CUDA 编程学习 (5)——内存访问性能
1. DRAM 带宽
1.1 DRAM 核心阵列结构
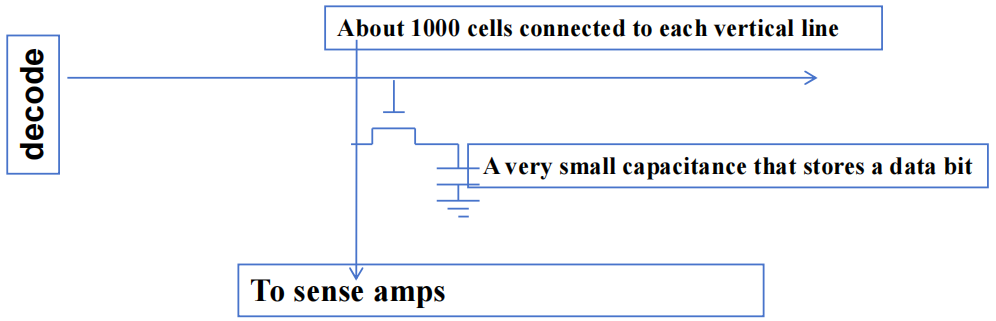
- 每个 DRAM 核心阵列约有 \(16M\) bits
- 每个 bits 存储在由一个晶体管组成的微小电容器中
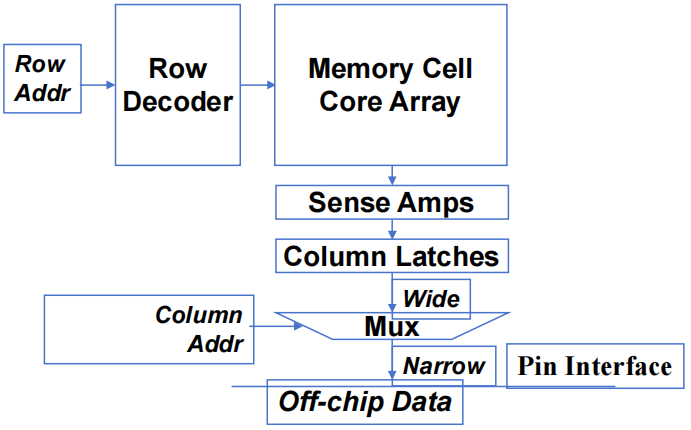
- 超小型(8x2-bit)DRAM 内核阵列
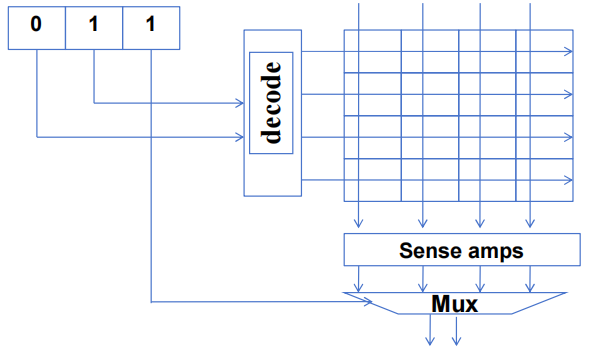
1.2 DRAM 核心阵列速度慢
从核心阵列单元读取数据的过程非常缓慢
DDR:Core speed = \(\frac{1}{2}\) interface speed
DDR2 / GDDR3:Core speed = \(\frac{1}{4}\) interface speed
DDR3 / GDDR4:Core speed = \(\frac{1}{8}\) interface speed
\(\cdots\) 之后可能会更糟
1.3 DRAM Bursting
- 对于 DDR{2,3} SDRAM 内核,时钟频率为接口速度的 \(\frac{1}{N}\):
- 将同一行的 DRAM bits 一次性加载(\(N × interface\ width\))到内部缓冲区,然后以接口速度分 N 步传输
- DDR3 / GDDR4:\(buffer\ width = 8X\ interface\ width\)
1.3.1 DRAM Bursting Timing 示例
