Readme 《Machine Learning by Andrew NG》
本文系列内容是吴恩达老师的机器学习公开课的文本对应。需要具备英文,微积分,线性代数,程序设计的基础。从第二周开始有编程作业,到第九周。总共8个作业。感谢吴恩达老师⸜₍๑•⌔•๑ ₎⸝
2021年9月10日 2021年12月11日。三个月学完了,得分 99.21,代码满分全部向量化实现。将近一个学期。
在自己的coursera账号的profile里出现了机器学习课程完成的标志。 如果要证书的话需要377人民币,想想也算了。这只是一个前导课程,后续更高级的是这门课 Deep Learning Specialization。有机会可以学一下。
这门课最舒畅的时候是向量化实现代码的时候。协同过滤那用了三行代码直接就过了,那种感觉非常棒!
分为11周。总共8个作业,最后一个作业是9周的。后两周没有作业。
官方的Transcript有很多的错误,语法不通,意思不通。所以我根据视频做了修正。修订工作很困难。
如果大家发现什么错误,下面评论区可以指出来。我去改。
第一周的视频的英文记录相对比较重要,他是老师授课风格,授课习惯用词,授课习惯用语的整体展现。同时,因为是第一周,很多新的领域的词语会大幅度出现,因此一个英文文本对于我们是很重要的。
如果仔细阅读了第一周的所有英文资料,那么接下来的几周,我们就有能力去面对一个纯净的英文版视频,即我们可以听着英文,来学习。当然,不懂的词还是要记下来。只不过任务繁重程度较第一周会小一些。之后的内容需要用到我们的脑子了。
有一个现象很好玩。看完一半的课程只花了不到10天。当然不是一直看。但是仅仅第一个星期的文档校对整理,和阅读,花了超过20天。
我们可以通过打印网页,缩放比145,获得纯净版的文本。没有侧边栏。

学习永不停止。
Confused
- 利用线性代数的知识,一次性求出 参数。normal equation.
- 特征缩放,是缩放输入数据,另一种是正则化参数。缩放输入数据使得他们处于同一个规模,加快梯度下降百分之速度。缩放参数是将拟合函数变得更简单,防止过拟合。老师给了很多直觉的东西,但数学上似乎还得去再看 概率论。
- 正则化参数分为线性回归模型和逻辑回归模型。这两个的代价函数还得再看看。
- 神经网络是利用多层的简单逻辑回归线性模型的组合,每层简单的逻辑回归线性模型输出一个sigmoid激活函数预测值,在01之间。输出到下一层的简单逻辑回归线性模型。形成非线性的复杂的逻辑回归。有直觉,但是为什么?
- 神经网络的代价函数并不是一个convex 函数,所以可能出现全局最优解,和局部最优解。但是逻辑回归的代价函数基本同神经网络的代价函数没什么区别。除了神经网络的预测函数是多个预测函数的复合。因此就从convex函数到了non-convex函数。有一点直觉,具体不太清楚。
- SVM, 当C=10000很大时,整个寻找最优解的过程就会更长。同时因为精度提高,会出现错误分类的情况。
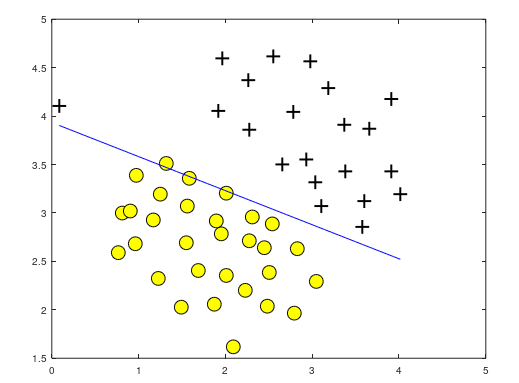
一旦θ确定,那么决策边界就确定,向量θ总是垂直于决策边界。
利用Guassian kernel扩充了θ的维度。原来可能是二维的x二维的θ,经过kernel就变成了数据量的维度,若有10000个训练样本,那么整个计算预测的过程就变成了10001维的f以及θ,1是interpretation。初步理解是扩充了项数类似增加新变量,不过整个kernel的图像又是一个正态分布,而另一个老师所讲的理解是原数据变成了一个正态分布,从数轴上凸出来了。类似一种高维映射。不太懂了。
同时课程的Trainscript等日后真的理解再做修正吧。课程网站上的应该是机器翻译,这节错误很多。 - SVM速度快,同时得到的是全局最优解。相比之下,神经网络速度会慢很多,得到的结果常常是局部最优解。当数据量特别大的时候,计算SVM的kernel会非常的困难,i.e. m=100万。这个时候用logistic regression会好很多。ppt上说,用svm的非核版本也不错。但是这里有一个线性和非线性的问题。
- 多分类问题,逻辑回归做了一个手写数据集的分类,当时是做了,但现在有点忘了。是做了10种θ吗?是线性还是非线性?(Week3 OnevsAll, 是做了10次θ的求解,每个θ是一个vector,最后放到一个matrix里了。至于线性还是非线性,逻辑回归就是线性的,但是400维的线性已经非常之复杂了。足以达到90+的正确预测率)
- SVM这周作业,spam相关用了很多正则表达式过滤各种非必要的词语。这个从python开始接触到就一直感觉特别懵。有机会得好好看看,编译原理讲的就是这个东西。
