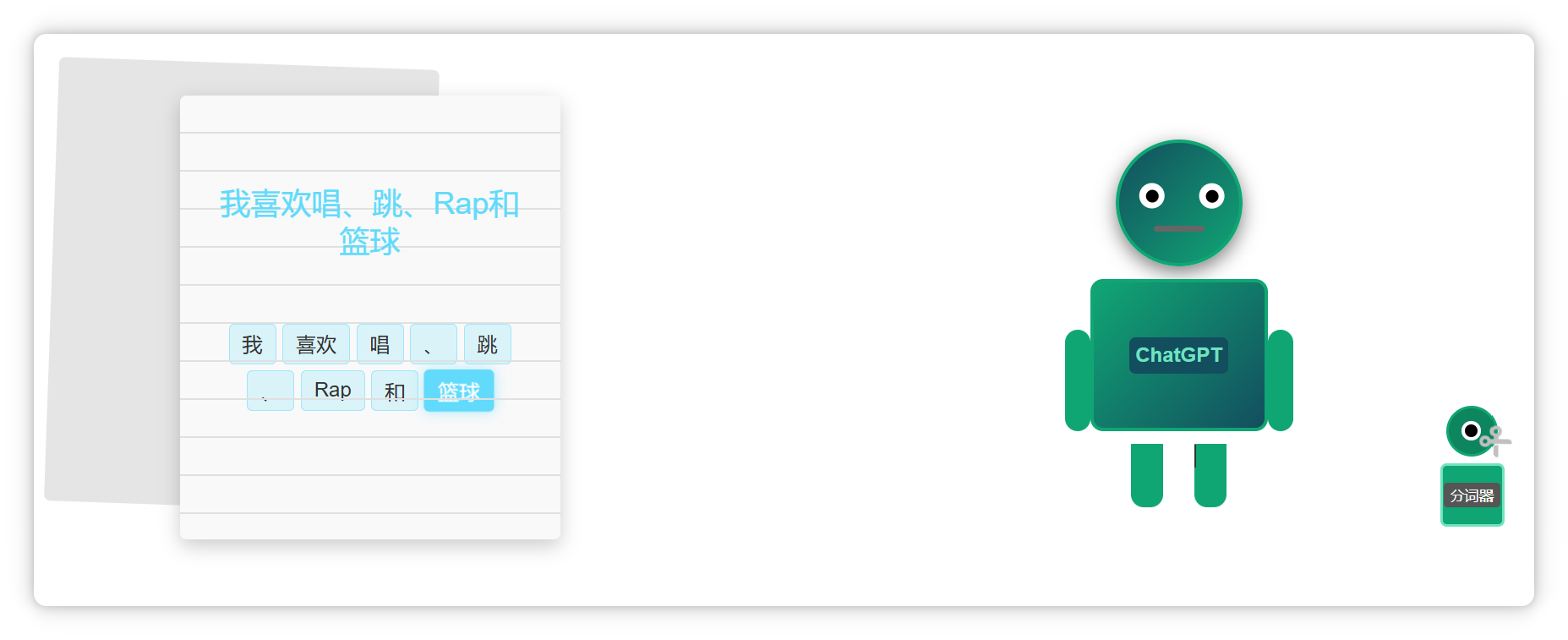
这切出来的每一个小块就叫做一个 Token。

比如这段话(我喜欢唱、跳、Rap和篮球),在大模型里可能会被切成这个样子。

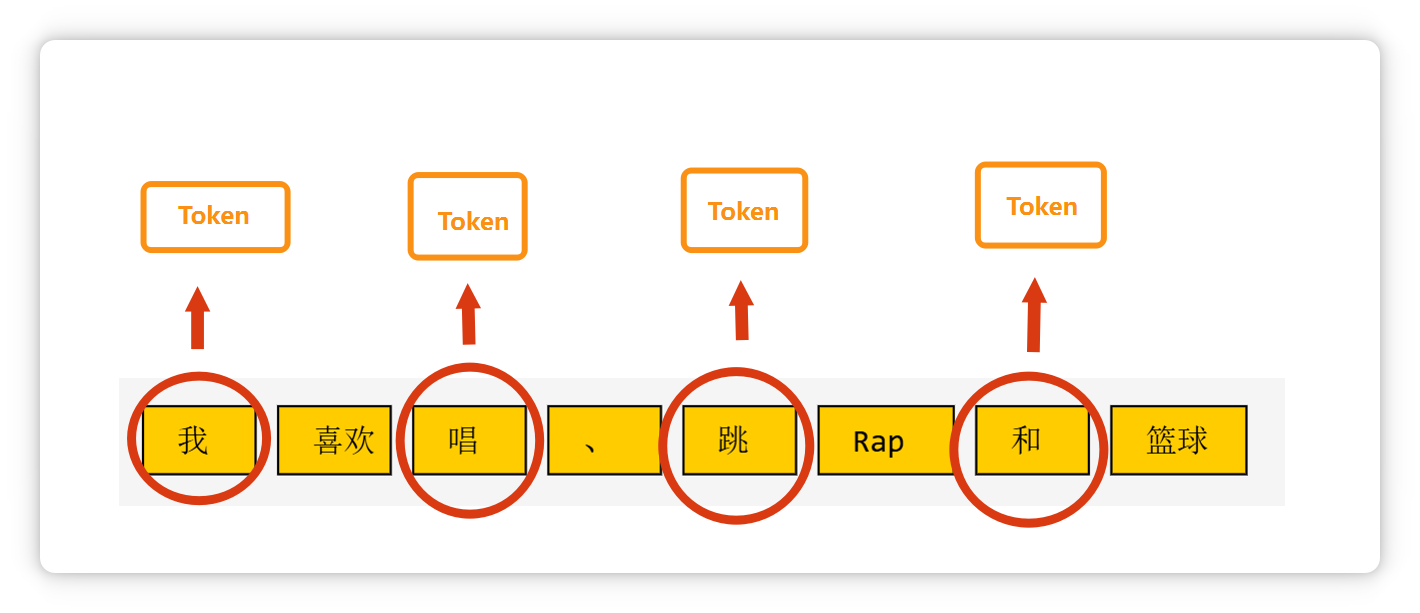
像单个汉字,可能是一个 Token。
两个汉字构成的词语,也可能是一个 Token。
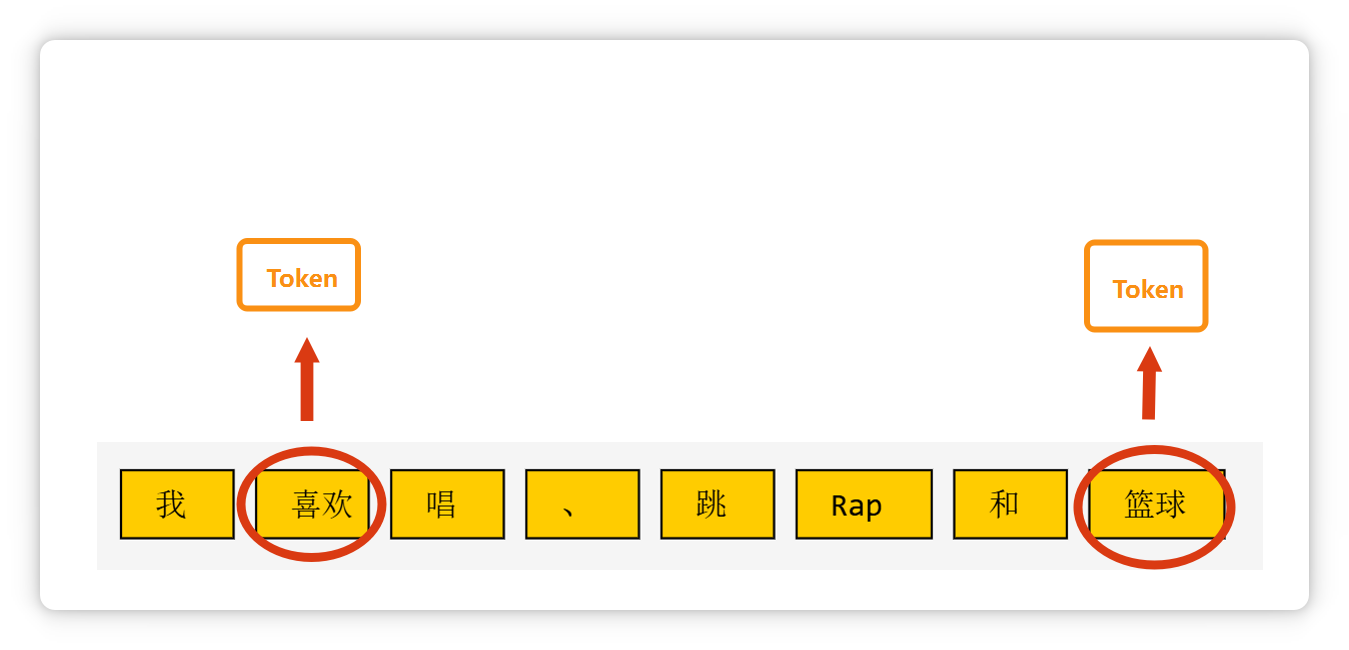
三个字构成的常见短语,也可能是一个 Token。
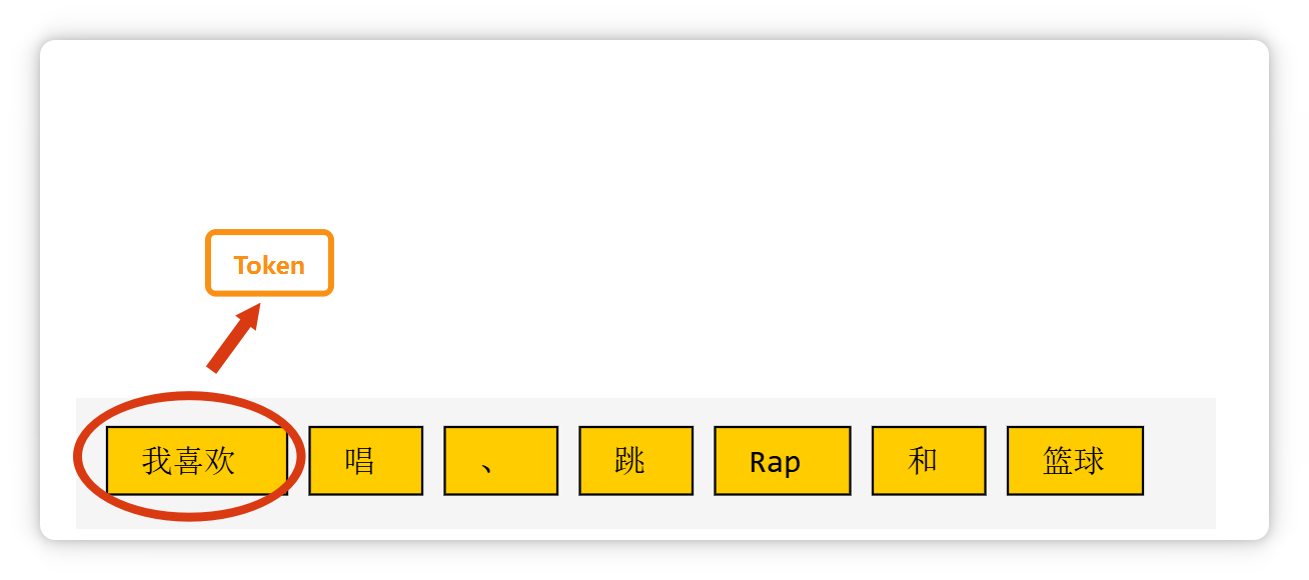
一个标点符号,也可能是一个 Token。
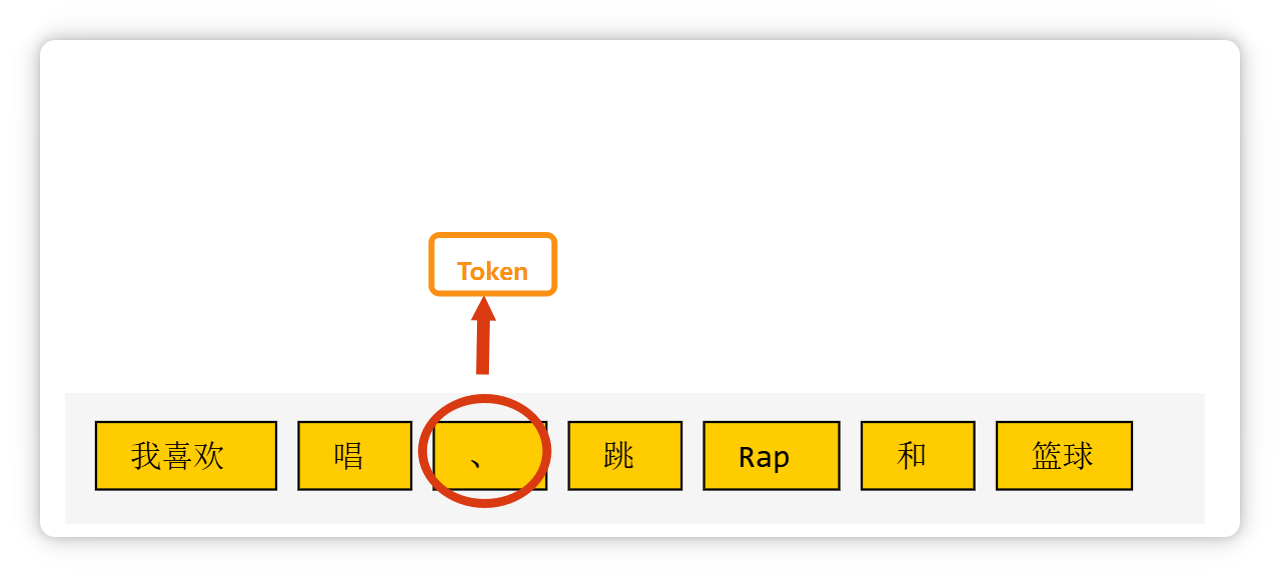
一个单词,或者是几个字母组成的一个词缀,也可能是一个 Token。