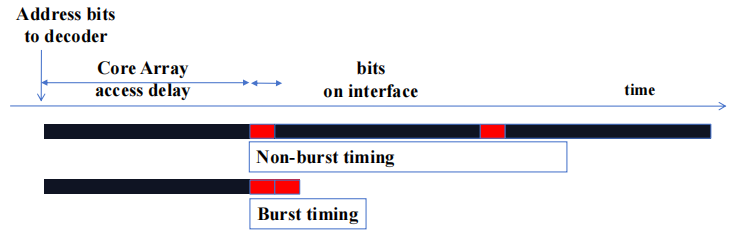
现代 DRAM 系统设计为始终以 burst 模式访问。burst bytes 被传输到处理器,但在访问非连续位置时会被丢弃。
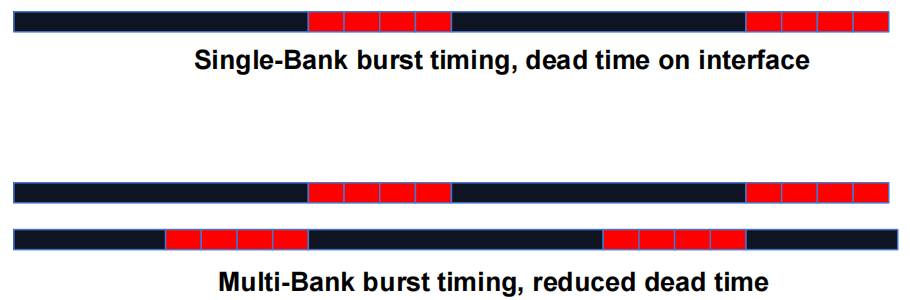
1.3.2 DRAM Bursting with Banking
- 多个 DRAM Banks 结构
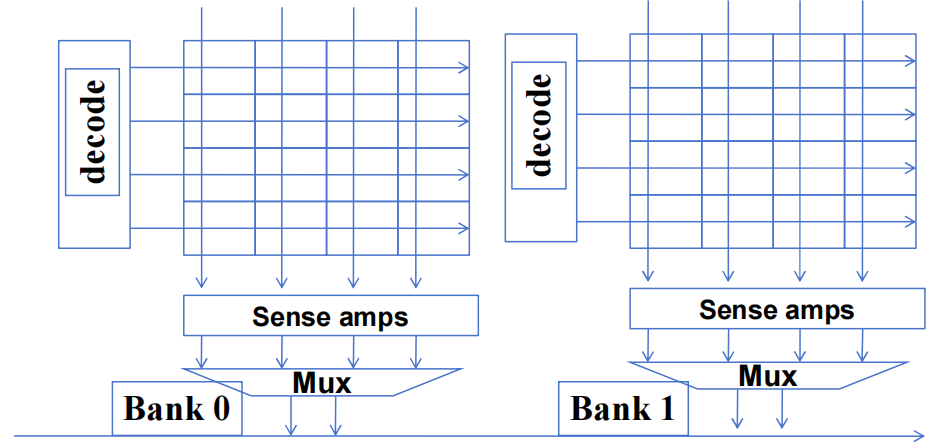
- DRAM Bursting with Banking
1.4 GPU 片外内存子系统
- NVIDIA RTX6000 GPU
- global memory 峰值带宽 = \(672GB/s\)
- global memory (GDDR6) 接口 @7GHz
- \(14\ Gbps\) 针脚速度
- 对于 GDDR6 32 位接口,我们只能维持约 \(56\ GB/s\) 的速度
- 我们需要更大的带宽(\(672\ GB/s\)), 因此需要 12 个 memory channels
2. CUDA 中的内存聚合
2.1 DRAM Burst —— 系统视图

每个地址空间被划分为 burst 段
- 每当访问一个位置时,同一 burst 段中的所有其他位置也会被传送到处理器中
基本示例如图:16-byte 地址空间,4-byte burst 段
- 实际上,我们至少有 4GB 的地址空间,burst 段大小为 128-byte 或更多
2.2 内存聚合
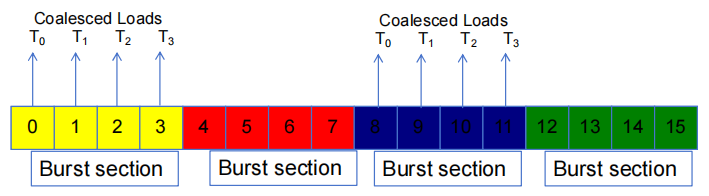