Readme 《Machine Learning by Andrew NG》的更多相关文章
- 学习笔记之Machine Learning by Andrew Ng | Stanford University | Coursera
Machine Learning by Andrew Ng | Stanford University | Coursera https://www.coursera.org/learn/machin ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念.优化目标.聚类中心等内容:特征降维包括降维的缘由.算法描述.压缩重建等内容.coursera上面Andrew NG的Mach ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- Stanford CS229 Machine Learning by Andrew Ng
CS229 Machine Learning Stanford Course by Andrew Ng Course material, problem set Matlab code written ...
随机推荐
- NVRM: Xid (PCI:0000:b1:00): 13, pid=1375637, Graphics SM Global Exception on (GPC 0, TPC 1, SM 1): Multiple Warp Errors
显卡服务器中一个显卡崩溃了: May 16 05:38:58 dell kernel: [14244871.006970] NVRM: Xid (PCI:0000:b1:00): 13, pid=13 ...
- Visual Studio 个人配置和插件
主题和字体 一般为黑色深色主题,看起来比较舒服. 字体使用Fira Code,好处就是它把 =>和!=换成更加熟悉的表示.就比如以下.缺点就是习惯之后,看别人的代码就不习惯. 插件 当然是首推R ...
- Apache DolphinScheduler 3.1.8 保姆级教程【安装、介绍、项目运用、邮箱预警设置】轻松拿捏!
概述 Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度开源系统.适用于企业级场景,提供了一个可视化操作任务.工作流和全生命周期数据处理过程的解决方案. ...
- 为什么大部分的 PHP 程序员转不了 Go 语言?
大家好,我是码农先森. 树挪死,人挪活,这个需求我做不了,换个人吧.大家都有过这种经历吧,放在编程语言身上就是 PHP 不行了,赶紧转 Go 语言吧.那转 Go 语言就真的行了?那可不见得,我个人认为 ...
- Element-UI 中使用rules验证
第一种:写在data中进行验证 <el-form>:代表这是一个表单 <el-form> -> ref:表单被引用时的名称,标识 <el-form> -> ...
- Maven 设置 JDK 版本
Maven 设置 JDK 版本是通过 Apache Maven Compiler Plugin 插件实现的.它用于编译项目的源代码. 方法一 有时候你可能需要将某个项目编译到与当前使用的 JDK 版本 ...
- diff 输出解释
diff 最原始的 diff 我们先编写两个文件: f1: 1 2 3 4 5 6 7 8 9 f2: 1 2 3 4 5 66 7 8 9 然后我们进行比较: diff f1 f2 6c6 < ...
- SQL全表扫描优化基础知识
1.模糊查询效率很低: 原因:like本身效率就比较低,应该尽量避免查询条件使用like:对于like '%...%'(全模糊)这样的条件,是无法使用索引的,全表扫描自然效率很低:另外,由于匹配算法的 ...
- 商业银行国际结算规模创新高,合合信息AI助力金融行业智能处理多版式文档
随着我国外贸新业态的快速增长,银行国际结算业务在服务实体经济发展.促进贸易投资便利化进程中发挥了越来越重要的作用.根据中国银行业协会近日发布的<中国贸易金融行业发展报告(2023-2024)&g ...
- 深度学习模型训练的过程理解(训练集、验证集、测试集、batch、iteration、epoch、单步预测、多步预测、kernels、学习率)
呜呜呜呜,感谢大佬学弟给我讲干货. 本来是讨论项目的,后面就跑偏讲论文模型了. 解答了我一直以来的疑问: 数据放模型里训练的过程. 假设我们有一个数据集26304条数据,假设设置模型读入1000条,如 ...