大模型在输出文字的时候,也是一个 Token 一个 Token 的往外蹦,所以看起来可能有点像在打字一样。

朋友听完以后,好像更疑惑了:

于是,我决定换一个方式,给他通俗解释一下。
大模型的Token究竟是啥,以及为什么会是这样。
首先,请大家快速读一下这几个字:

是不是有点没有认出来,或者是需要愣两秒才可以认出来?
但是如果这些字出现在词语或者成语里,你瞬间就可以念出来。

那之所以会这样,是因为我们的大脑在日常生活中,喜欢把这些有含义的词语或者短语,优先作为一个整体来对待。

不到万不得已,不会去一个字一个字的抠。

这就导致我们对这些词语还挺熟悉,单看这些字(旯妁圳侈邯)的时候,反而会觉得有点陌生。
而大脑之所以要这么做,是因为这样可以节省脑力,咱们的大脑还是非常懂得偷懒的。

比如 “今天天气不错” 这句话,如果一个字一个字的去处理,一共需要有6个部分。

但是如果划分成3个、常见且有意义的词。

就只需要处理3个部分之间的关系,从而提高效率,节省脑力。
既然人脑可以这么做,那人工智能也可以这么做。

所以就有了分词器,专门帮大模型把大段的文字,拆解成大小合适的一个个 Token。

不同的分词器,它的分词方法和结果不一样。
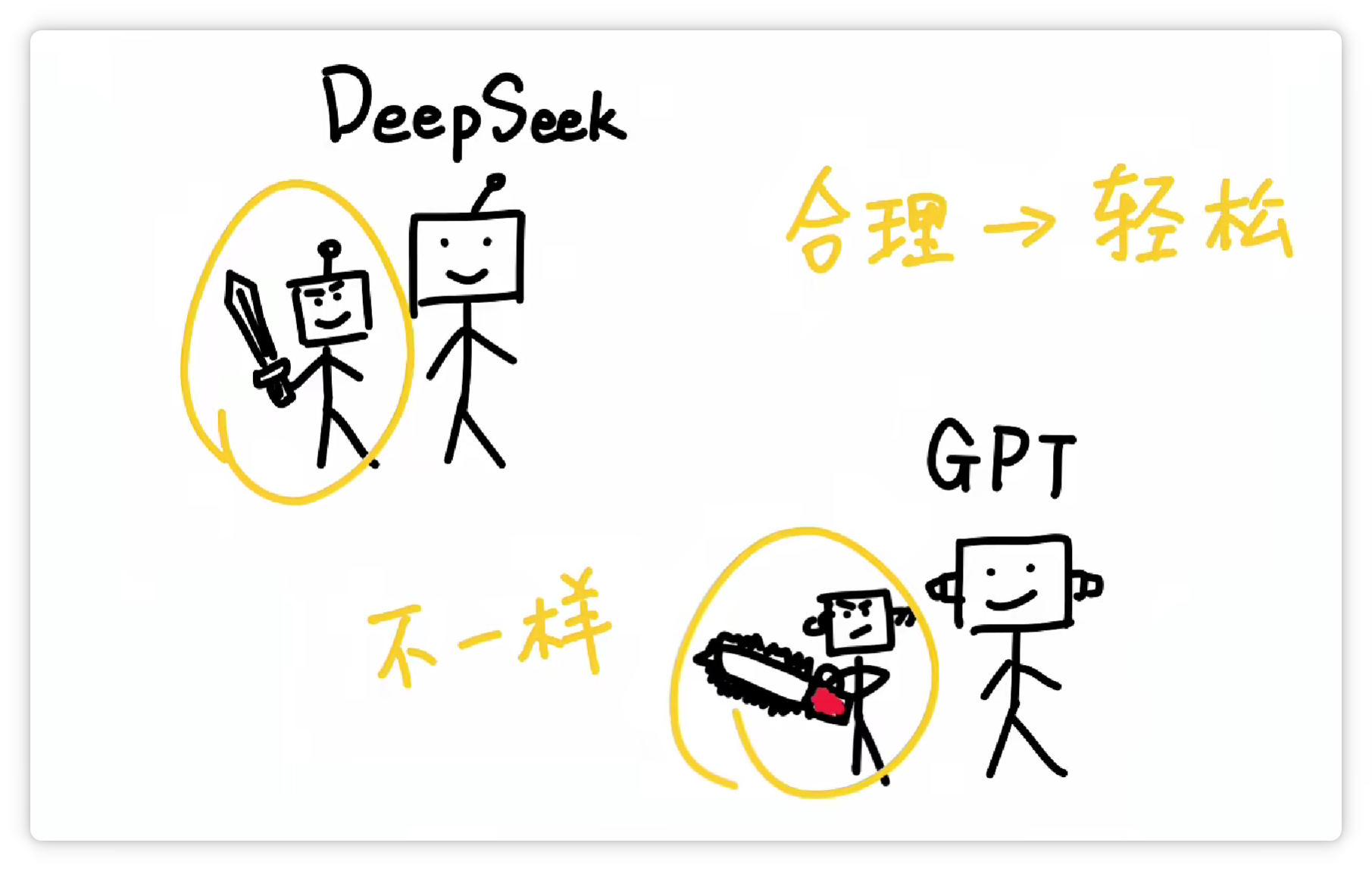
分得越合理,大模型就越轻松。这就好比餐厅里负责切菜的切配工,它的刀功越好,主厨做起菜来当然就越省事。

分词器究竟是怎么分的词呢?
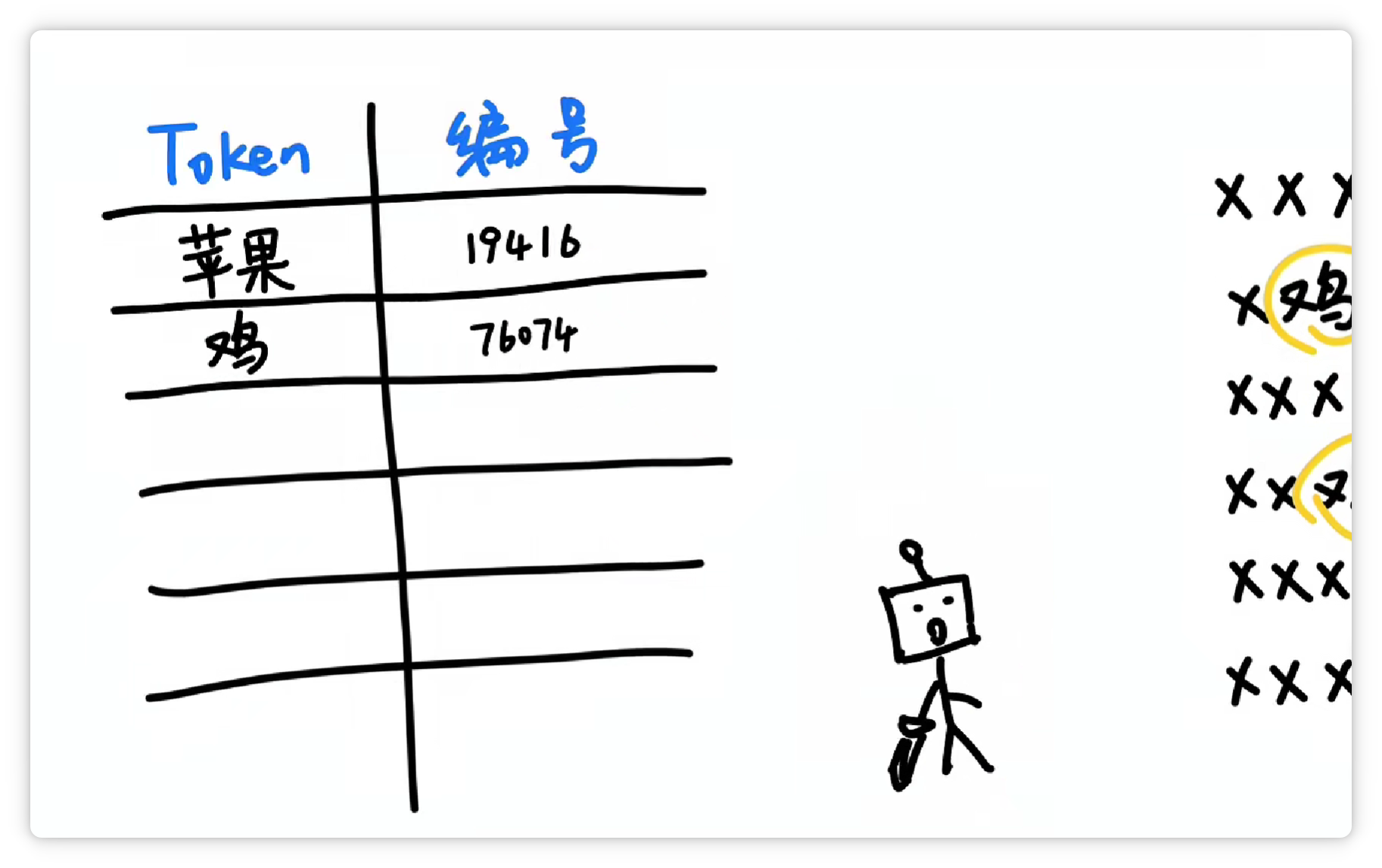
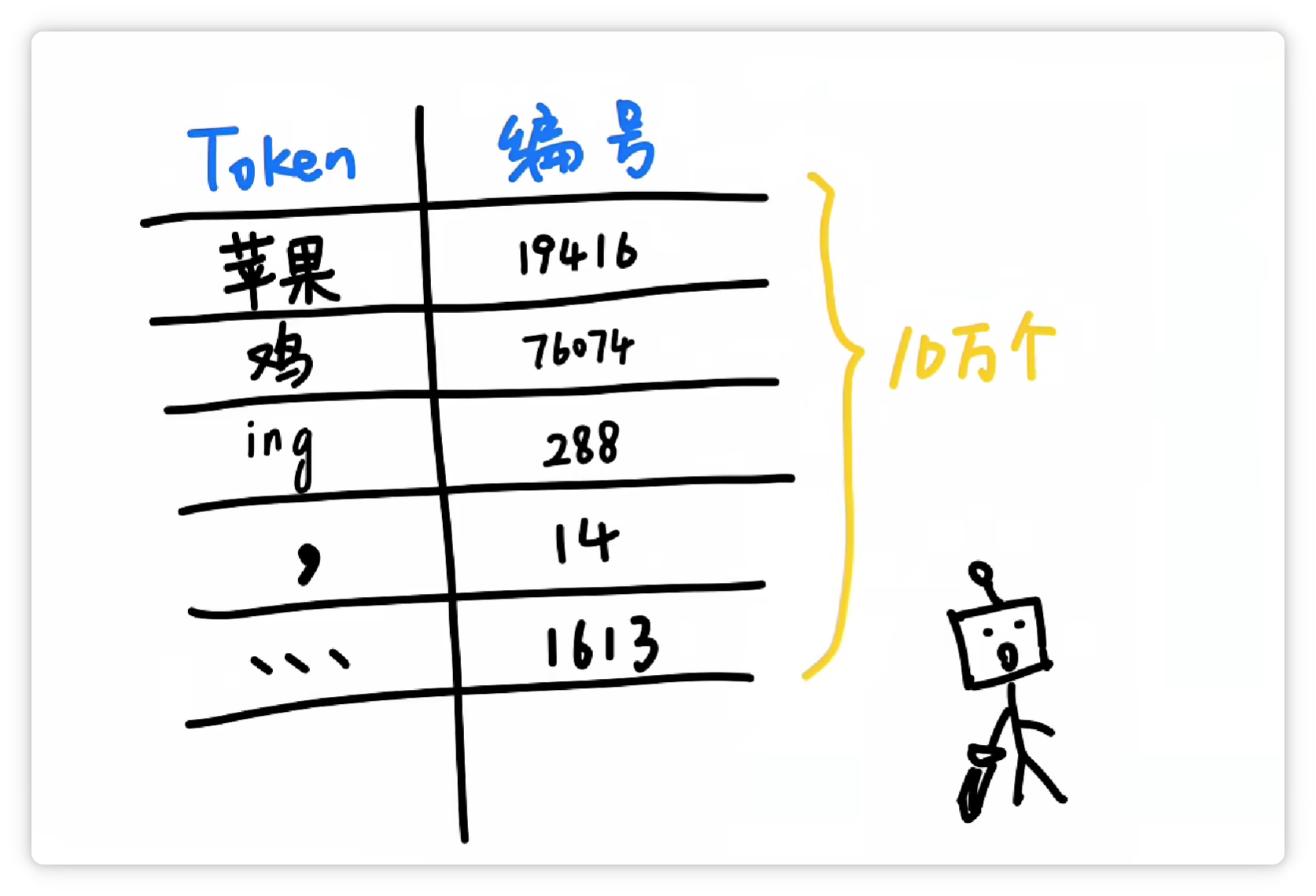
其中一种方法大概是这样,分词器统计了大量文字以后,发现 “苹果” 这两个字,经常一起出现。
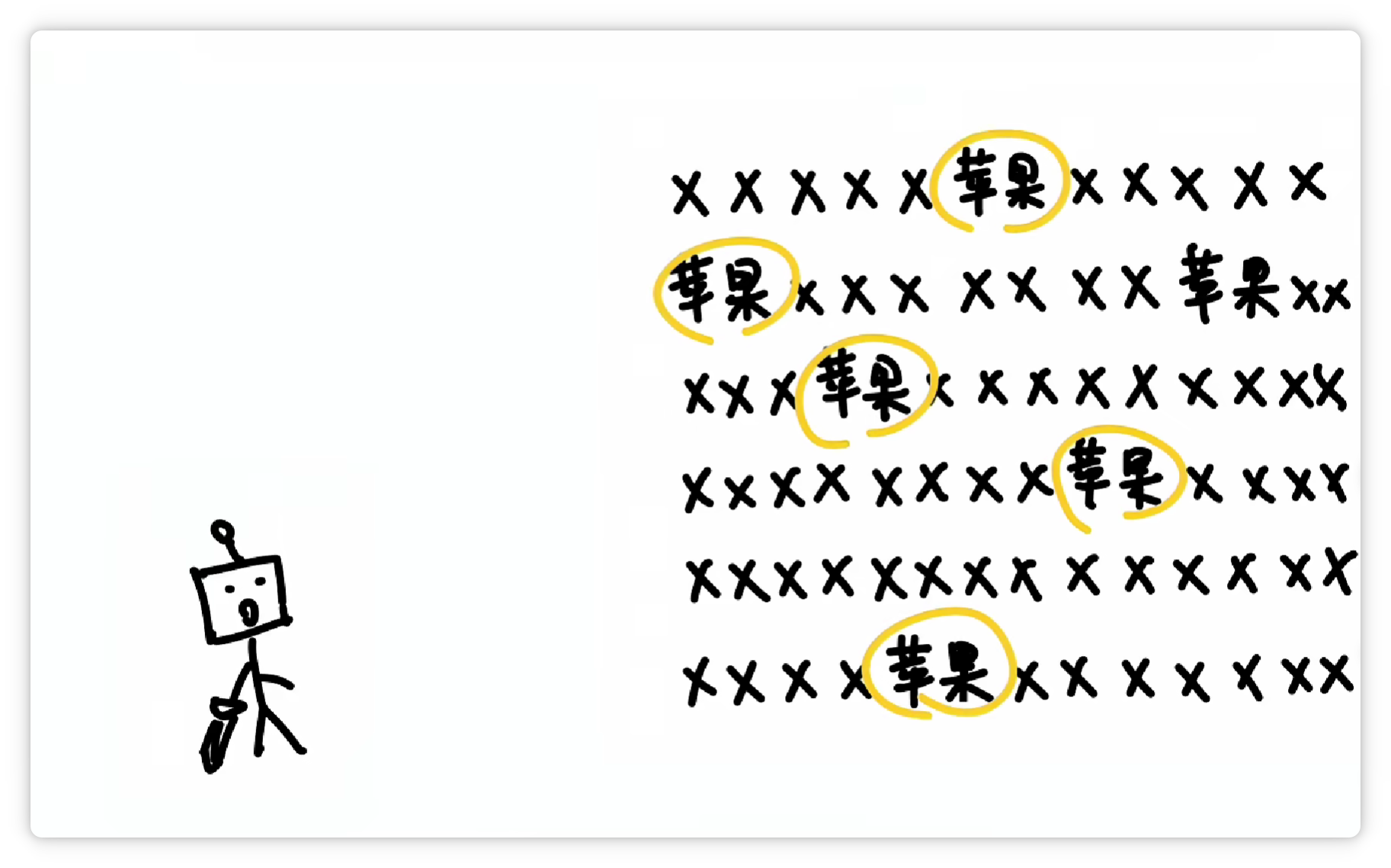
就把它们打包成一个 Token,给它一个数字编号,比如 19416。