当一个 warp 中的所有 thread 都执行一个 load 指令时,如果所有被访问的位置都属于同一 burst 段,那么只会发出一个 DRAM 请求,并且访问是完全聚合的。
2.3 非聚合访问
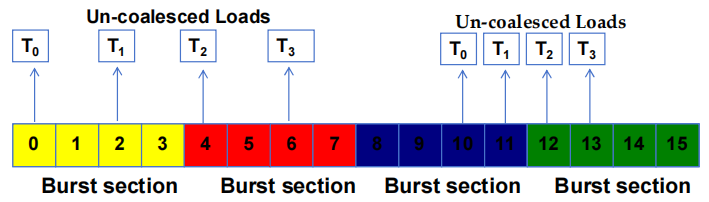
- 当被访问的位置跨越 burst 段边界时:
- 聚合失败
- 发出多个 DRAM 请求
- 访问未完全聚合
- 访问和传输的部分 bytes 未被 threads 使用
2.4 如何判断一个访问是否聚合
- 如果数组访问中的索引形式为
\]
- 线性内存空间中的二维 C 阵列(按地址递增的线性化顺序)
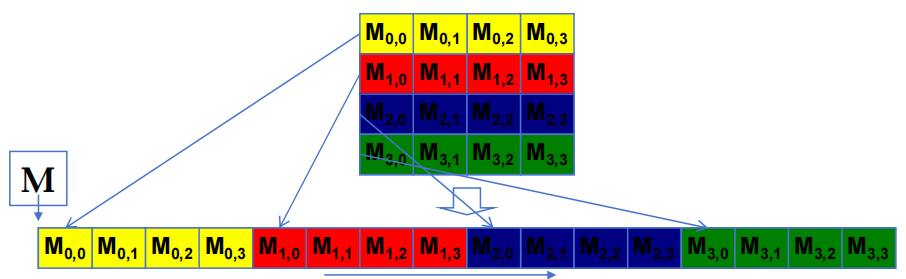
2.4.1 基本矩阵乘法的两种访问模式
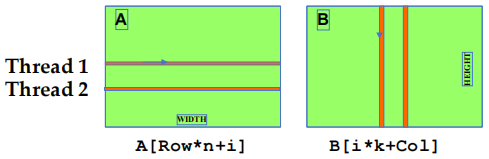
i 是 kernel code 内积循环中的循环计数器,A 大小为 \(m\times n\),B 大小为 \(n\times k\)。
\]
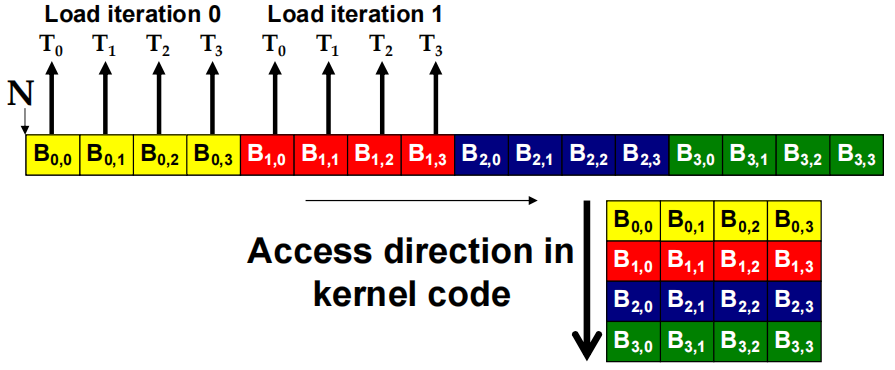
- B 访问模式是聚合的
- A 访问模式不是聚合的
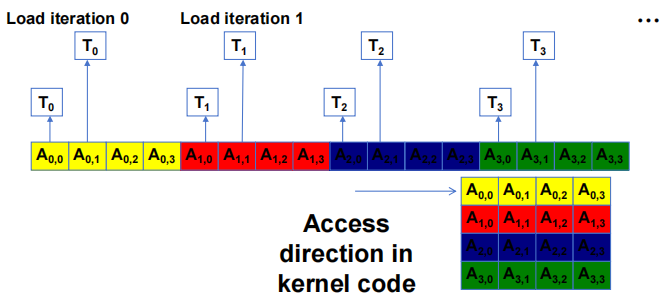
2.4.2 加载输入 tiles
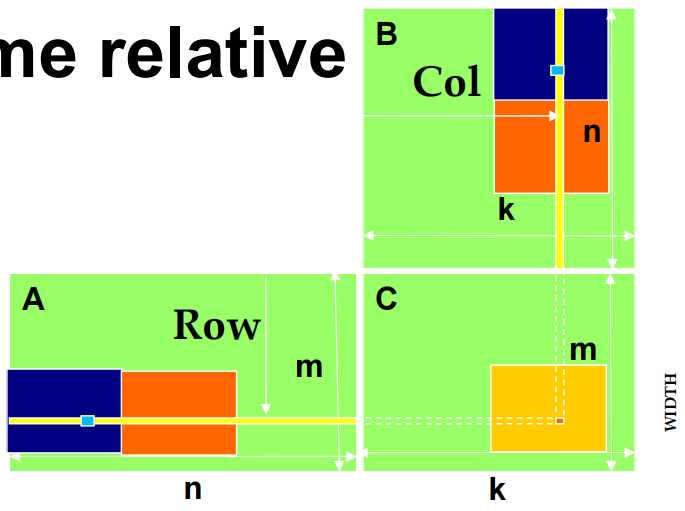
让每个 thread 在与其 C 元素相同的相对位置加载一个 A 元素和一个 B 元素。
int tx = threadIdx.xint ty = threadIdx.y
