使用Tesseract进行图片文字识别
Tesseract介绍
Tesseract 是一个开源的光学字符识别(OCR)引擎,最初由 HP 在 1985 年至 1995 年间开发,后来被 Google 收购并开源。Tesseract 支持多种语言的文本识别,能够识别图片中的文字,并将其转换为可编辑和可搜索的数据格式。它适用于多种应用场景,包括文档扫描、图像处理、数字存档等。
Tesseract 的最新版本显著提高了识别准确率,支持的文件格式包括 TIFF、JPEG、PNG 等常见图片格式。此外,Tesseract 还提供了一个命令行工具,允许用户通过简单的命令行输入来执行 OCR 任务。对于开发者而言,Tesseract 提供了多种编程语言的 API 接口,如 C++、Python、Java 等,使得集成 OCR 功能到各种应用程序中变得更为容易。
除了基本的 OCR 功能外,Tesseract 还支持语言模型和训练工具,允许用户根据特定需求训练自定义模型,以提高某些特定类型或格式文本的识别准确率。这些特性使得 Tesseract 成为了一个强大而灵活的 OCR 工具,广泛应用于个人和企业的文本数字化处理中。
GitHub地址:https://github.com/tesseract-ocr/tesseract
官方文档地址:https://tesseract-ocr.github.io

下载安装Tesseract
下载Tesseract
Home · UB-Mannheim/tesseract Wiki

安装的时候,记得选上中文语言包:

输入