然后丢到一个大的词汇表里。

这样下次再看到 “苹果” 这两个字的时候,就可以直接认出这个组合就可以了。
然后它可能又发现 “鸡” 这个字经常出现,并且可以搭配不同的其他字。

于是它就把 “鸡” 这个字,打包成一个 Token,给它配一个数字编号,比如 76074。

并且丢到词汇表里。
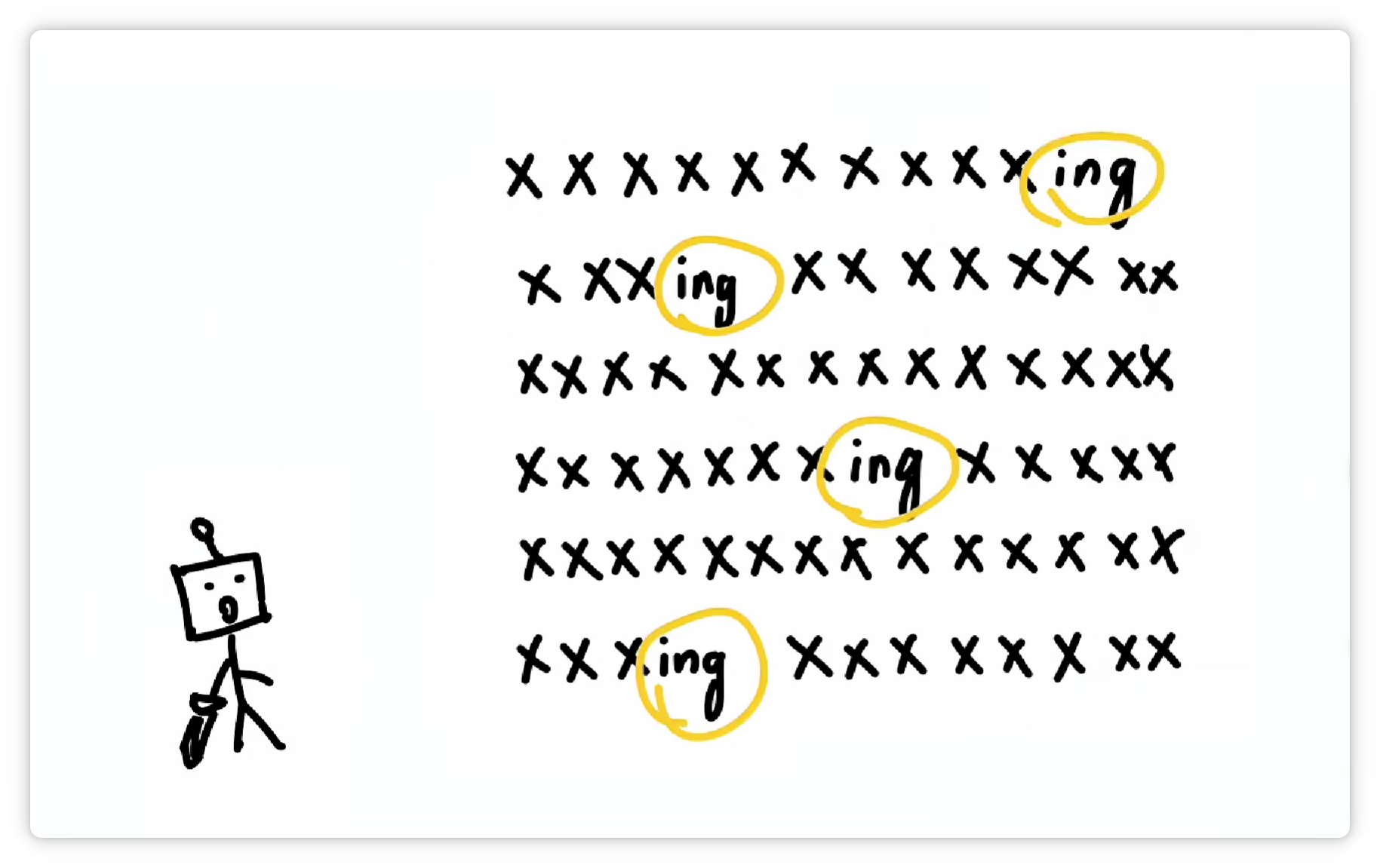
它又发现 “ing” 这三个字母经常一起出现。
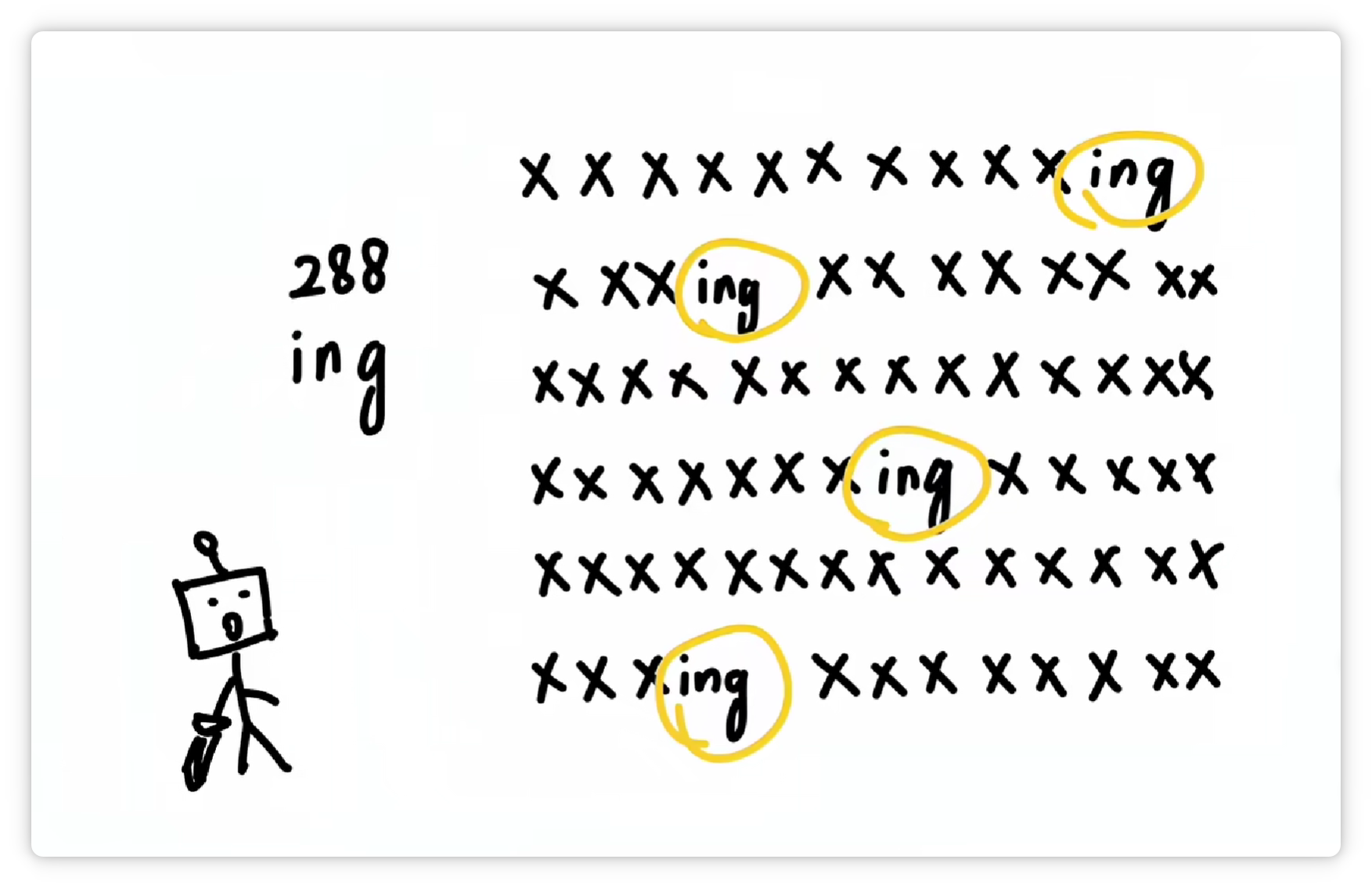
于是又把 “ing” 这三个字母打包成一个 Token,给它配一个数字编号,比如 288。
并且收录到词汇表里。