访问 tile 0 2D 索引:
A[Row][tx]B[ty][Col]
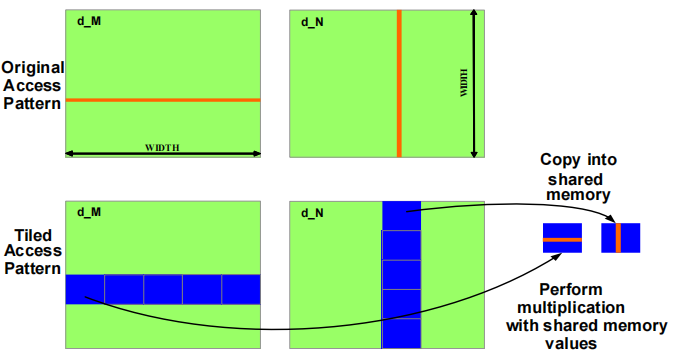
原始访问模式 (Original Access Pattern)
在左上角的 d_M 矩阵和右上角的 d_N 矩阵中,红色线条代表传统的逐元素访问方式。在这种模式下:
- 每个线程直接从全局内存中获取所需的矩阵元素,并进行计算。
- 这种访问方式可能导致频繁的全局内存访问,效率较低,因为每次访问都要从全局内存中读取数据。
分块访问模式 (Tiled Access Pattern)
在分块访问模式中:
d_M和d_N矩阵被分成多个小块(蓝色区域),每个小块会被加载到共享内存中。- 每个线程块只需要将其负责的矩阵 tile 拷贝到共享内存,然后对共享内存中的数据进行计算。
- 通过将小块 tile 加载到共享内存中,线程可以更快地重复使用共享内存中的数据,从而减少了全局内存的访问频率,提高了整体性能。
CUDA 编程学习 (5)——内存访问性能的更多相关文章
- CUDA编程学习笔记1
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作. host和device host和device是两个重要的概念 host指代CPU及其内存 device指代GPU及其内存 __globa ...
- cuda编程学习3——VectorSum
这个程序是把两个向量相加 add<<<N,1>>>(dev_a,dev_b,dev_c);//<N,1>,第一个参数N代表block的数量,第二个参数1 ...
- CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存. 主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写 设备:GPU及其 ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- cuda编程学习2——add
cudaMalloc()分配的指针有使用限制,设备指针的使用限制总结如下: 1.可以将其传递给在设备上执行的函数 2.可以在设备代码中使用其进行内存的读写操作 3.可以将其传递给在主机上执行的函数 4 ...
- cuda编程学习6——点积dot
__shared__ float cache[threadPerBlock];//声明共享内存缓冲区,__shared__ __syncthreads();//对线程块中的线程进行同步,只有都完成前面 ...
- CUDA编程学习(一)
/****c code****/ #include<stdio.h> int main() { printf("Hello world!\n); ; } /****CUDA co ...
- cuda编程学习5——波纹ripple
/共有DIM×DIM个像素,每个像素对应一个线程dim3 blocks(DIM/16,DIM/16);//2维dim3 threads(16,16);//2维kernel<<<blo ...
- cuda编程学习4——Julia
书上的例子编译会有错误,修改一下行即可. __device__ cuComplex(float a,float b):r(a),i(b){} /* ========================== ...
- cuda编程学习1——hello world!
将c程序最简单的hello world用cuda编写在GPU上执行,以下为代码: #include<iostream>using namespace std;__global__ void ...
随机推荐
- MPTCP(二):MPTCP版本说明
MPTCP版本说明 简介 参考链接 https://github.com/multipath-tcp/mptcp_net-next/wiki MPTCP的两个版本 MPTCPv0: 在5.6之前的li ...
- .NET8 Blazor 从入门到精通:(三)类库和表单
目录 Razor 类库 创建 使用 使可路由组件可从 RCL 获取 静态资源 表单 EditForm 标准输入组件 验证 HTML 表单 Razor 类库 这里只对 RCL 创建和使用的做一些简单的概 ...
- Dialog封装的消息映射(弄了好久终于弄过了,不是静态函数哦,和MFC一样,嘻嘻)
前面弄的是全局的仿消息映射,现在这是封装到类中的消息映射,一直弄不明白,现在也不太明白,就是今天在看虚函数表的用法视频时有位老师用了个共有体转化全局函数为类成员函数,这就给我指了条明路,这不今晚又来弄 ...
- chmod 使用
数字 权限 4 (100) 读 2 (010) 写 1 (001) 执行 u 表示该文件的拥有者,g 表示该文件的拥有者所属的组,o 表示其他人,a 表示所有人. e.g. # 数字表示法 chmod ...
- AI图像放大工具,图片放大无所不能
AI图像放大工具,如ESRGAN,对于提高由Stable Diffusion生成的AI图像质量至关重要.它们被广泛使用,以至于许多Stable Diffusion的图形用户界面(GUI)都内置了支持. ...
- 为什么MySQL 默认隔离级别是RR,又被阿里设置为RC
我们知道,我们可以通过这个命令查看数据库当前的隔离级别,MySQL 默认隔离级别是RR. select @@tx_isolation; ANSI/ISO SQL定义的标准隔离级别有四种,从高到底依次为 ...
- C# 泛型对象和DataTable之间的相互转换
应用场景 实际开发场景下会经常出现DataTable和List对象需要相互转换的时候,通过方法提取避免重复造轮子 List转换成DataTable 基本思路: 向DataTable里面添加新的数据内容 ...
- 痞子衡嵌入式:MCUBootUtility v6.3发布,支持获取与解析启动日志
-- 痞子衡维护的 NXP-MCUBootUtility 工具距离上一个大版本(v5.3.0)发布过去一年了,期间痞子衡也做过三个版本更新,但不足以单独介绍.这一次痞子衡为大家带来了全新重要版本v6. ...
- LinerProgression
手动实现线性回归 点击查看代码 import torch import pandas as pd import numpy as np import matplotlib.pyplot as plt ...
- Java项目笔记(五)
这里写目录标题 @Valid 失效 解析jwt 无法建立SSL连接 windows下打jar包,读取nacos 配置文件 异常 @Valid 失效 加入以下依赖 <dependency> ...