tesseract -v
查看Tesseract是否安装成功

设置环境变量:
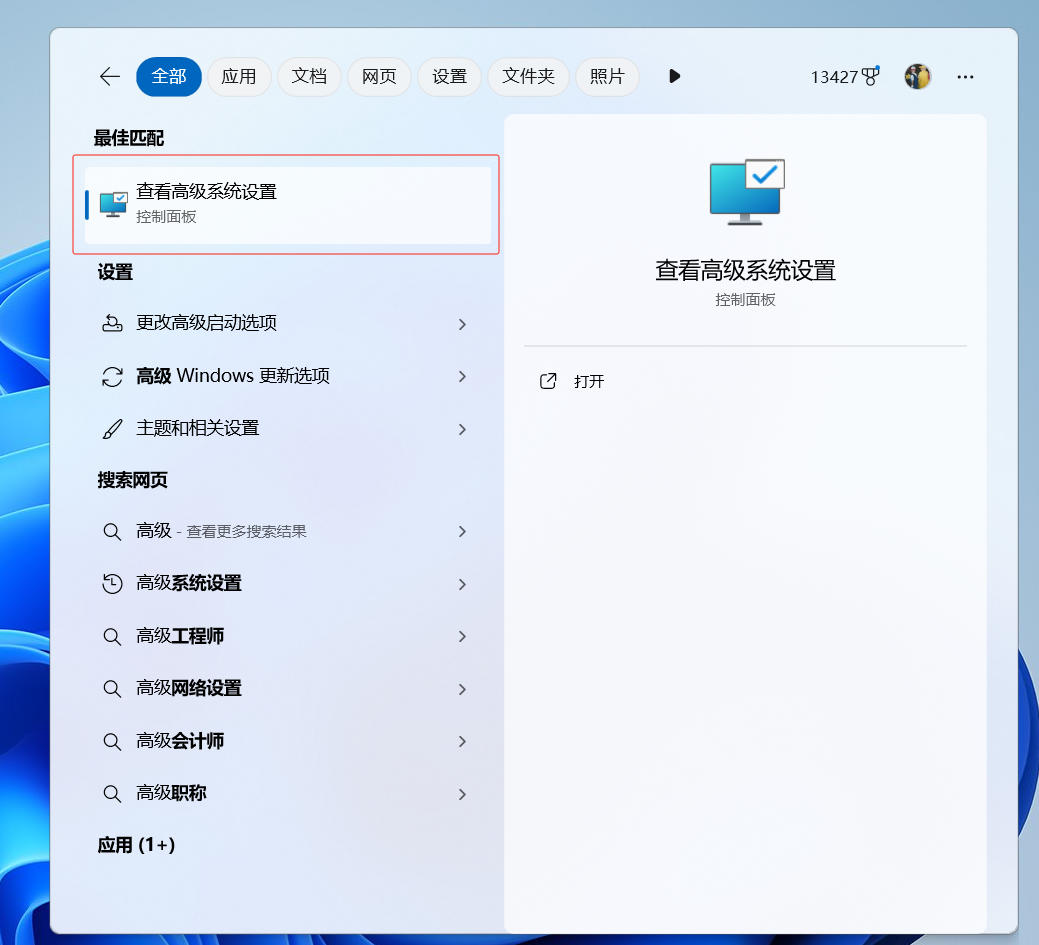
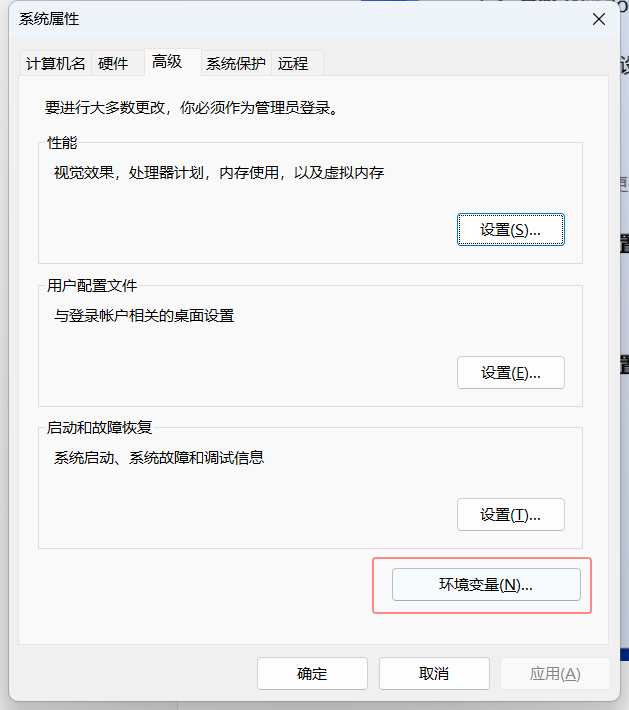
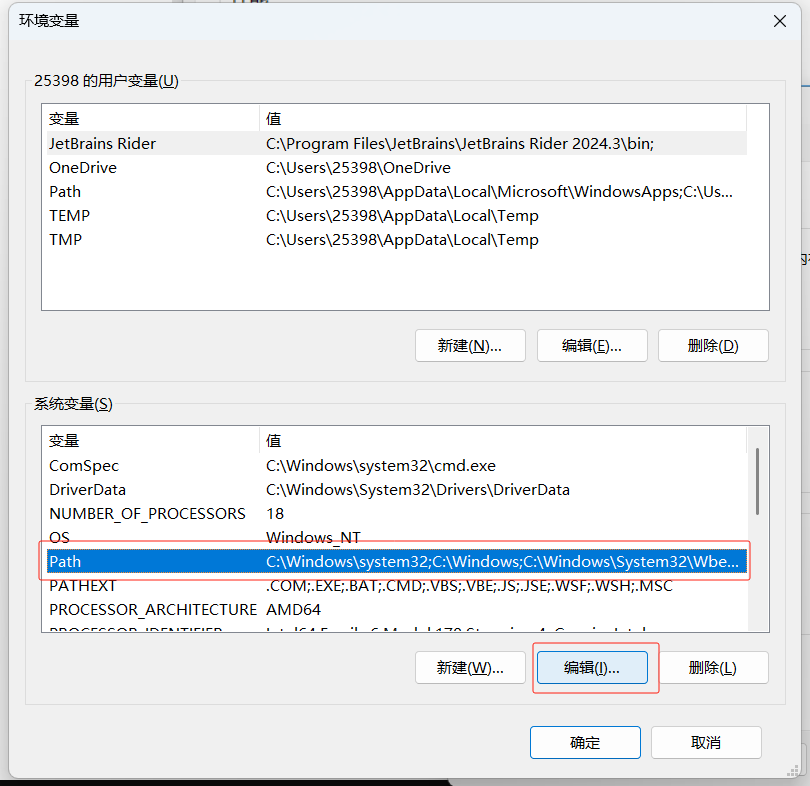
输入Tesseract的安装地址:
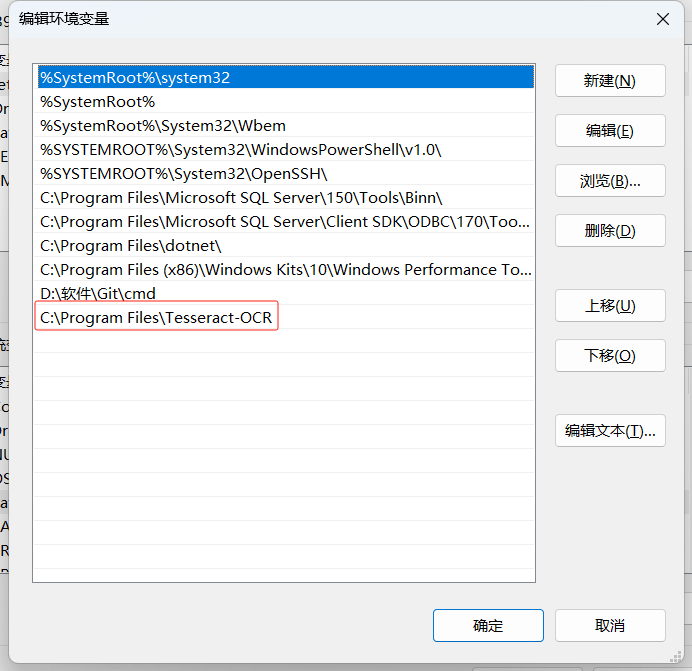
注意安装路径最好不要包含中文,由于C盘空间还比较充足,我就装在默认位置了。
再次验证安装是否完成:
tesseract -v
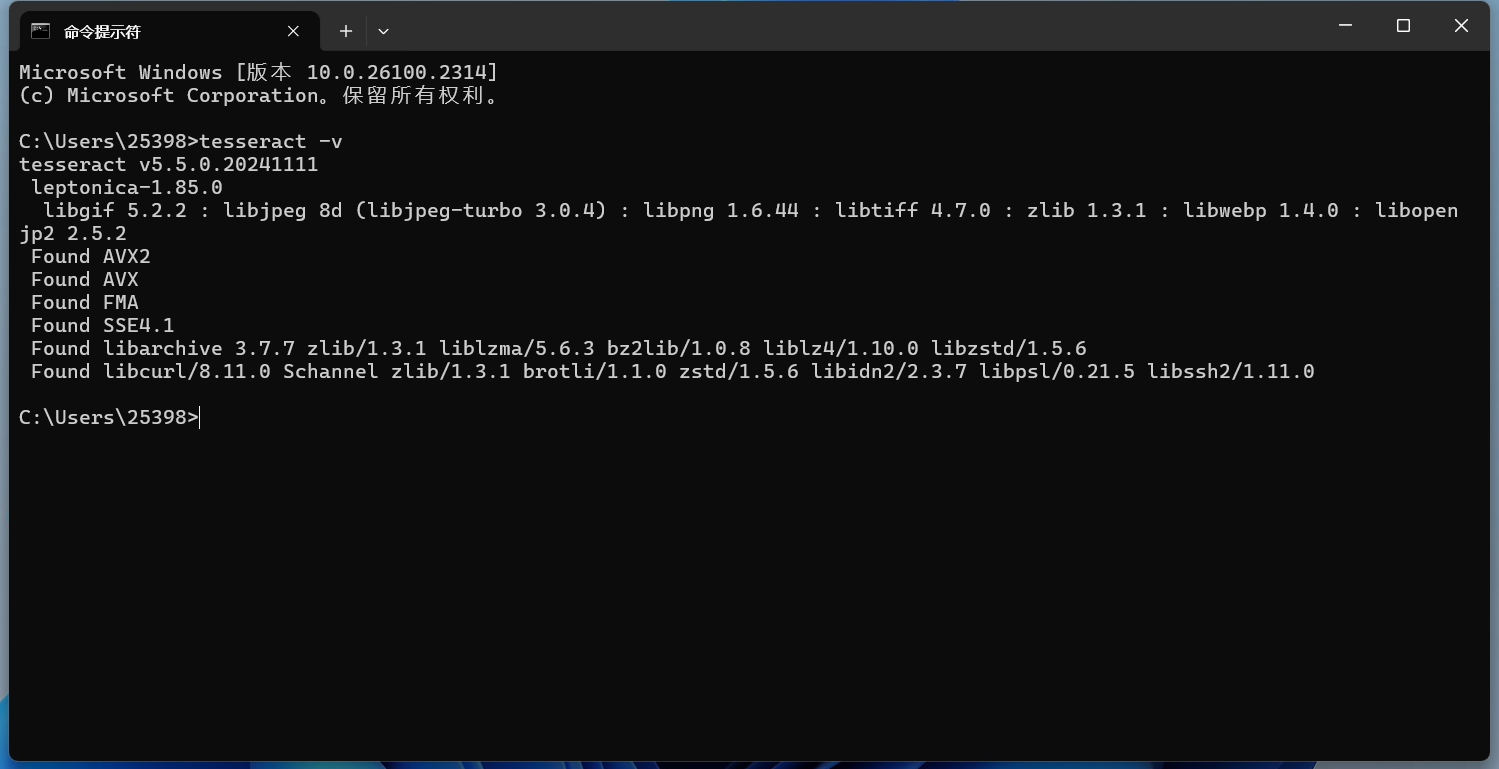
安装成功完成。
Tesseract的基本命令行使用
基本文本识别
最简单的命令是将图片中的文本识别并输出到标准输出(屏幕):
tesseract D:\test2.png stdout
默认识别的是英文的,先拿一个英文的图片试试:

图片文字识别的效果
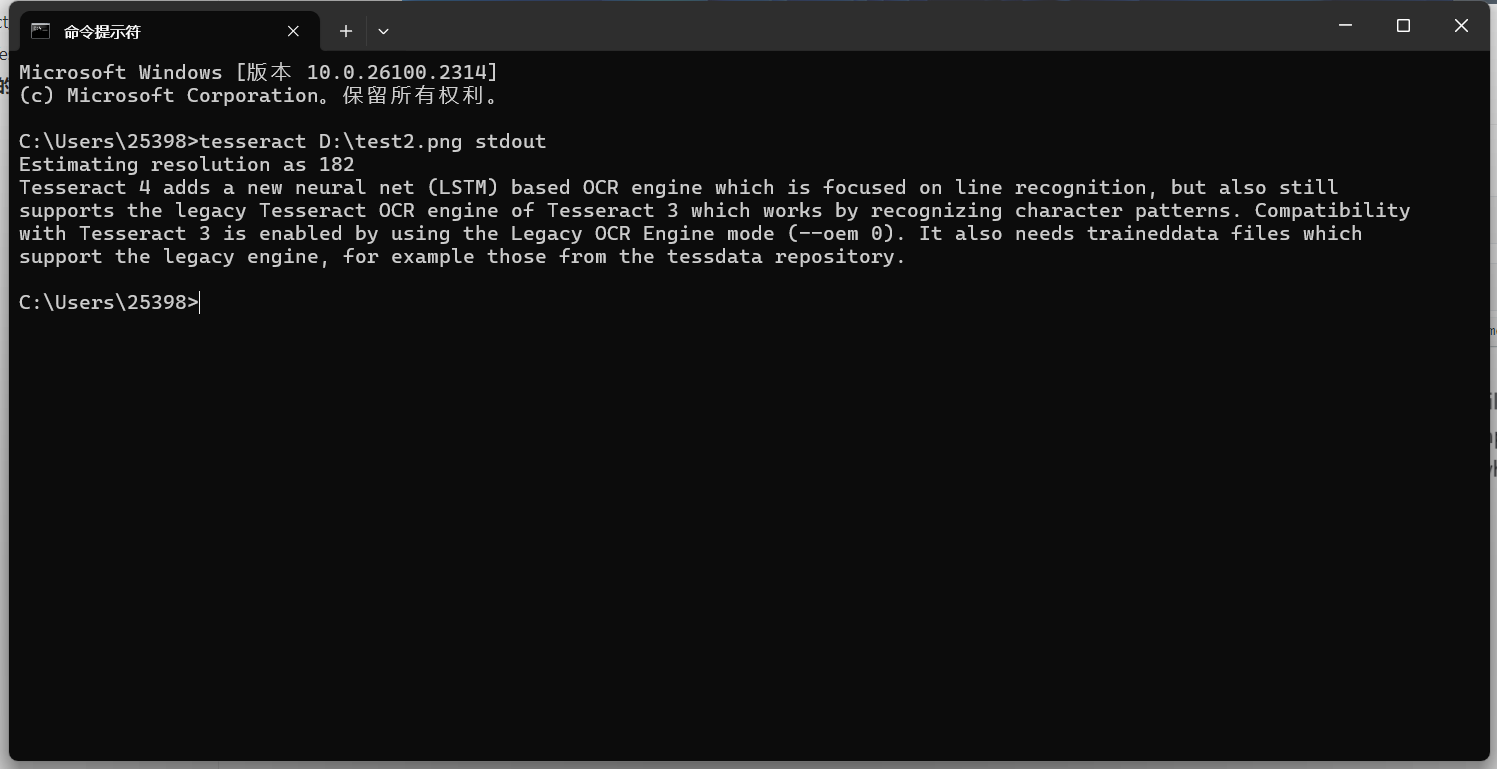
效果还是很ok的。
再试试一个中文的图片:

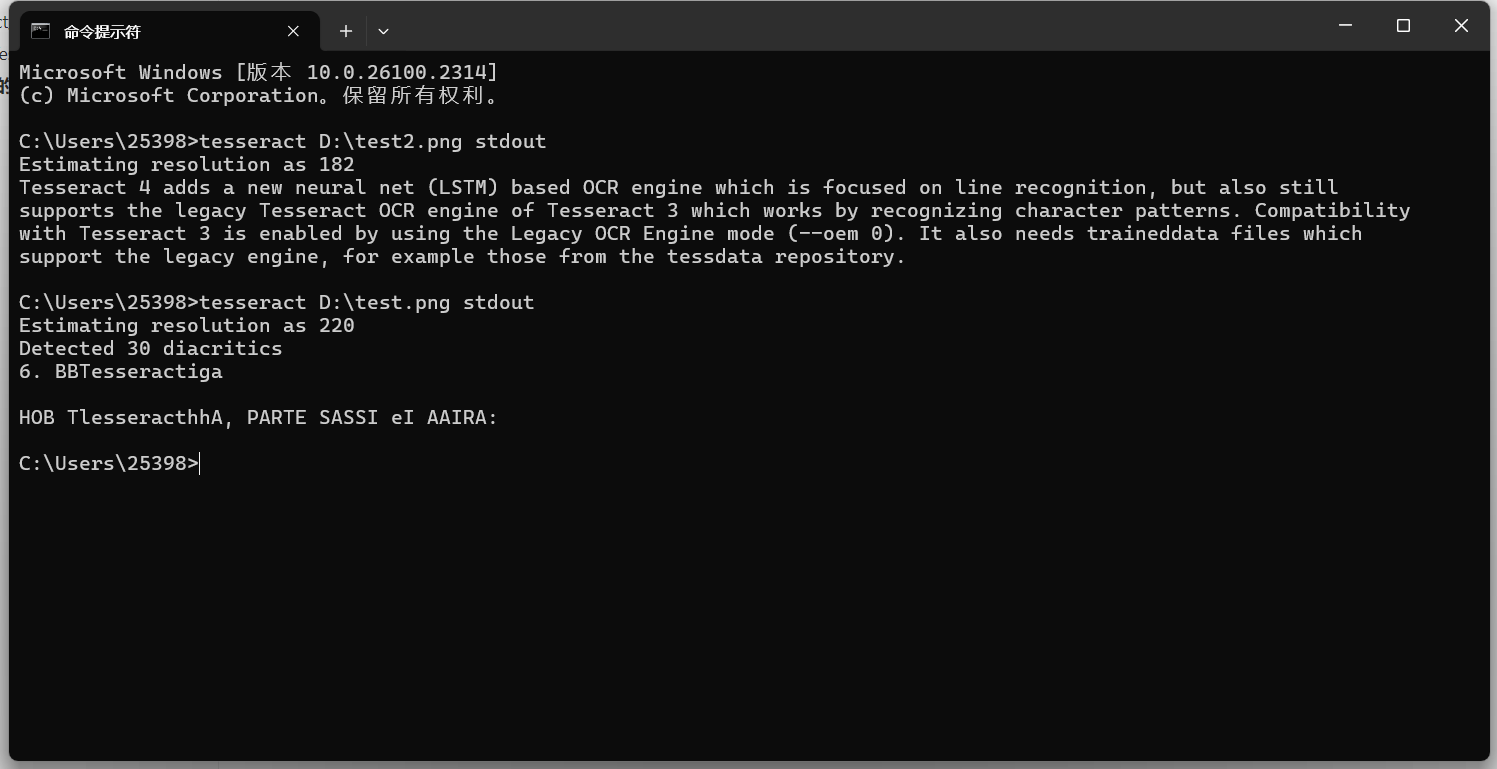
默认是无法识别中文的,这时候需要指定语言才行。
指定一种语言识别
如果图片中的文字不是英文,你需要指定相应的语言。Tesseract 支持多种语言,可以通过以下命令查看支持的语言:
tesseract --list-langs