它又发现 “逗号” 经常出现。

于是又把 “逗号” 也打包作为一个 Token,给它配一个数字编号,比如 14。

收录到词汇表里。
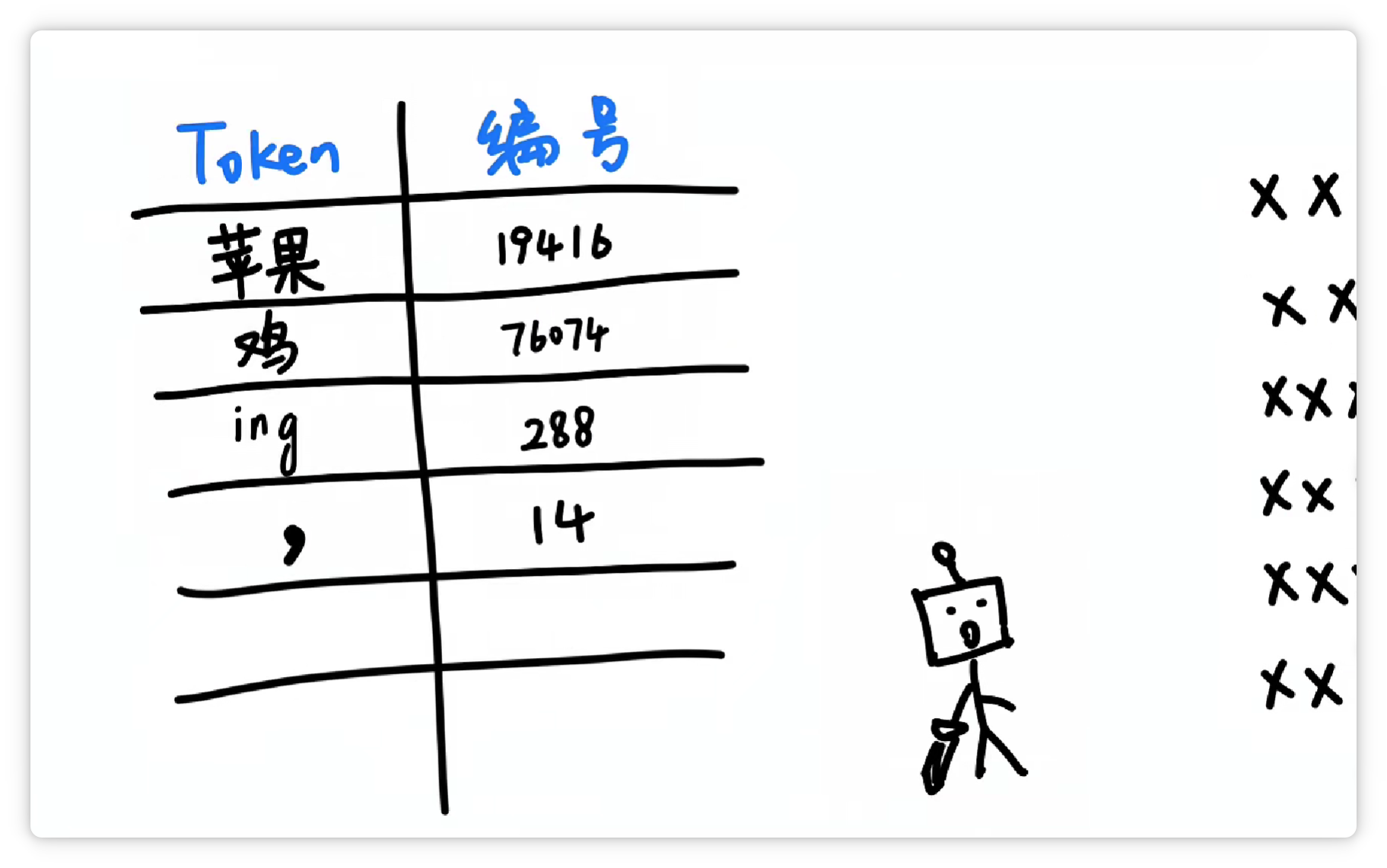
经过大量统计和收集,分词器就可以得到一个庞大的Token表。

可能有5万个、10万个,甚至更多Token,可以囊括我们日常见到的各种字、词、符号等等。
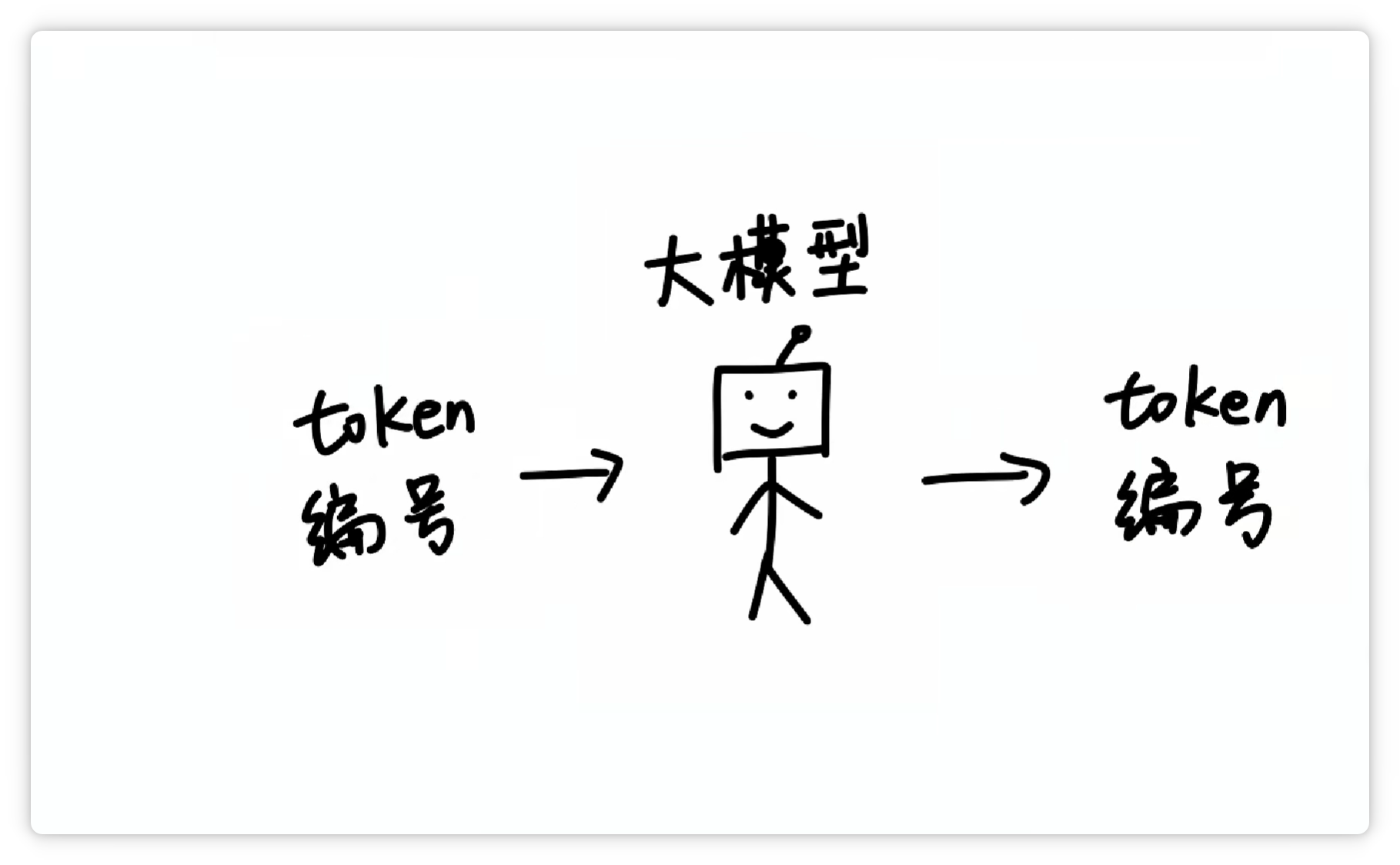
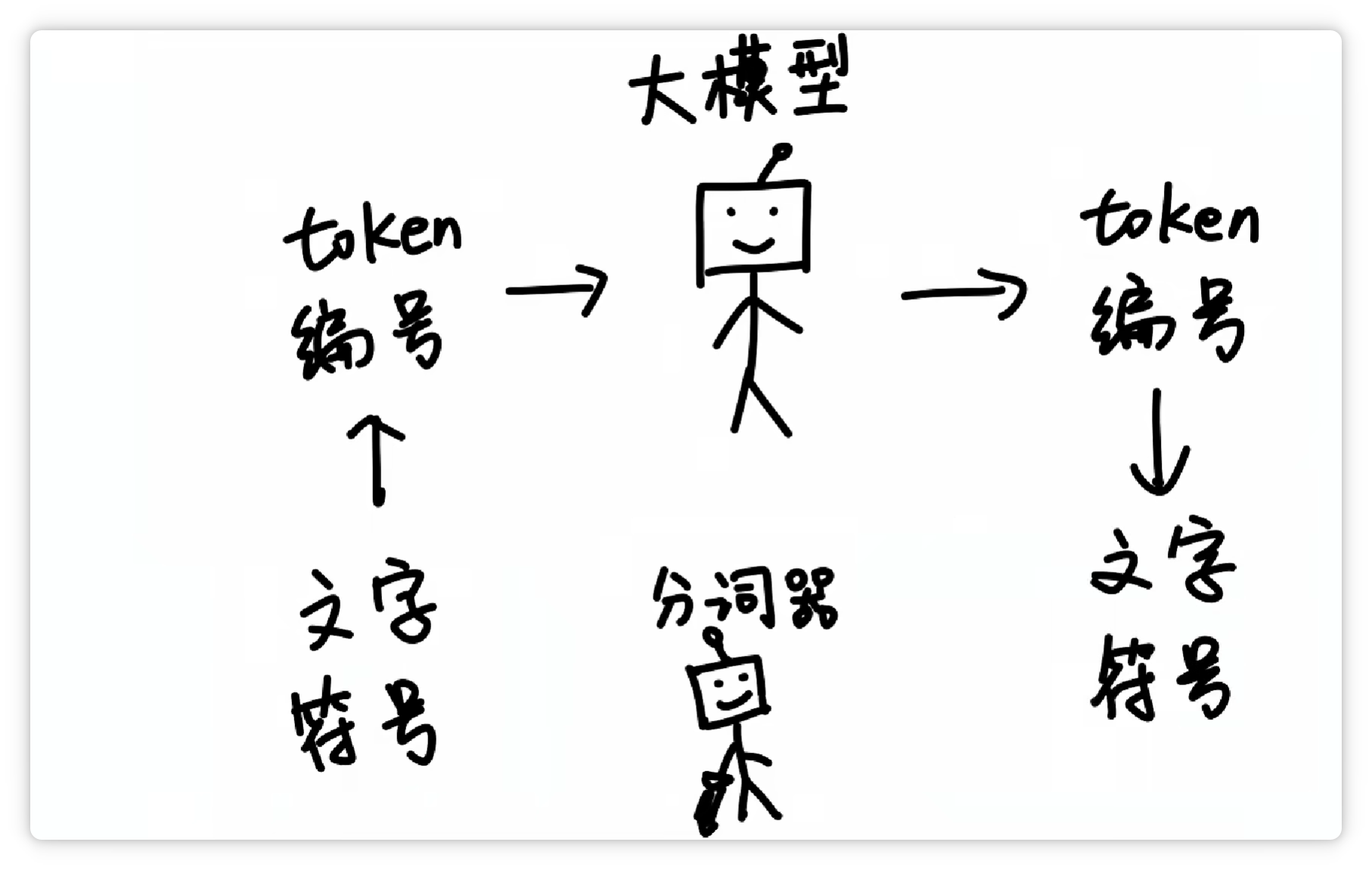
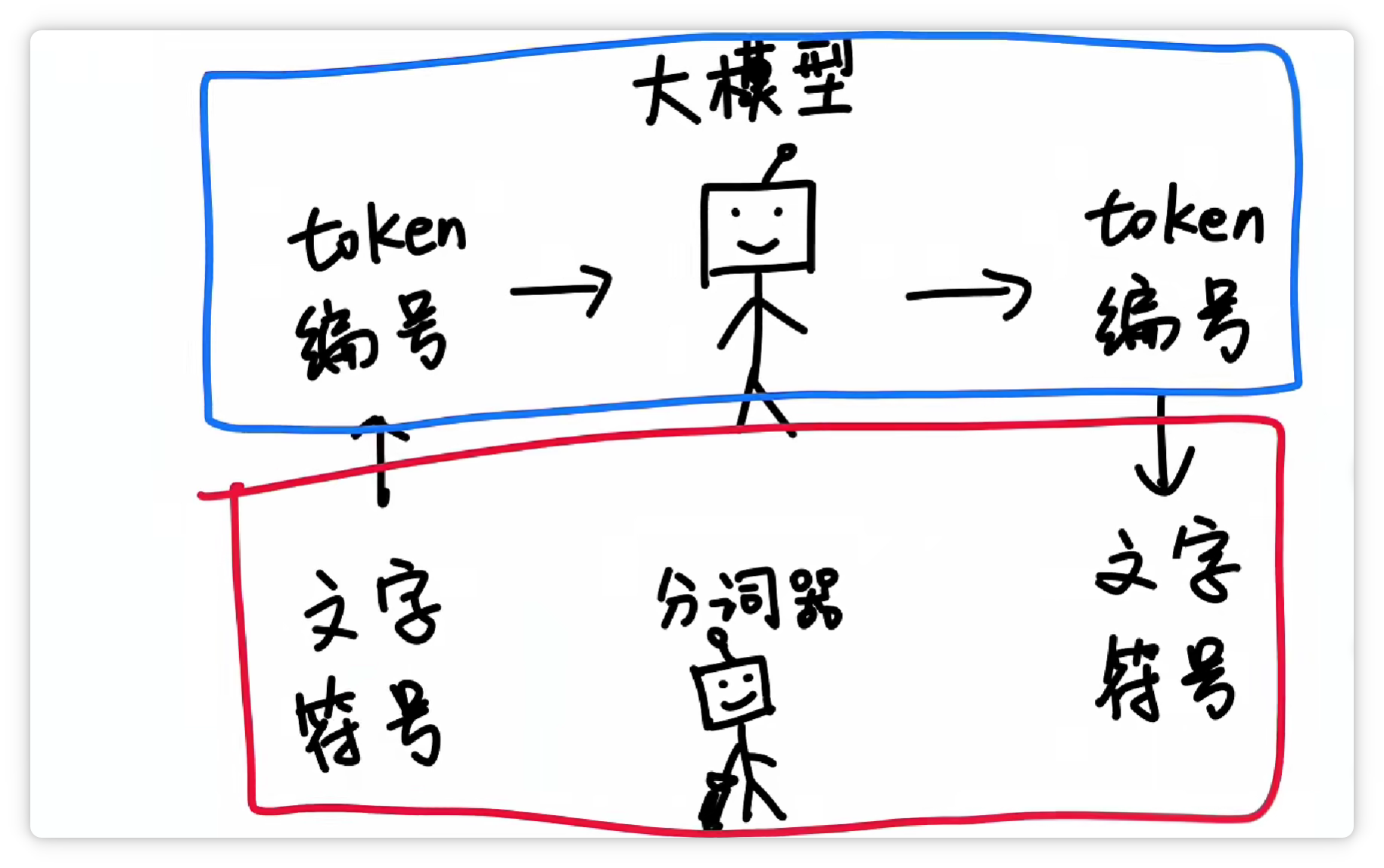
这样一来,大模型在输入和输出的时候,都只需要面对一堆数字编号就可以了。
再由分词器按照Token表,转换成人类可以看懂的文字和符号。
这样一分工,工作效率就非常高。
有这么一个网站 Tiktokenizer:https://tiktokenizer.vercel.app
输入一段话,它就可以告诉你,这段话是由几个Token构成的,分别是什么,以及这几个Token的编号分别是多少。
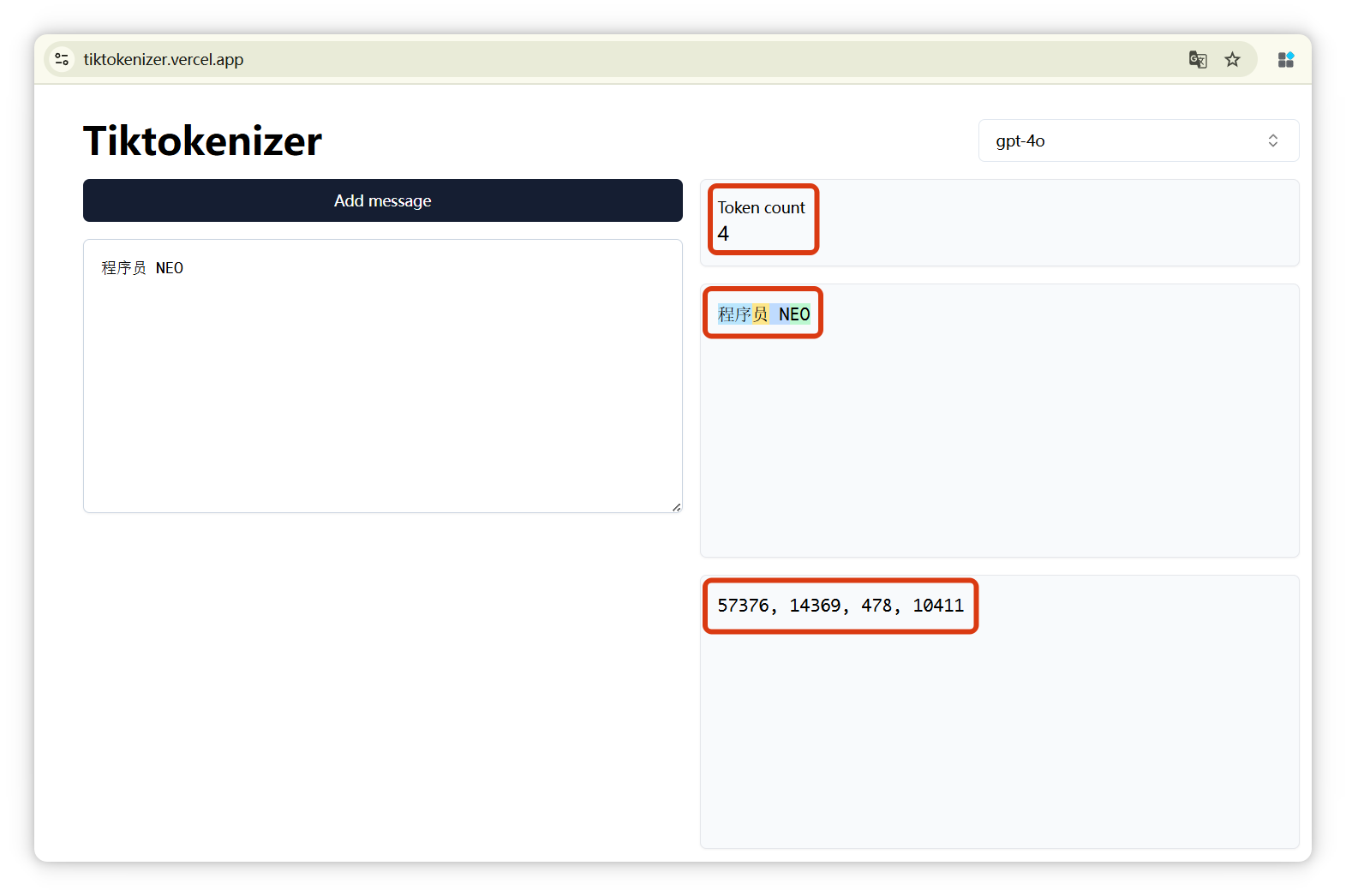
我来演示一下,这个网站有很多模型可以选择,像 GPT-4o、DeepSeek、LLaMA 等等。

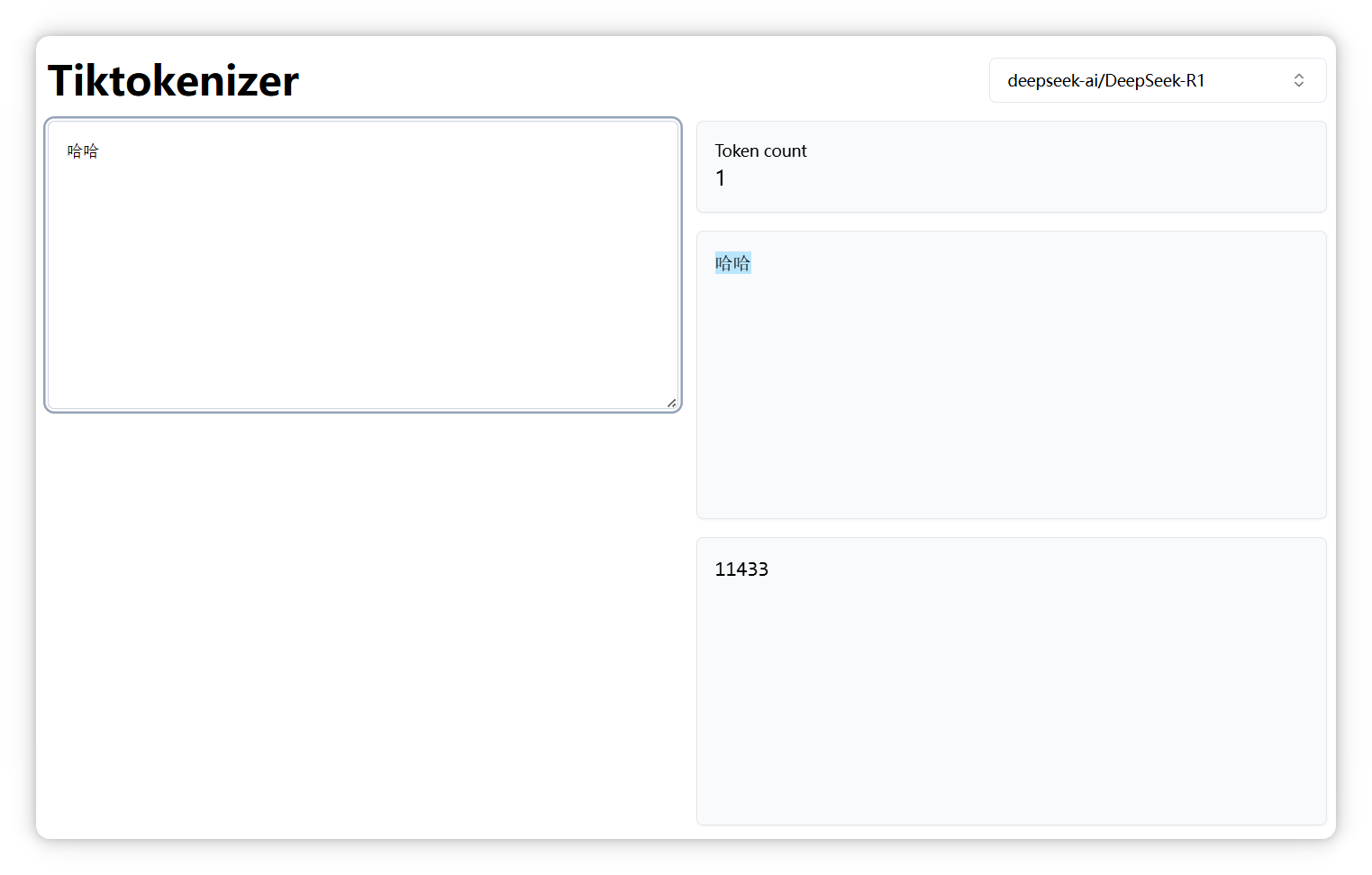
我选的是 DeepSeek,我输入 “哈哈”,显示是一个 Token,编号是 11433:
“哈哈哈”,也是一个 Token,编号是 40886:

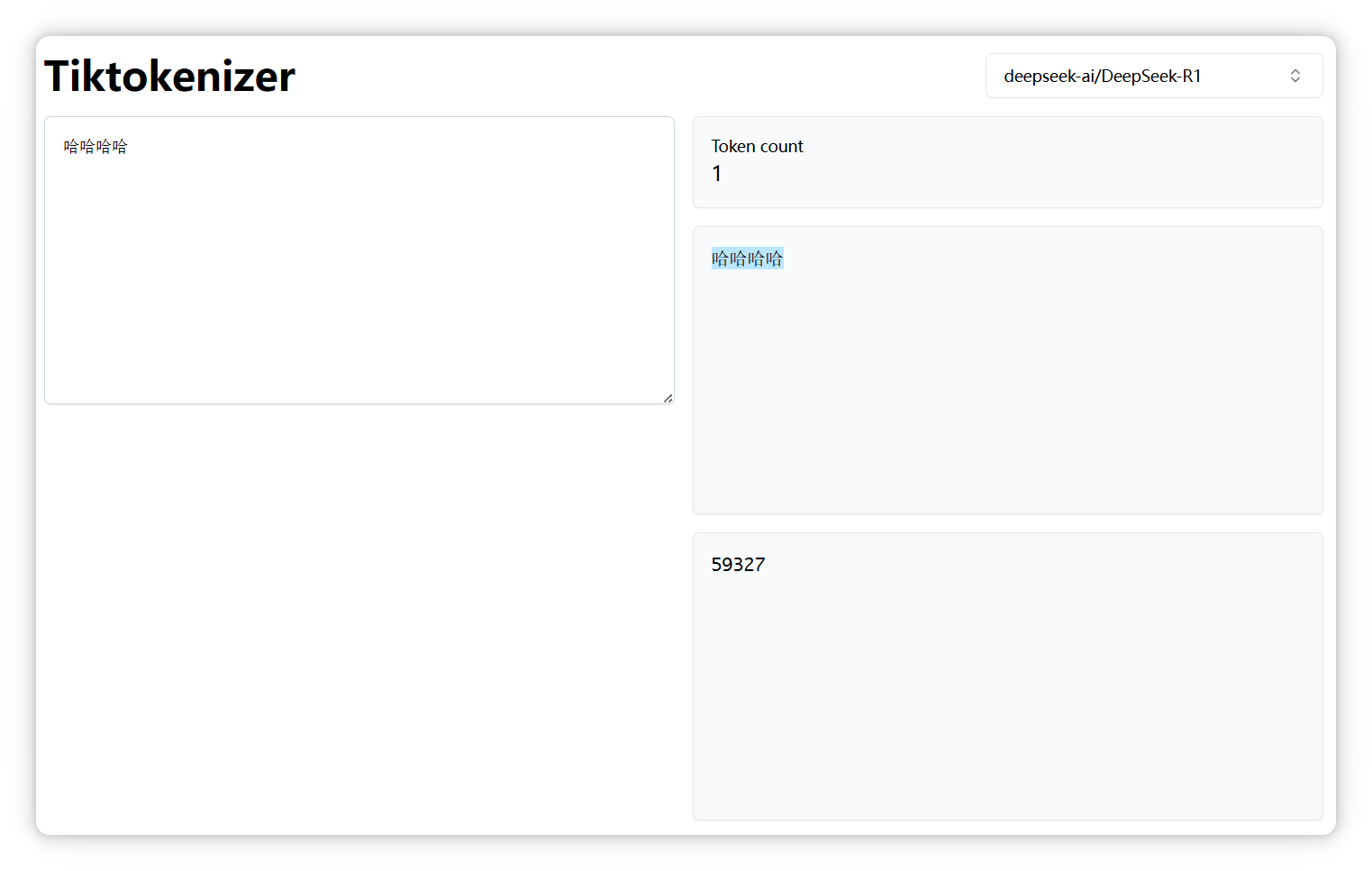
4个 “哈”,还是一个 Token,编号是 59327:
但是5个 “哈”,就变成了两个Token,编号分别是 11433, 40886:

说明大家平常用两个 “哈” 或者三个的更多。
再来,“一心一意” 是三个 Token。
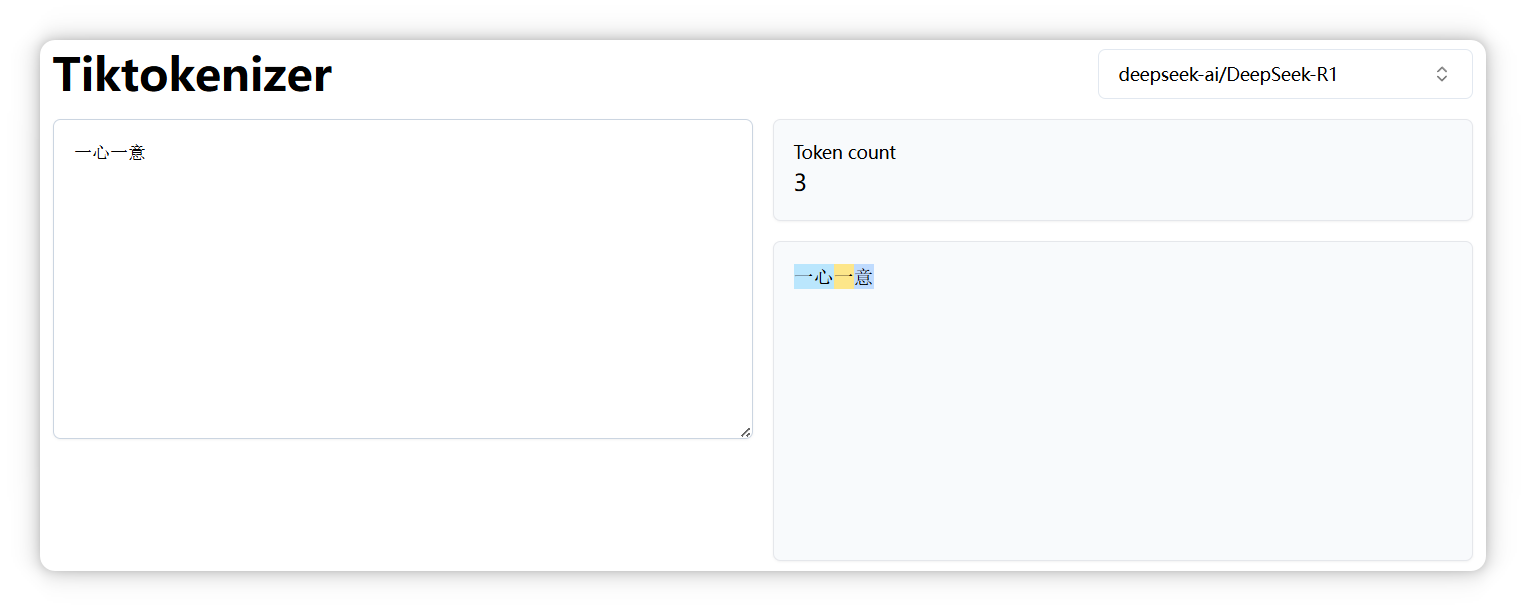
“鸡蛋” 是一个 Token。
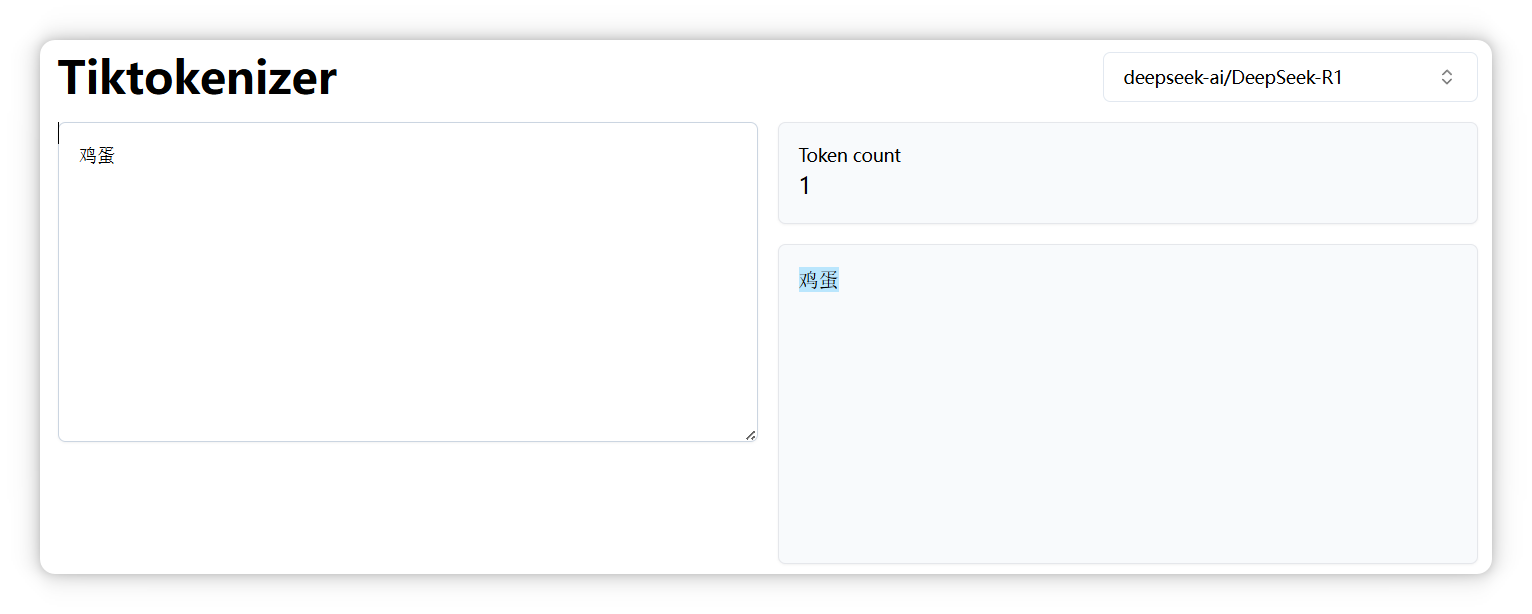
但是 “鸭蛋” 是两个 Token。
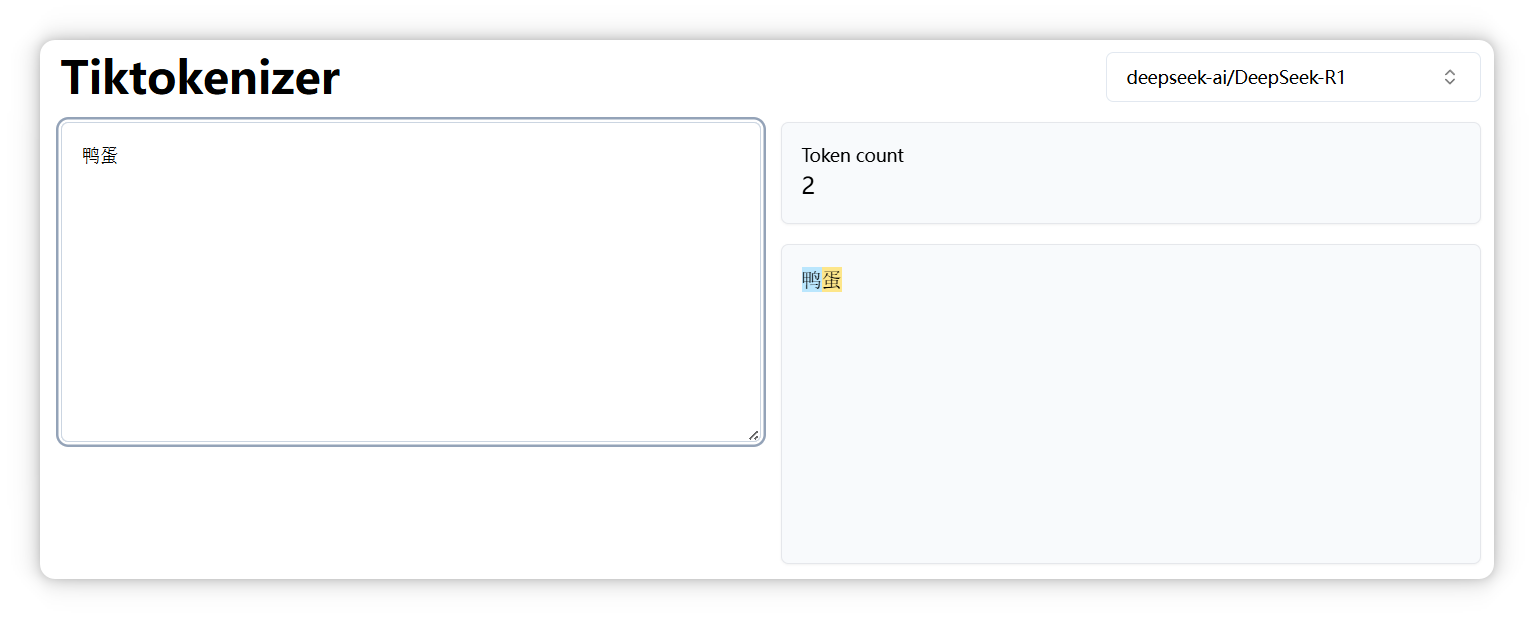
“关羽” 是一个 Token。
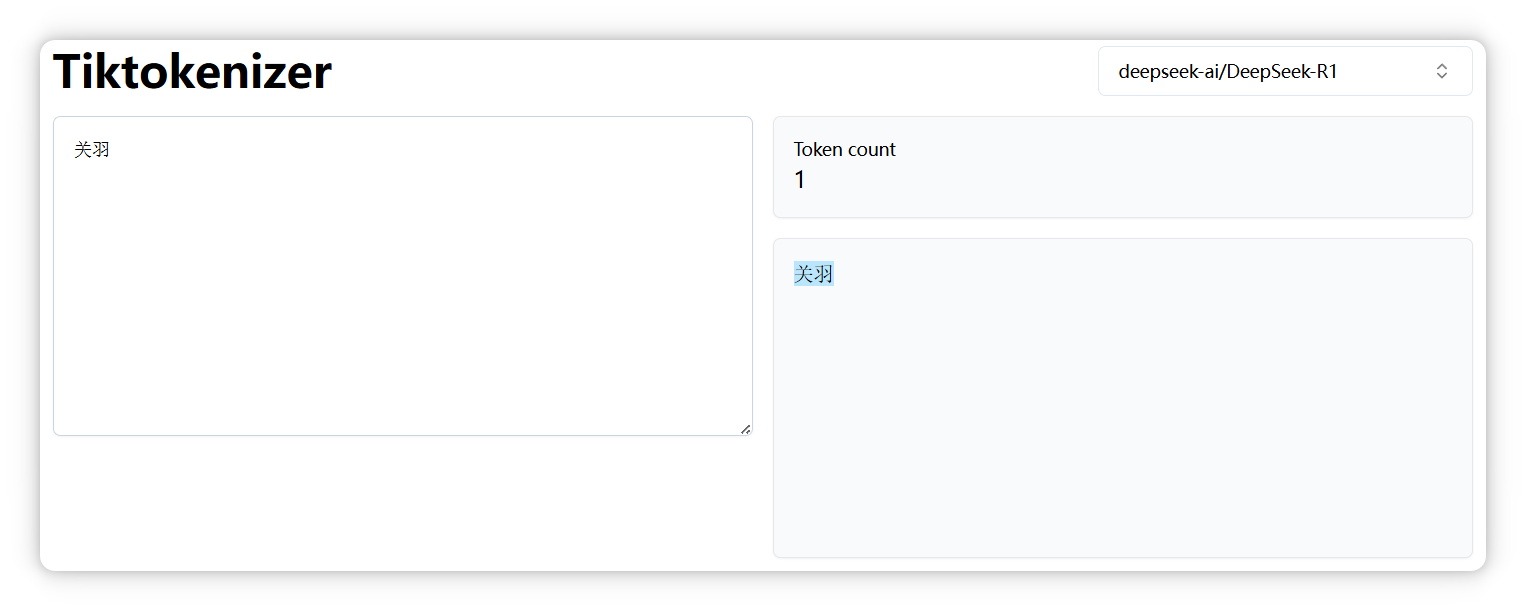
“张飞” 是两个 Token。
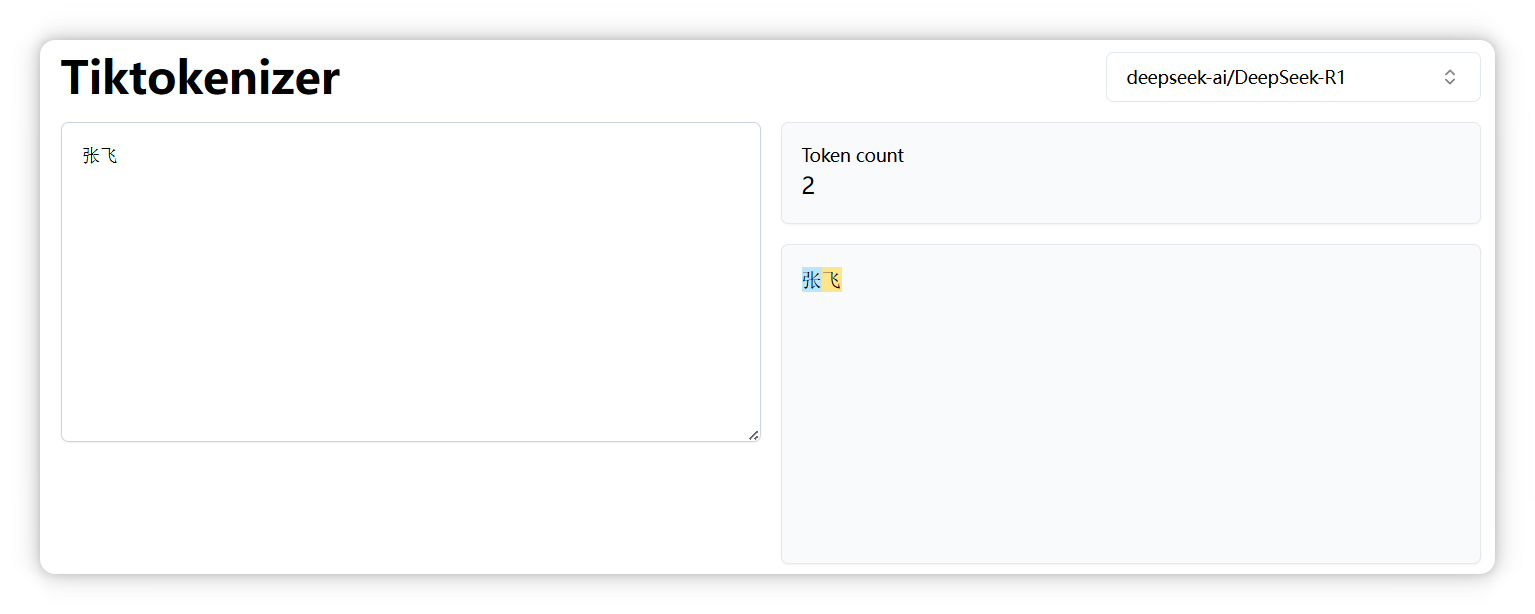
“孙悟空” 是一个 Token。
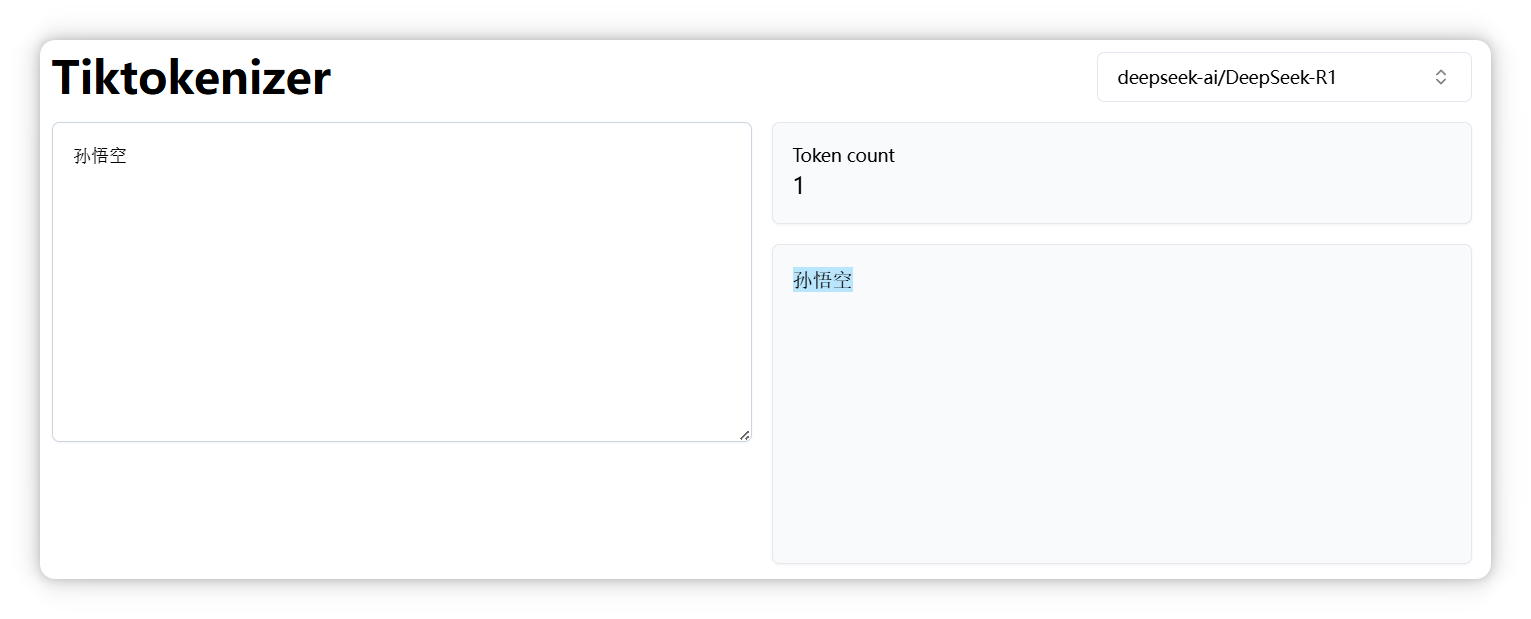
“沙悟净” 是三个 Token。
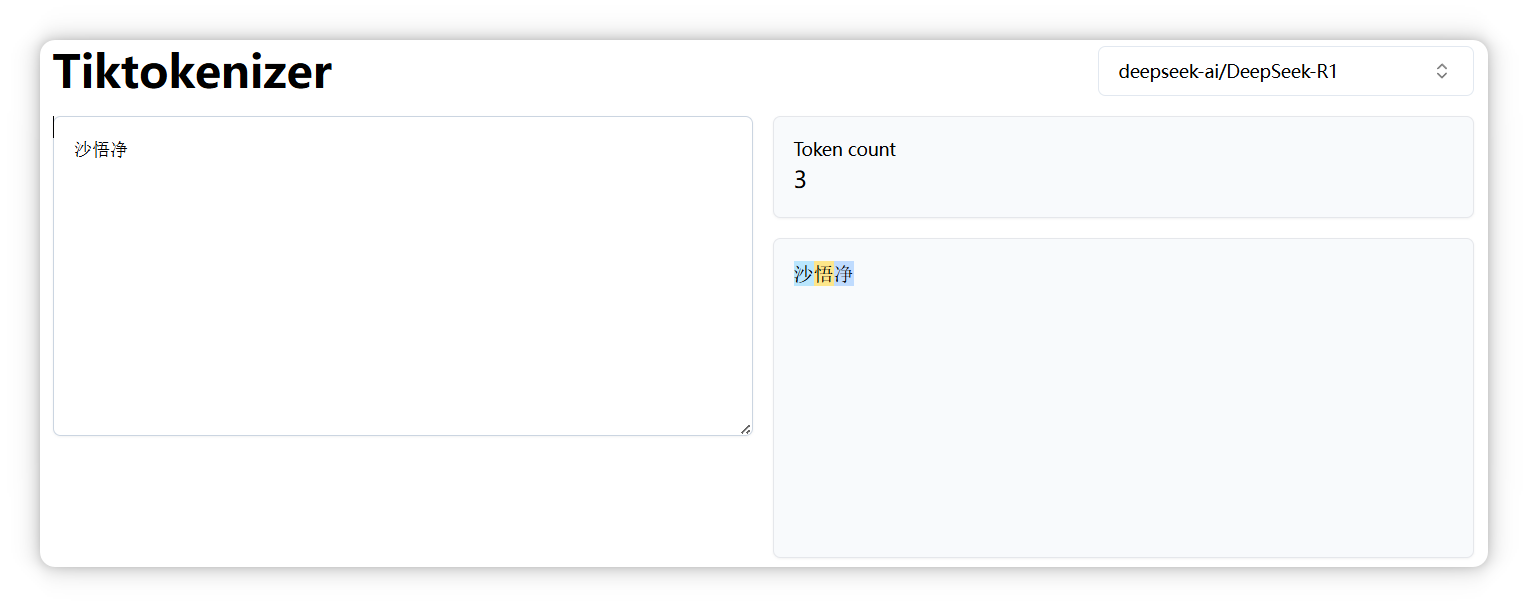
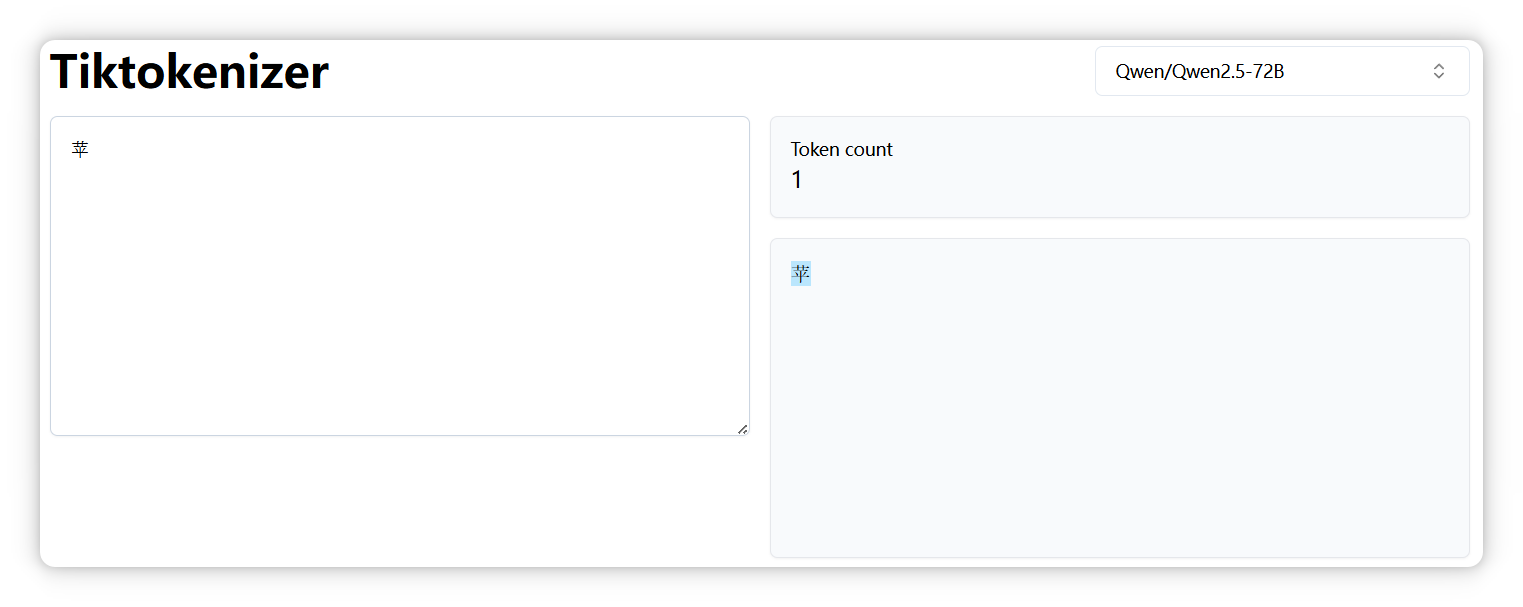