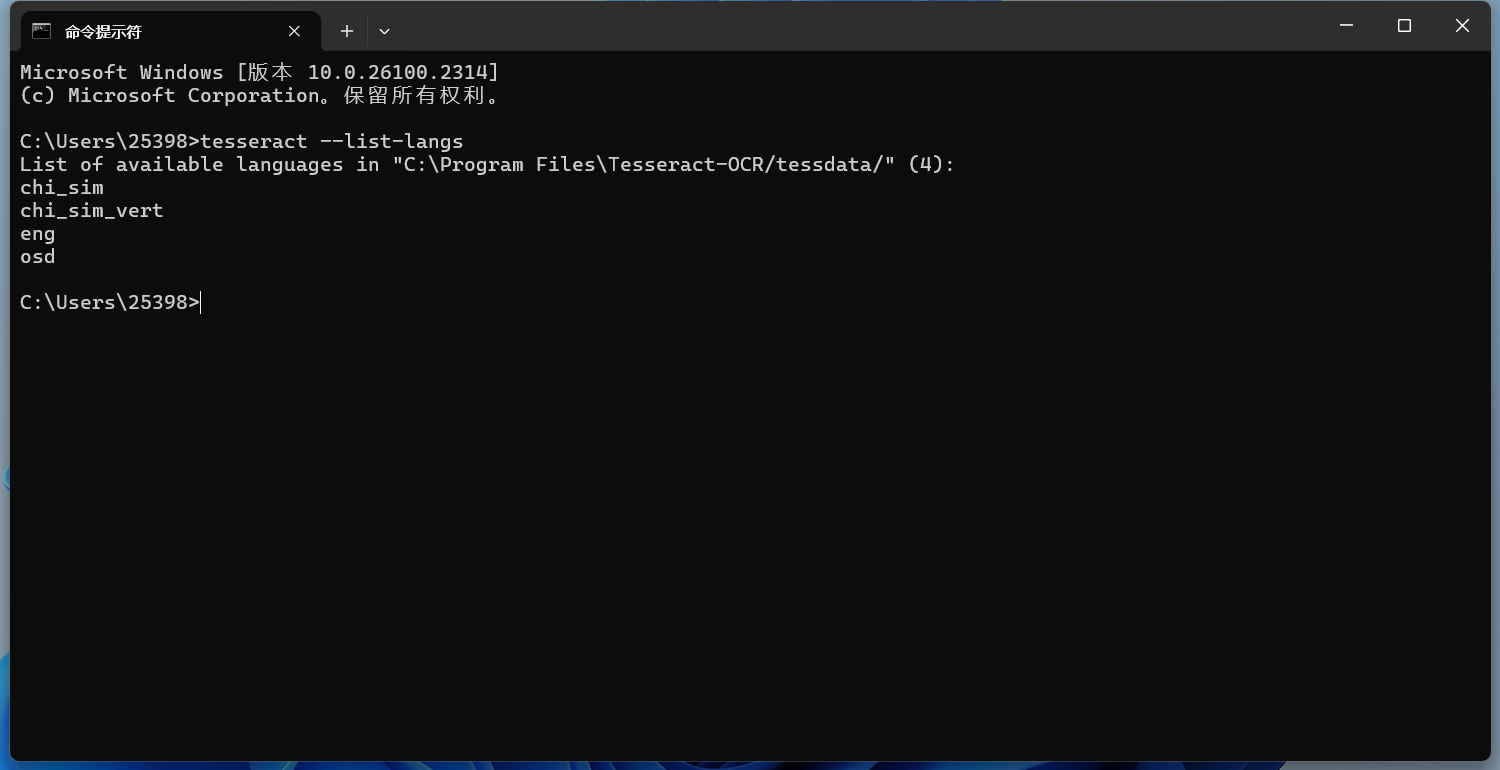
会出现你已经下载了语言包的语言。
指定语言的命令如下(例如,识别中文):
tesseract D:\test.png stdout -l chi_sim
这里的 -l chi_sim 表示使用简体中文语言模型。
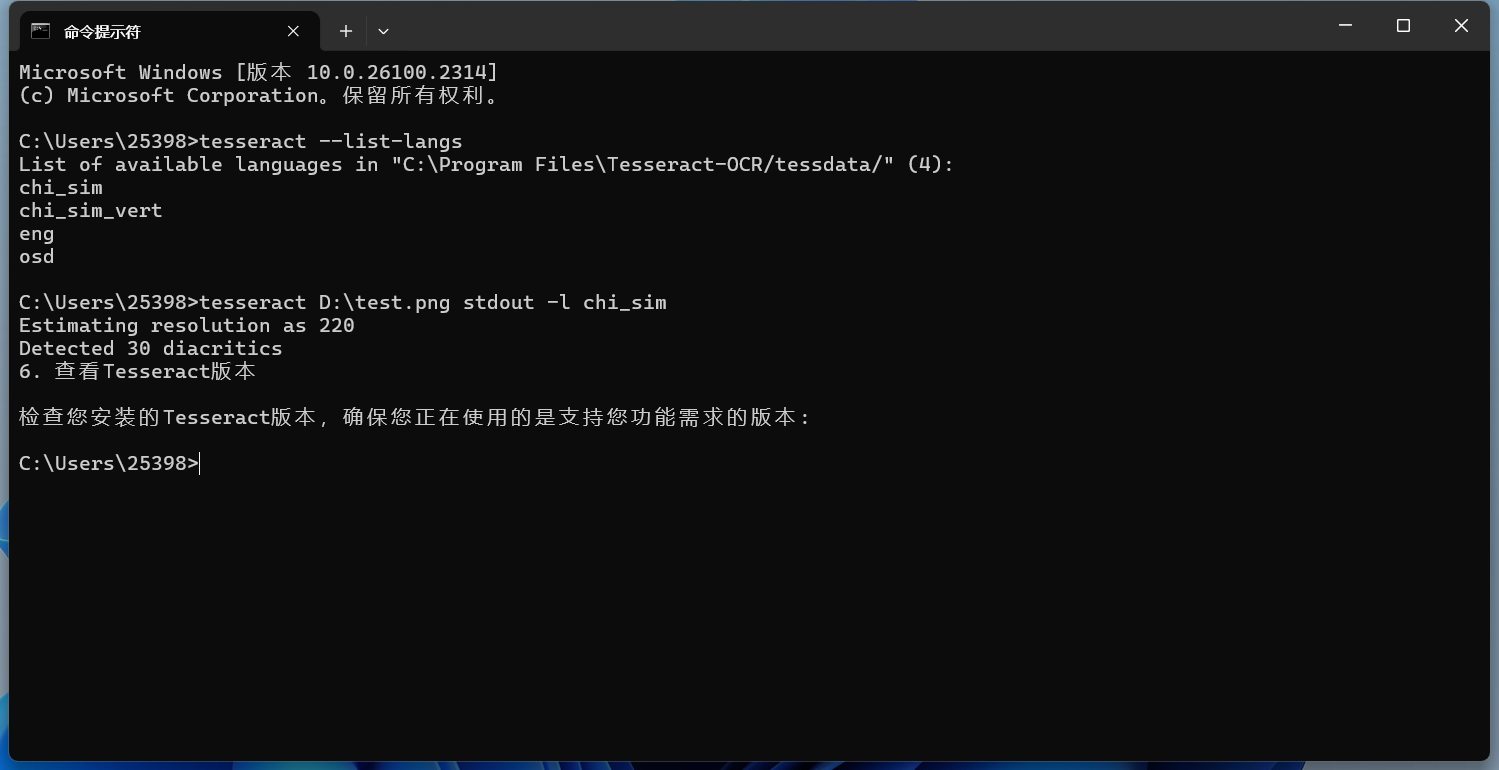
效果也很不错。
指定多种语言识别
有时候我们需要同时识别多种语言,以下面这张图片为例:

在命令行中添加-l LANG[+LANG]可以使用多种语言进行识别:
tesseract D:\test3.png stdout -l eng+chi_sim
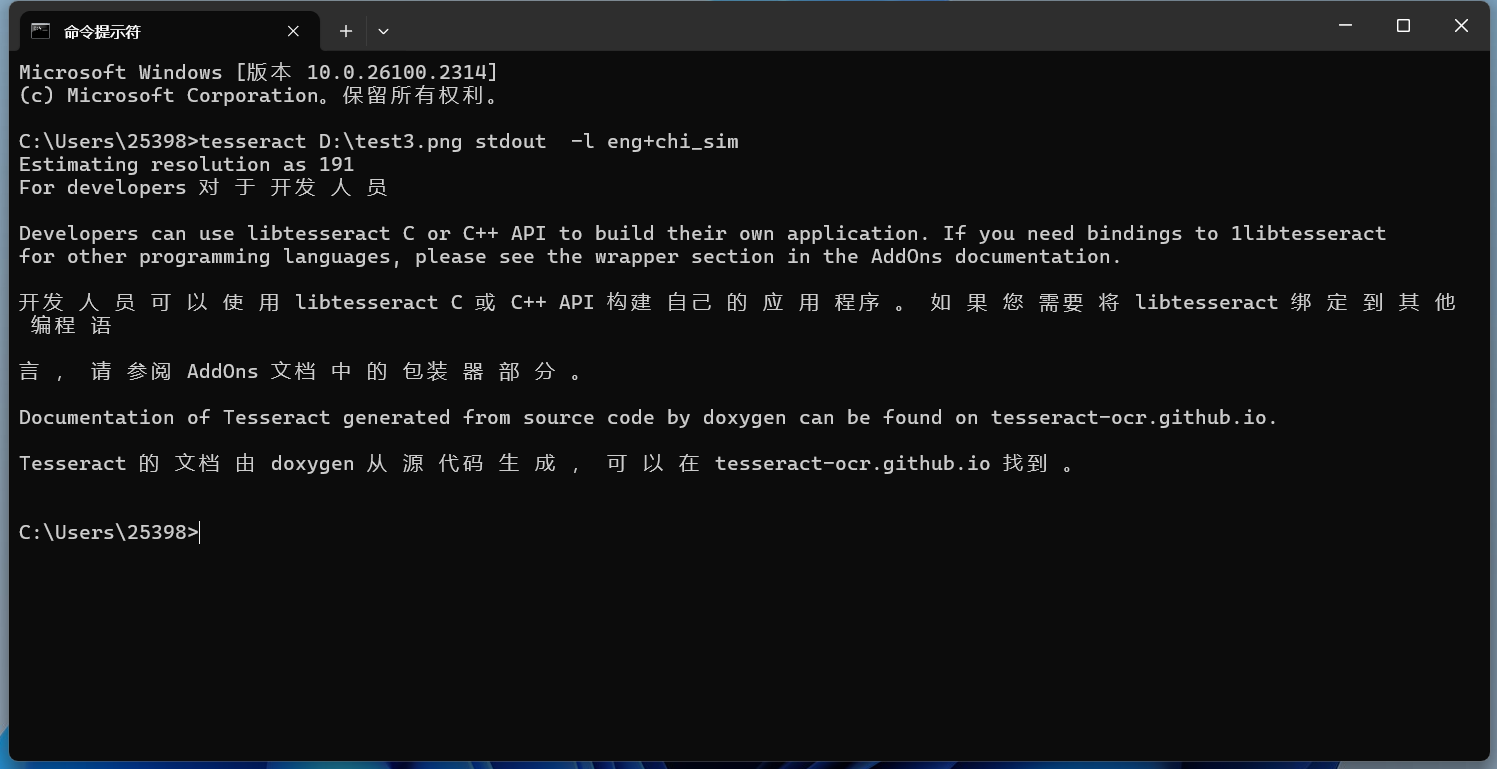
效果也还行。但是会发现识别的中文很多地方都有空格。
将中文改为主要识别语言:
tesseract D:\test3.png stdout -l chi_sim+eng
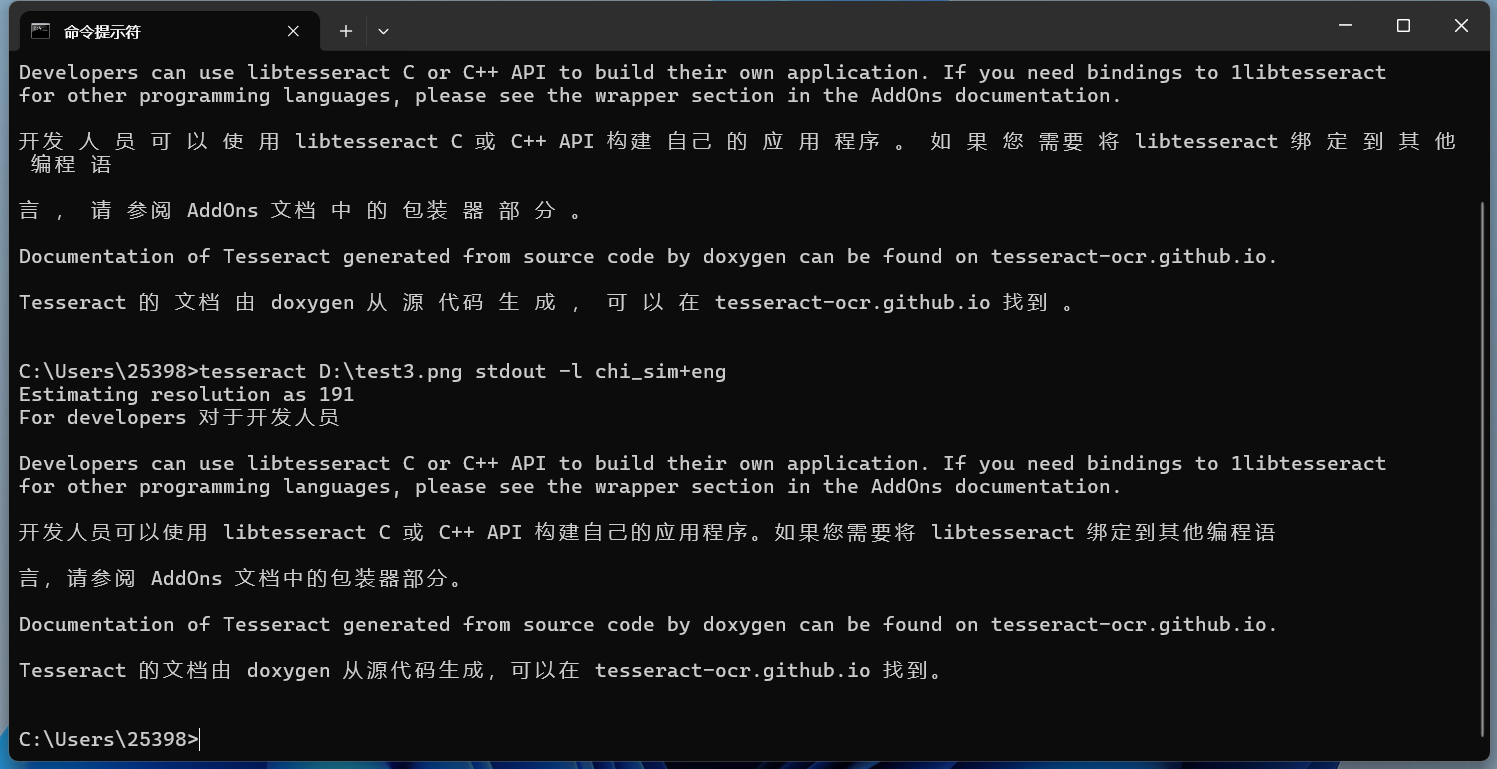
可以发现识别的空格少了很多。
保存识别文本到文件
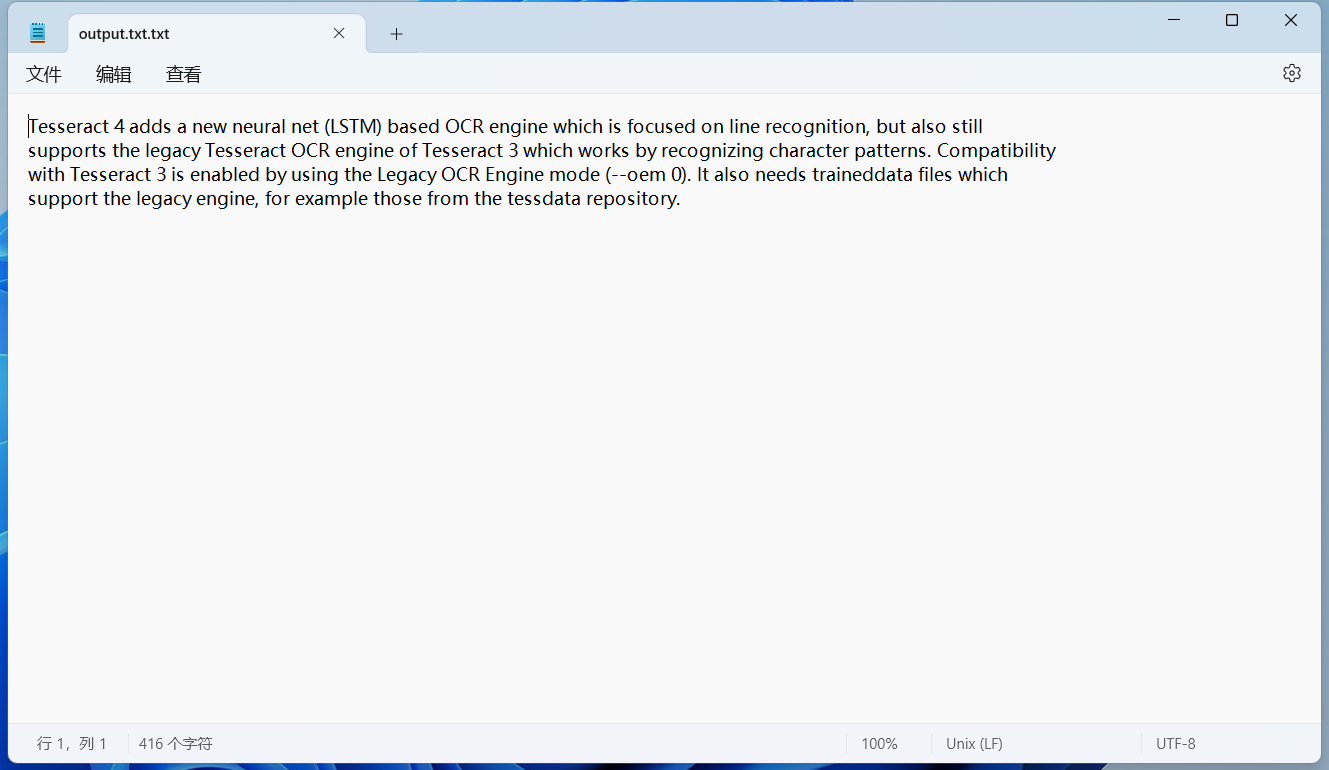
也可以把识别的内容保存在一个txt文件中,命令如下所示:
tesseract D:\test2.png D:\output.txt
使用quiet模式抑制消息
不使用quiet模式与使用quiet模式的对比:
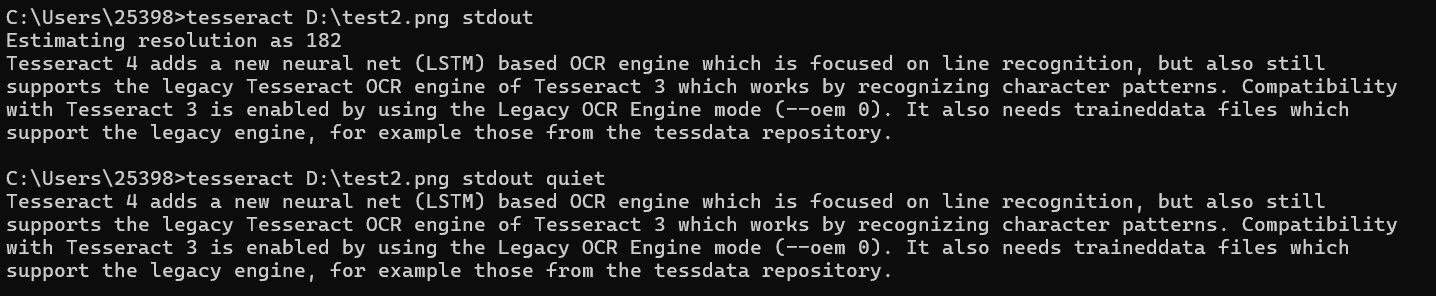
少了表示 Tesseract 正在尝试估算输入图像的分辨率的信息Estimating resolution as 182。
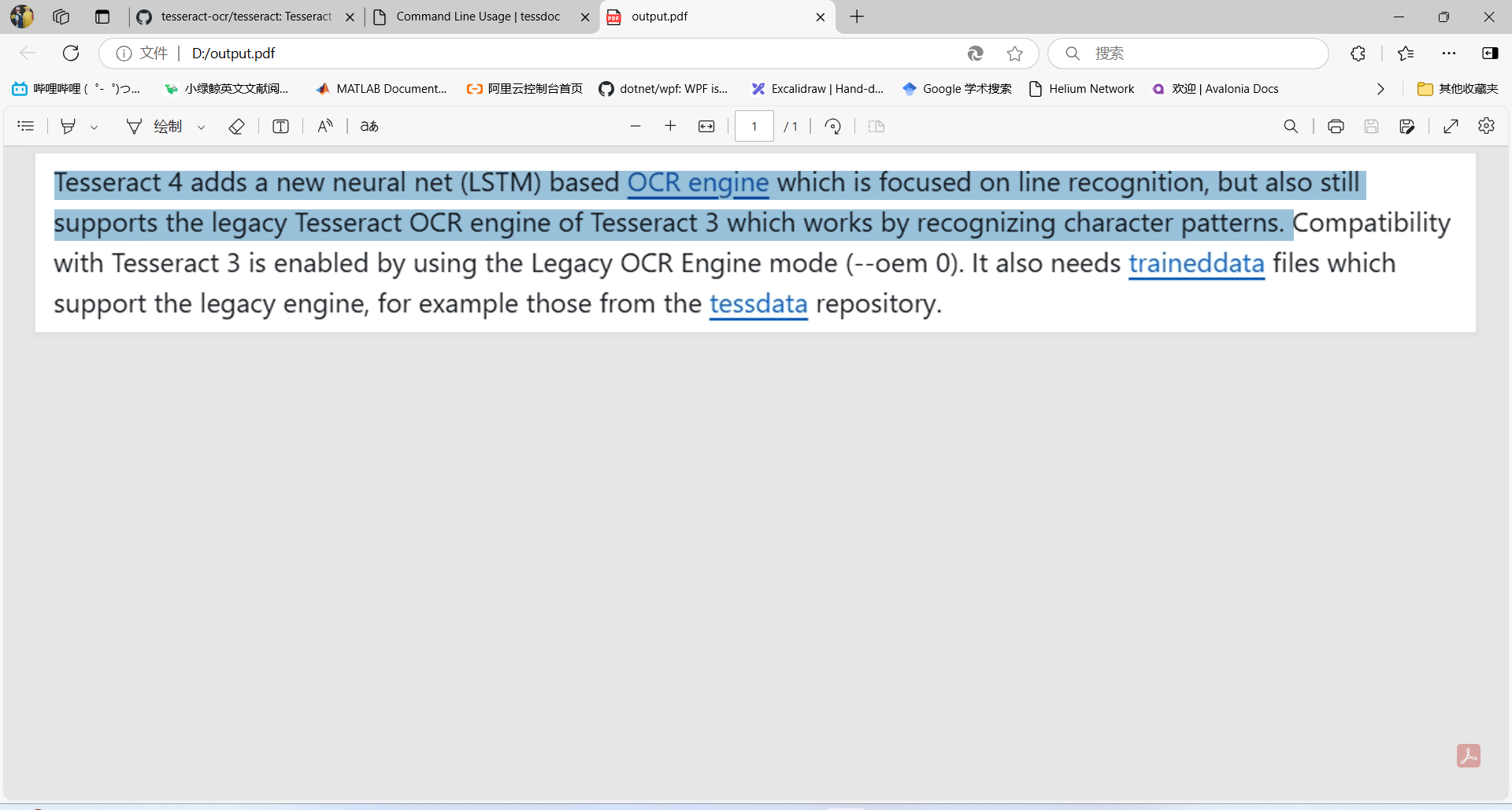
可搜索的pdf输出
这将创建一个包含图像和单独可搜索文本层的PDF,其中包含识别出的文本:
tesseract D:\test2.png D:\output -l eng pdf
实现效果:
HOCR输出
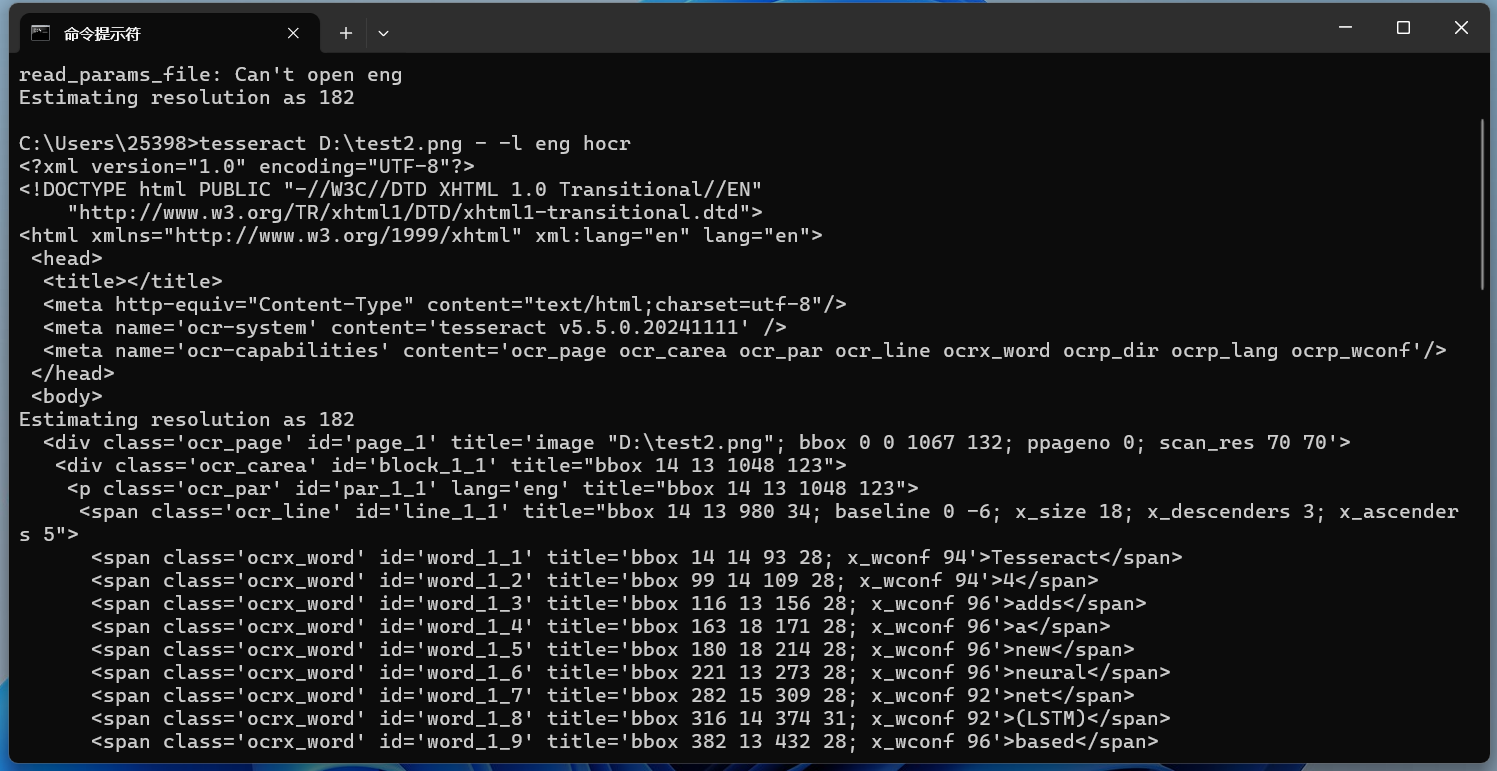
在命令末尾添加hocr以使用‘hocr’配置文件,获取HOCR输出:
tesseract D:\test2.png - -l eng hocr
识别效果:
这样不够直观,保存在一个html文件中,然后再打开看看:
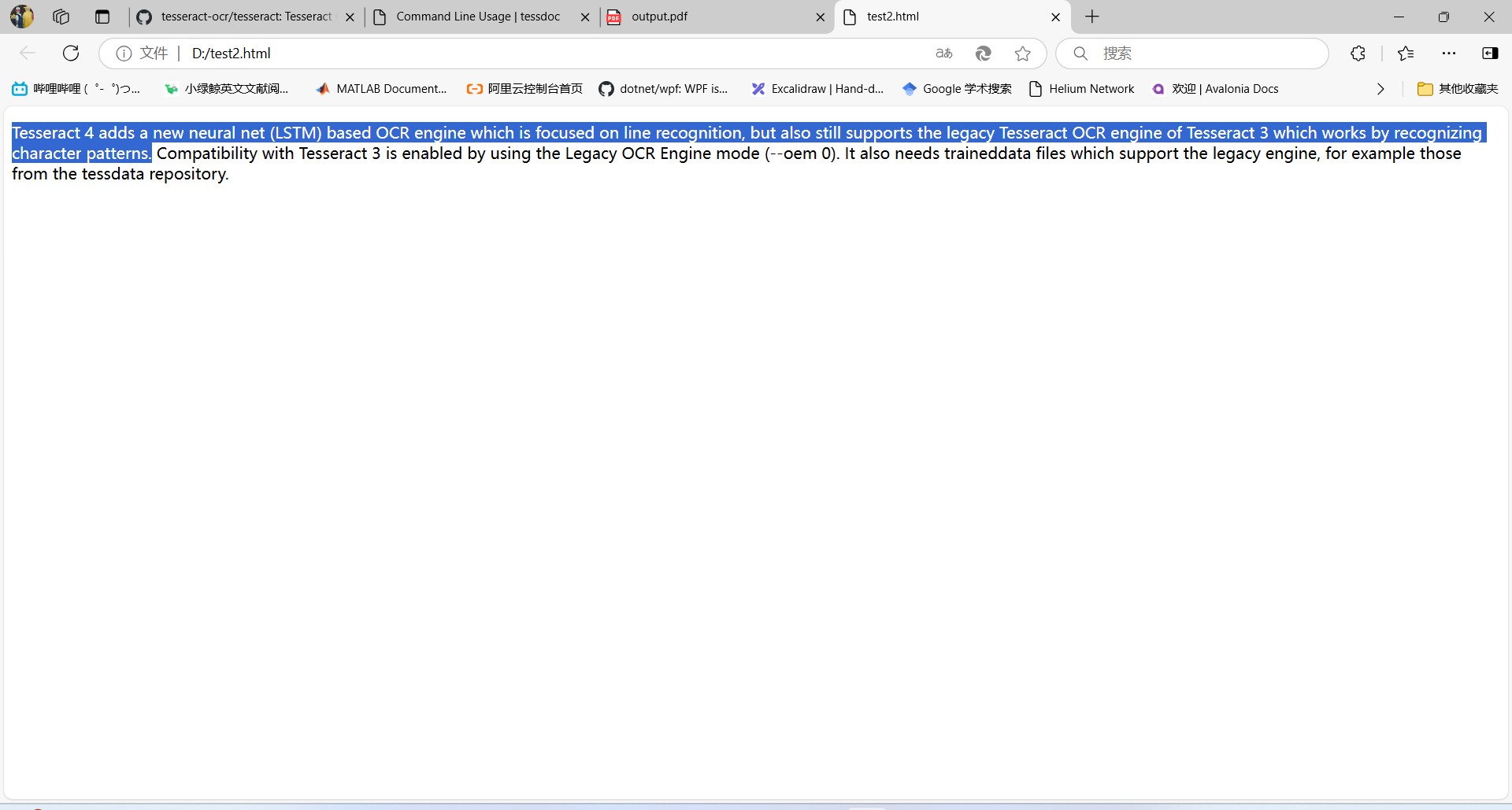
tesseract D:\test2.png D:\test2.html -l eng hocr
把生成的文件后缀改为.html,用浏览器打开,效果如下所示:
TSV输出
在命令末尾添加“tsv”配置文件以获取TSV输出:
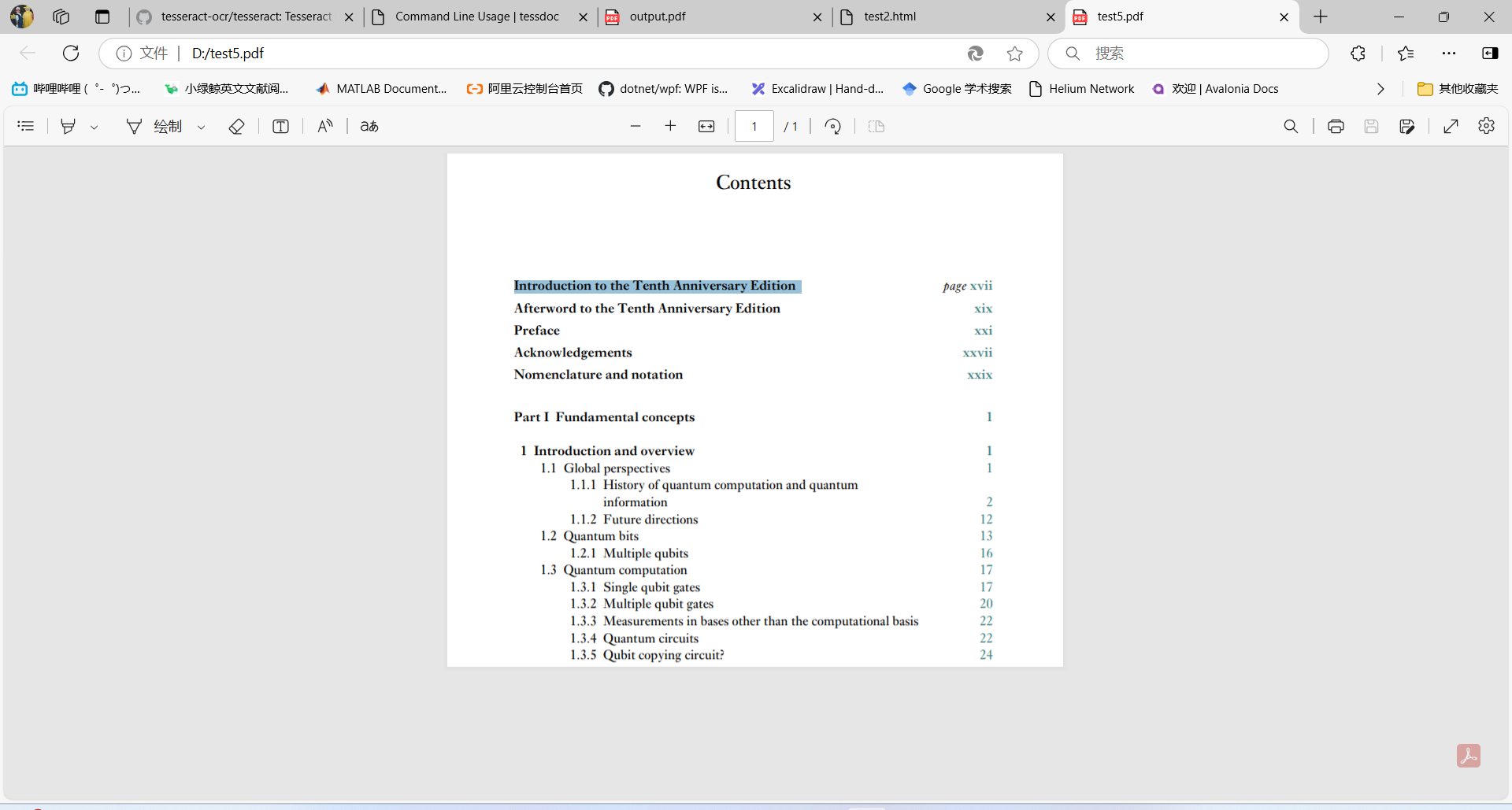
tesseract D:\test5.jpg - -l chi_sim tsv
以这张图片为例:
实现效果如下所示:
使用不同的页面分割模式
-psm 3 - 全自动页面分割,但无方向和脚本检测。(默认)
以这张图片为例:

tesseract D:\test4.png - --psm 3
实现的效果:
-psm 6 - 假定文本为一个整体均匀的块。
以这张图片为例:

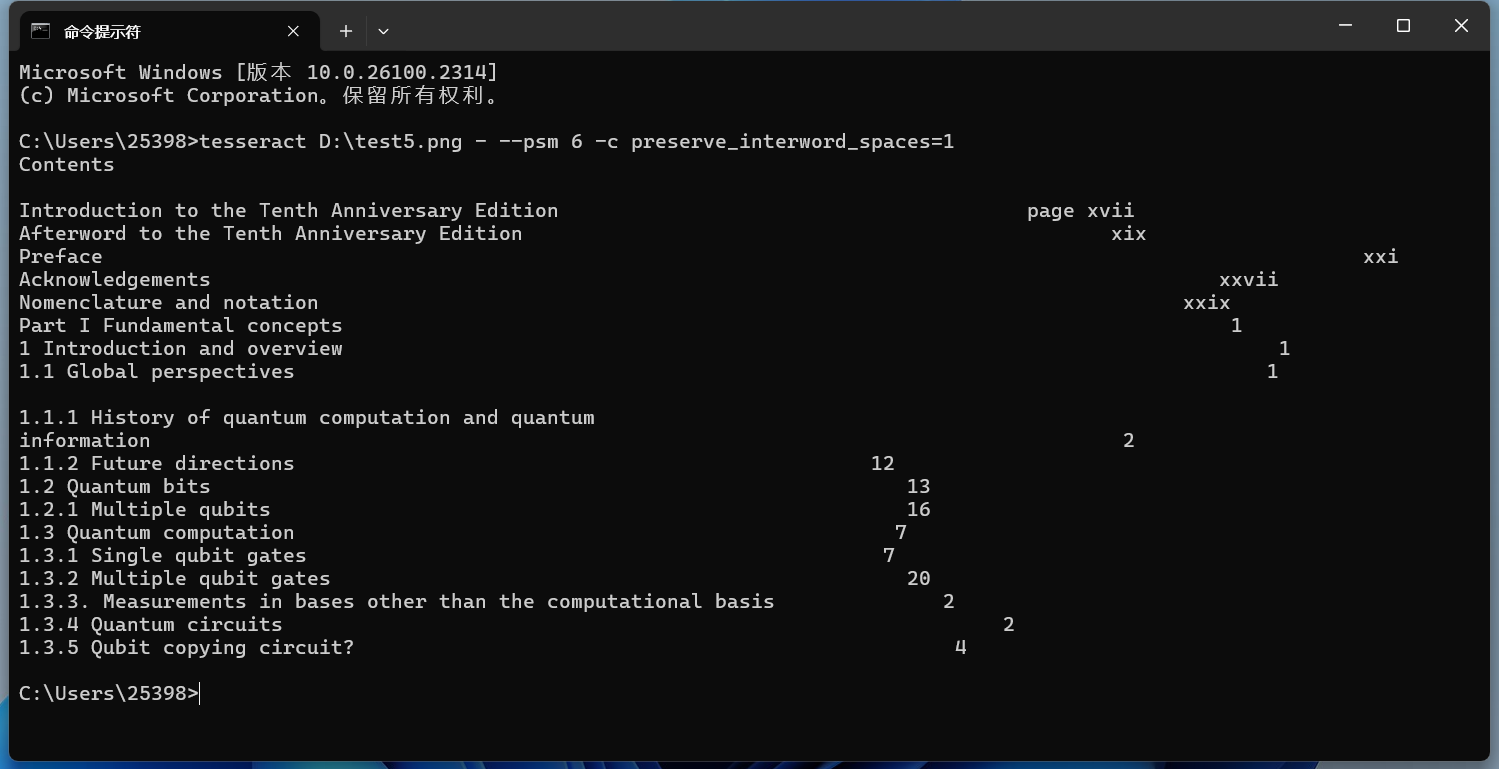
tesseract D:\test5.png - --psm 6
实现效果如下所示:
使用 -c preserve_interword_spaces=1 来保留空格
tesseract D:\test5.png - --psm 6 -c preserve_interword_spaces=1
实现效果如下所示:
使用pdftotext保持文本输出的布局
tesseract D:\test5.png D:\test5 -l eng –psm 11 pdf
实现的效果:
总结
现在图片文字识别已经有多种方式可以实现,也可以通过云服务商的文字识别服务,缺点就是需要网络,数量多了需要收费,优点就是识别准确率比较高。使用Tesseract与PaddleOCR这种方式的好处就是离线可用,速度也挺快的。还有一种目前还没试过的方式,就是使用多模态的大语言模型,缺点可能就是如果使用大模型服务提供商会比较耗费token,自己本地用ollama又比较吃配置相对于Tesseract与PaddleOCR而言,还有就是多模态大语言模型可能自己会出现一些别的内容。
之前写过几篇关于PaddleOCR的文章,感兴趣也可以阅读:
使用Tesseract进行图片文字识别的更多相关文章
- 基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[l ...