另外,正如前面提到的,不同模型的分词器可能会有不同的切分结果。比如,“苹果” 中的 “苹” 字,在 DeepSeek 中被拆分成两个 Token。
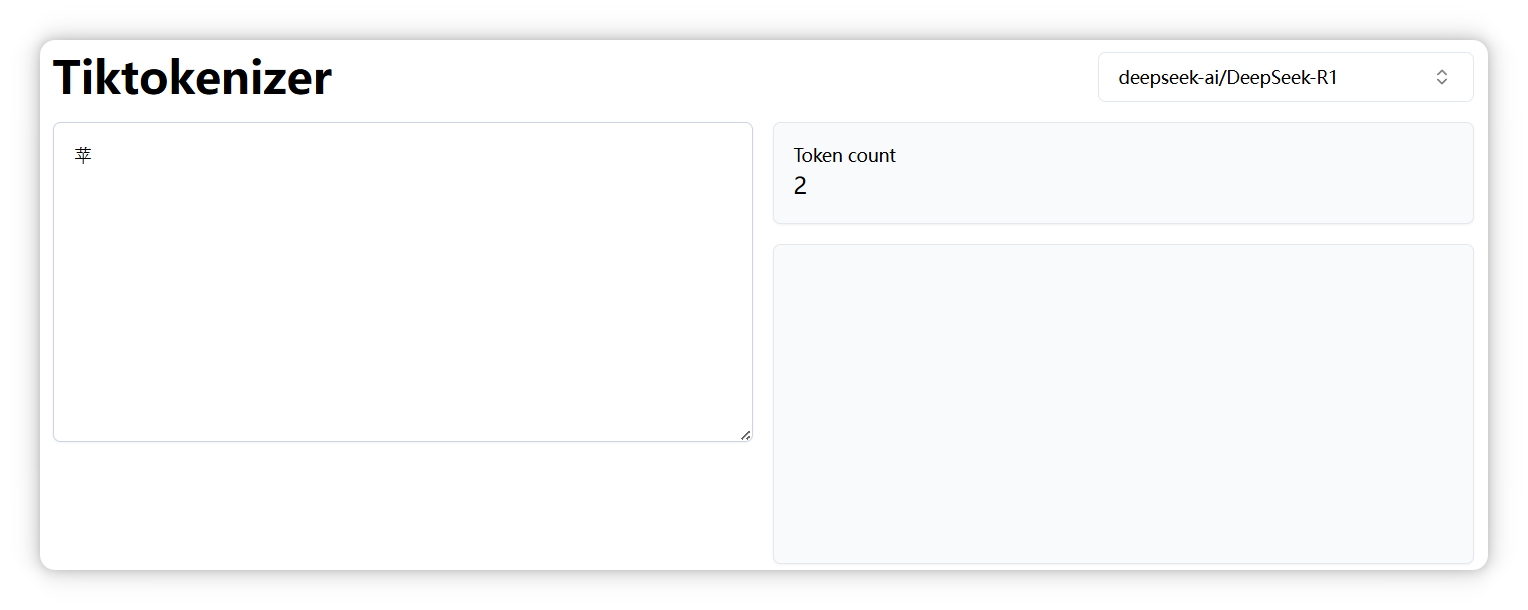
但是在 Qwen 模型里却是一个 Token。
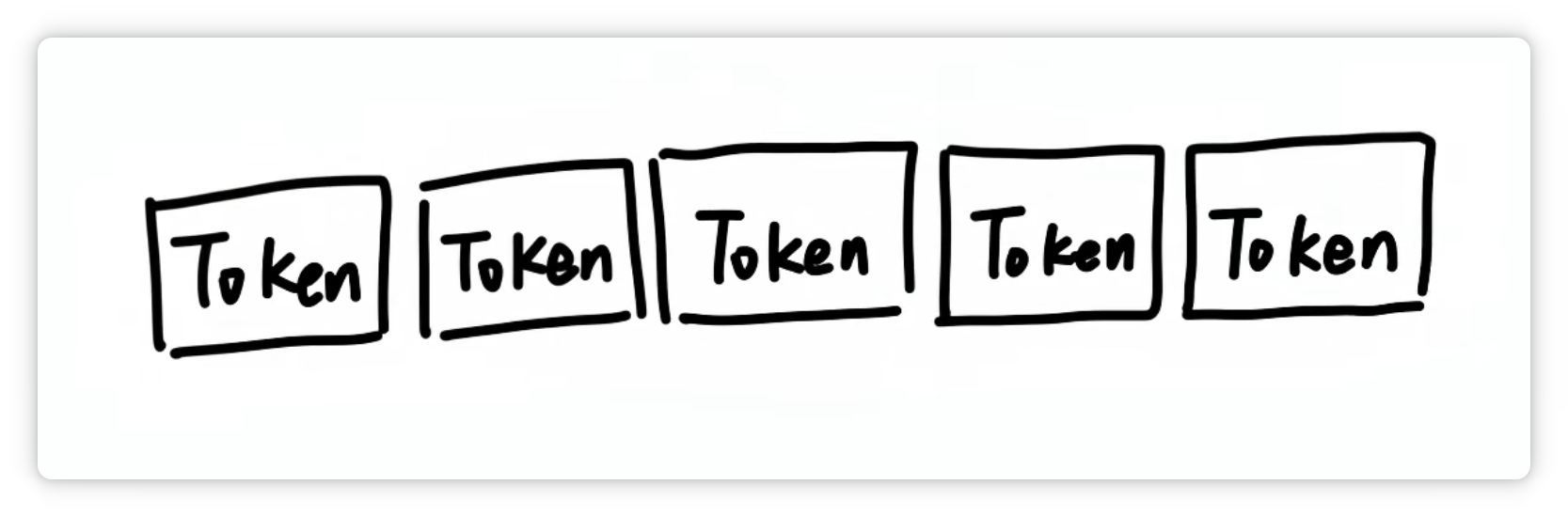
所以回过头来看,Token 到底是什么?
它就是构建大模型世界的一块块积木。
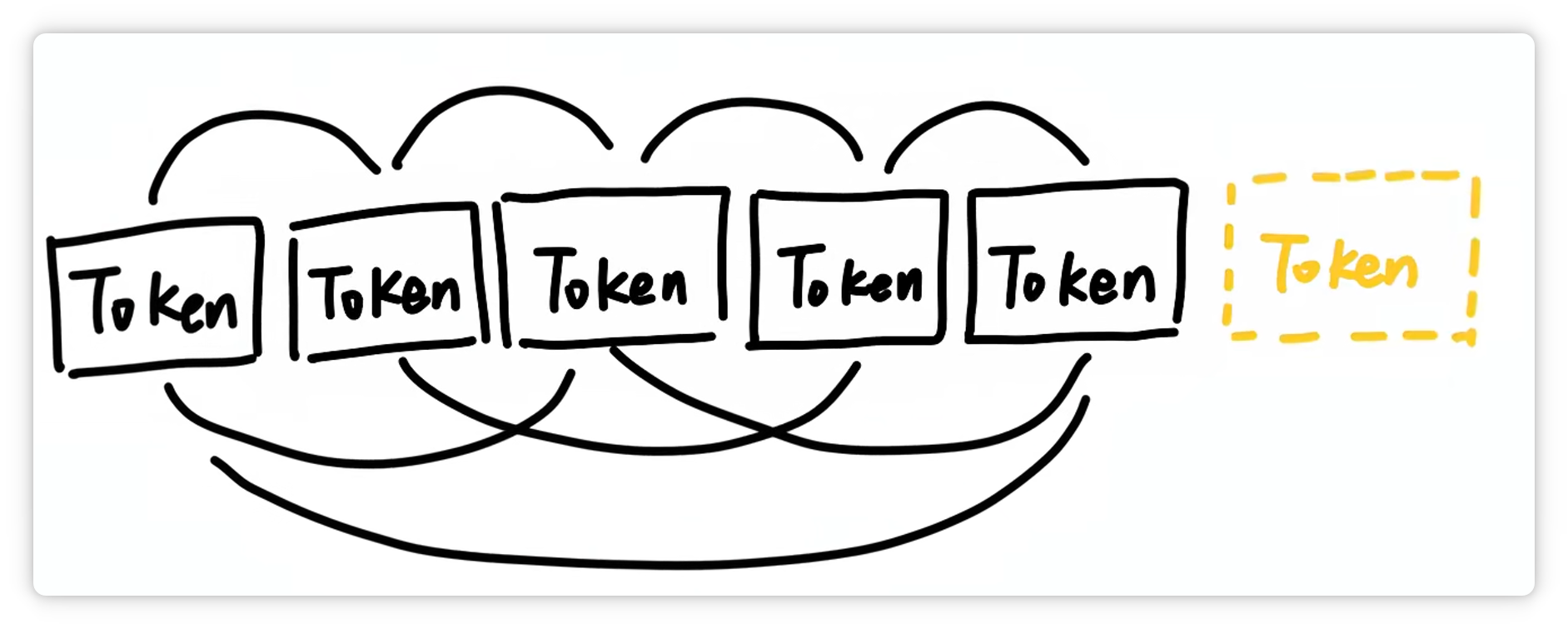
大模型之所以能理解和生成文本,就是通过计算这些 Token 之间的关系,来预测下一个最可能出现的 Token。
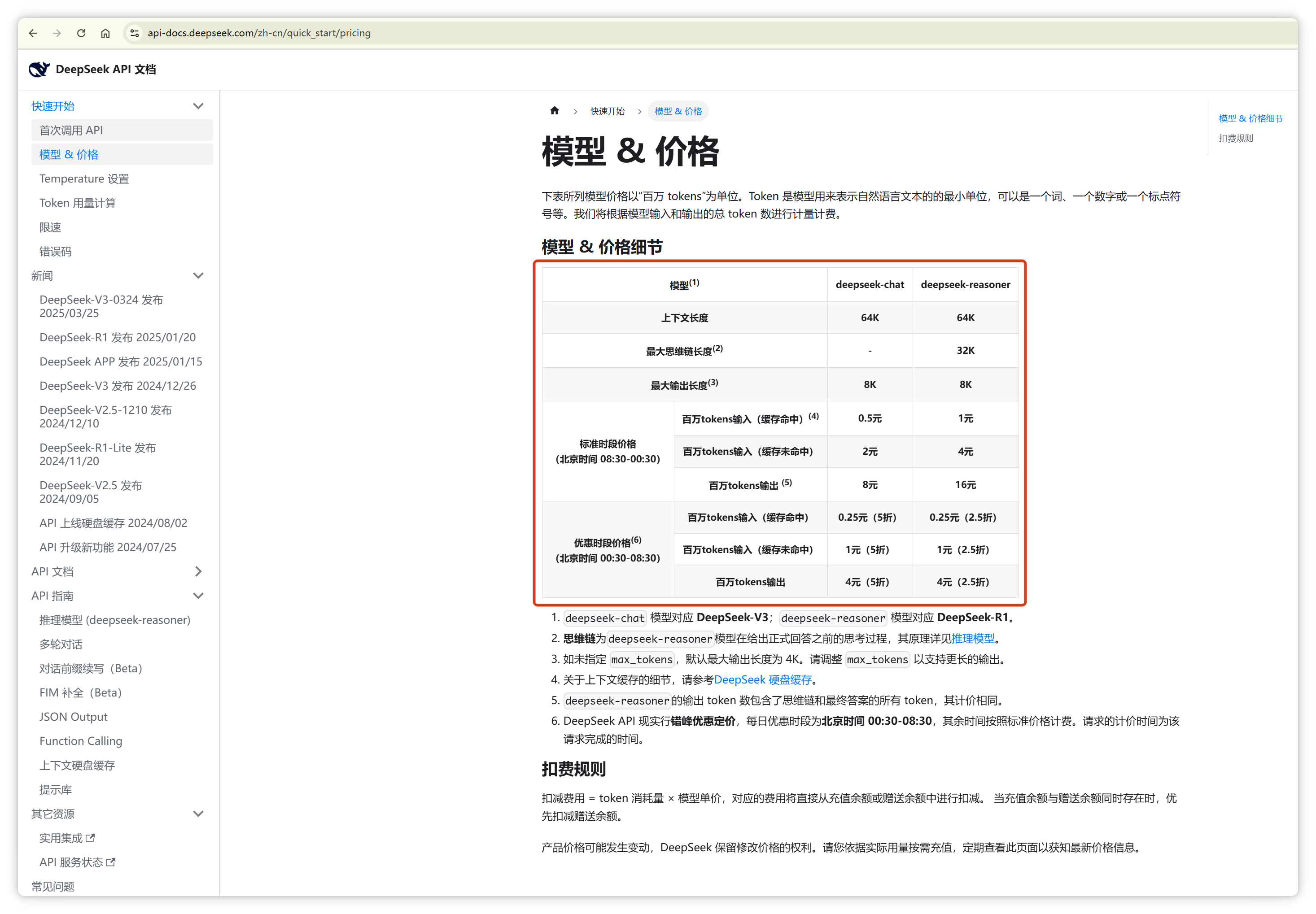
这就是为什么几乎所有大模型公司都按照 Token 数量计费,因为 Token 数量直接对应背后的计算成本。
“Token” 这个词不仅用于人工智能领域,在其他领域也经常出现。其实,它们只是恰好都叫这个名字而已。
就像同样都是 “车模”,汽车模型和车展模特,虽然用词相同,但含义却截然不同。