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
- java 图片文字识别 ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的 ...
- JAVA的图片文字识别技术
从2013年的记录看,JAVA中图片文字识别技术大部分采用ORC的tesseract的软件功能,后来渐渐开放了java-api调用接口. 图片文字识别技术,还是采用训练的方法.并未从根本上解决图片与文 ...
- 小试Office OneNote 2010的图片文字识别功能(OCR)
原文:小试Office OneNote 2010的图片文字识别功能(OCR) 自Office 2003以来,OneNote就成为了我电脑中必不可少的软件,它集各种创新功能于一身,可方便的记录下各种类型 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
- python3 图片文字识别
最近用到了图片文字识别这个功能,从网上搜查了一下,决定利用百度的文字识别接口.通过测试发现文字识别率还可以.下面就测试过程简要说明一下 1.注册用户 链接:https://login.bce.baid ...
- 刚破了潘金莲的身份信息(图片文字识别),win7、win10实测可用(免费下载)
刚破了潘金莲的身份信息(图片文字识别),win7.win10实测可用 效果如下: 证照,车牌.身份证.名片.营业执照 等图片文字均可识别 电脑版 本人出品 大小1.3MB 下载地址:https://p ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
随机推荐
- SimCLR: 一种视觉表征对比学习的简单框架《A Simple Framework for Contrastive Learning of Visual Representations》(对比学习、数据增强算子组合,二次增强、投影头、实验细节很nice),好文章,值得反复看
现在是2024年5月18日,好久没好好地看论文了,最近在学在写代码+各种乱七八糟的事情,感觉要和学术前沿脱轨了(虽然本身也没在轨道上,太菜了),今天把师兄推荐的一个框架的论文看看(视觉CV领域的). ...
- Angular 18+ 高级教程 – Angular 的局限和 Github Issues
前言 Angular 绝对有很多缺陷,Issue 非常多,workaround 非常多. 我以前至少有 subscribe 超过 20 个 Issues,几年都没有 right way 处理的. An ...
- TypeScript 高级教程 – 把 TypeScript 当强类型语言使用 (第一篇)
前言 原本是想照着 TypeScript 官网 handbook 写个教程的. 但提不起那个劲... 所以呢, 还是用我自己的方式写个复习和进阶笔记就好了呗. 以前写过的 TypeScript 笔记: ...
- JavaScript – 基本语法
参考 阮一峰 – 基本语法 Switch switch 经常用来取代 else if, 因为可读性比价高, 而且通常性能也比较好. standard 长这样 const orderStatus = ' ...
- TypeScript – Get Started Advanced (Work with SystemJS)
更新 我本来想 skip 掉 bundler (webpack), 感觉单侧不需要搞那么复杂, 所以用了 TypeScript 自带的 bundle (outFile) + SystemJS. 谁知道 ...
- JAVAEE——maven安装
一.安装本地Maven 注意:检查JAVA_HOME环境变量, maven本身就是java写的,所以要求必须先安装JDK,检查本机jak环境win+r后输入cmd,然后输入java -version, ...
- Python—键盘输入input()语句
用法: 简化写法:
- ROS基础入门——实操教程
ROS基础入门--实操教程 前言 本教程实操为主,少说书.可供参考的文档中详细的记录了ROS的实操和理论,只是过于详细繁杂了,看得脑壳疼,于是做了这个笔记. Ruby Rose,放在这里相当合理 前言 ...
- std::vector 和 std::map 都支持以下比较运算符
在 C++ 标准库中,std::vector 和 std::map 都支持以下比较运算符: ==(相等运算符) !=(不等运算符) <(小于运算符) <=(小于等于运算符) >(大于 ...
- EDGE 浏览器占用内存优化
windows + s 搜索 service 打开服务 : 找到下面 edge 三项 双击 把启动类型都改成 手动触发