FAQ
1. 苹为啥会是2个?
因为“苹” 字单独出现的概率太低,无法独立成为一个 Token。
2. 为什么张飞算两个 Token?
“张” 和 “飞” 一起出现的频率不够高,或者“ 张” 字和 “飞” 字的搭配不够稳定,经常与其他字组合,因此被拆分为两个 Token。
Token 在大模型方面最好的翻译是 '词元' 非常的信雅达。
欢迎关注我的微信公众号【程序员 NEO】!
这里有丰富的技术分享、实用的编程技巧、深度解析微服务架构,还有更多精彩内容等你探索!
大模型 Token 究竟是啥:图解大模型Token的更多相关文章
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- Local Response Normalization作用——对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中.AlexNet主要使用到的新技术点如下. (1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过 ...
- IM群聊消息究竟是存1份(即扩散读)还是存多份(即扩散写)?
1.前言 IM的群聊消息,究竟存1份(即扩散读方式)还是存多份(即扩散写方式)? 上一篇文章<IM群聊消息的已读回执功能该怎么实现?>是说,“很容易想到,是存一份”,被网友们骂了,大家争论 ...
- Atiti.大企业病与小企业病 大公司病与小公司病
Atiti.大企业病与小企业病 大公司病与小公司病 1. 大企业病,一般会符合机构臃肿 .多重领导 .人才流失的特点.1 2. 大企业病避免方法1 3. 小企业病 1 3.1.1. 表现1 4. 如何 ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- [PHP学习教程 - 文件]001.高速读写大数据“二进制”文件,不必申请大内存(Byte Block)
引言:读写大“二进制”文件,不必申请很大内存(fopen.fread.fwrite.fclose)!做到开源节流,提高速度! 每天告诉自己一次,『我真的很不错』.... 加速读写大文件,在实际工作过程 ...
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
本文简述了以下内容: 神经概率语言模型NPLM,训练语言模型并同时得到词表示 word2vec:CBOW / Skip-gram,直接以得到词表示为目标的模型 (一)原始CBOW(Continuous ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- Reactor 模型(一)基本并发编程模型
Reactor 模型(一)基本并发编程模型 Netty 系列目录 (https://www.cnblogs.com/binarylei/p/10117436.html) 在讲解 Reactor 线程模 ...
随机推荐
- CAS实现原理
一.什么是CAS? 在计算机科学中,比较和交换(Conmpare And Swap)是用于实现多线程同步的原子指令. 它将内存位置的内容与给定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新 ...
- 分布式Session解决方案详解
4种分布式session解决方案 cookie和session的区别和联系 cookie是本地客户端用来存储少量数据信息的,保存在客户端,用户能够很容易的获取,安全性不高,存储的数据量小session ...
- 史上最全memcached面试26题和答案
Memcached是什么? Memcached是一个开源的,高性能的内存绶存软件,从名称上看Mem就是内存的意思,而Cache就是缓存的意思. Memcached的作用? Memcached的作用:通 ...
- 使用GraalVM将SpringBoot工程编译成平台原生的可执行文件
原文链接:https://blog.liuzijian.com/post/209e68d0-a418-1737-503a-d47e6d2d9350.html 1.GraalVM GraalVM (ht ...
- AuthBy pg walkthrough Intermediate window
nmap └─# nmap -p- -A -sS 192.168.226.46 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-12-21 01: ...
- Hub PG walkthrough Easy
刚刚做了一个太难得简直看不懂 现在来做个简单的找回信心 nmap ┌──(root㉿kali)-[/home/ftpuserr] └─# nmap -p- -A 192.168.132.25 Star ...
- ffmpeg简易播放器(4)--使用SDL播放音频
SDL(英语:Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发函数库,使用C语言写成.SDL提供了数种控制图像.声音.输出入的函数,让开发者只要用相同或是相似的代码 ...
- uni-app之页面跳转(点击按钮进行页面跳转)
001==>点击按钮进行页面跳转 <view class="" @tap="gotoLunBo"> 去轮播页 </view> // ...
- AI赋能软件测试:未来已来,你准备好了吗?
ps:文末有福利领取哦 引言 在数字化转型的浪潮中,软件测试作为保障产品质量的关键环节,正面临着前所未有的挑战. 传统的测试方法已难以满足快速迭代和复杂场景的需求,而人工智能(AI)的引入,则为软件测 ...
- 恭喜我同事的论文被IEEE HPCC收录!
近日,由天翼云科技有限公司云网产品事业部天玑实验室撰写的<关于公有云区分负载QoS感知的内存资源动态超分管理优化>(Thoth:Provisioning Overcommitted Mem ...