30分钟编写一个抓取 Unsplash 图片的 Python爬虫

PS:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步!
简易图片爬虫的组成部分
- Python (3.6.3 或者更新版本)
- Pycharm (Community edition 版本就可以)
- Requests
- Pillow
- Selenium
- Geckodriver (阅读下面的说明)
- Mozlla Firefox (如果你没有,去安装一下)
- 有效的网络连接 (显而易见的)
- 你的 30 分钟 (可能更少)
简易图片爬虫的制作
把所有东西都安装好了么?不错!跟着我们的代码,我将开始解释我们每一个爬虫原料的作用。
第一件事情,我们将 把 Selenium webdriver 和 geckodriver 结合起来去打开一个为我们工作的浏览器窗口。首先,在 Pycharm 里创建一个项目,根据你的系统下载最新的 geckodriver , 打开下载的压缩文件然后把 geckodriver 文件放到你的项目文件夹里。 Geckodriver 是 Selenium 控制 Firefox 的基础, 因此我们需要把它放到我们项目的文件夹里面,来让我们能使用浏览器。
接下来我们要做的就是在代码中导入 Selenium 的 webdriver 并且连接我们想要连接的 URL,所以让我们这样做吧:
from selenium import webdriver
# 你想打开的url地址
url = "https://unsplash.com"
# 用Selenium的webdriver去打开页面
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)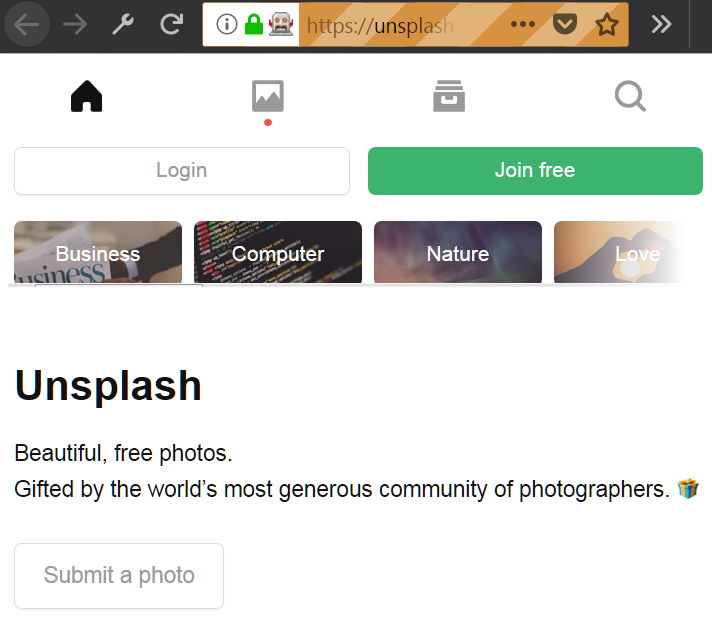
一个远程控制的 Firefox 窗口
很简单,是吧? 如果你每一步都操作正确, 你已经度过了困难的一部分,你应该看到和上面展示图片类似的浏览器窗口。
接下来,我们应该下滑页面,这样在我们下载图片之前可以加载更多的图片。我们还需要等待几秒钟,以防万一网络连接缓慢,图片加载不全。由于 Unsplash 是基于 React 构建的, 等待 5 秒钟似乎是合适的时间,因此我们使用 time 包来进行等待的操作。我们还需要使用一些 Javascript 代码来滚动页面 。
--- 我们将使用 window.scrollTo() 来完成这个。把它们放到一起, 你应该得到这样的代码:
unscrape.py
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
# 滚动页面,然后等待5秒
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)滚动页面,然后等待 5 秒
在测试上面的代码后,你应该看到浏览器向下滚动一些,下一件我们需要做的事情是在网页上找到那些我们想要下载的图片。在解析 recat 生成代码后,我发现我们能用 CSS 选择器在页面代码里面定位我们想要的图片。也许页面具体的布局和代码在未来可能会改变, 但是在我写代码的这个时候我们可以用 #gridMulti img 选择器来获取所有出现在屏幕里面的 <img> 标签元素
我们能用 find_elements_by_css_selector() 得到这些标签元素的 list 集合,但是我们想要的却是是每个标签元素的 src 的属性。所以,我们可以遍历 list 集合然后抓取它们:
unscrape.py
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
# 选择图片标签元素,打印它们的URL
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
for image_element in image_elements:
image_url = image_element.get_attribute("src")
print(image_url)选择图片标签元素,打印它们的 URL
现在,为了真正得到我们找到的图片,我们将使用 requests 包和一部分 PIL 包,即 Image。我们还需要使用 io 包里面的 BytesIO 来把图片写入一个 ./images/ 的文件夹,我们要在我们的项目文件夹里面创建这个文件。 这样,把所有东西组合在一起,我们需要给每个图片的 URL 发送一个 HTTP 的 GET 请求,然后使用 Image 和 BytesIO,我们可以在我们得到的响应里面存储图片,这里是一个方法来实现这一步骤 :
unscrape.py
import requests
import time
from selenium import webdriver
from PIL import Image
from io import BytesIO
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
i = 0
for image_element in image_elements:
image_url = image_element.get_attribute("src")
# 发送一个HTTP的GET请求,在响应里面获取并存储图片
image_object = requests.get(image_url)
image = Image.open(BytesIO(image_object.content))
image.save("./images/image" + str(i) + "." + image.format, image.format)
i += 1下载图片
下载一大堆免费的图片几乎是你的所有需求了。显而易见的,除非你想设计图片原型或者仅仅需要得到随机的图片,这个小爬虫是没有多大用处的。 因此,我花了一些时间,通过增加了更多的特性来提升它:
- 允许用户使用命令行参数来指定搜索查询的内容,同时使用滚动数值参数,这样允许页面为下载展示更多的图片。
- 可定制化的
CSS选择器。 - 根据搜索查询定制结果的文件夹。
- 根据需要裁剪缩略图的网址以获得全高清图像。
- 基于图片的 URL 给图片命名。
- 在程序结束后关闭浏览器窗口。
你可以 (也可能应该) 尝试自己去实现其中的一些功能。可用的完整版的网页爬虫 这里。 记得去单独下载 geckodriver 并将其连接到你的项目,就像文章开头说明的那样 。
限制,思考和未来的改进
这个整体项目都是一个非常简单的概念验证,来看看网页爬虫是怎么实现完成的,意味着有很多事情可以做,来改善这个小工具:
- 没有记录这些图片的原始上传者是一个很不好的主意,
Selenium是绝对有能力来做这些事情的,所以让每个图片都带着作者的名字。 Geckodriver不应该被放置在项目的文件夹内,而更应该全局安装,并成为PATH系统环境变量的一部分。- 搜索功能很容易地扩展到包括多个查询,从而可以简化下载大量图片的过程。
- 默认的浏览器可以从
Firefox变成Chrome或者甚至 PhantomJS 对这类项目来说会好很多。总结:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
30分钟编写一个抓取 Unsplash 图片的 Python爬虫的更多相关文章
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- 从urllib和urllib2基础到一个简单抓取网页图片的小爬虫
urllib最常用的两大功能(个人理解urllib用于辅助urllib2) 1.urllib.urlopen() 2. urllib.urlencode() #适当的编码,可用于后面的post提交 ...
- 30 分钟编写一个 Flask 应用
Flask 是一种很赞的Python web框架.它极小,简单,最棒的是它很容易学. 今天我来带你搭建你的第一个Flask web应用!和官方教程 一样,你将搭建你自己的微博客系统:Flaskr.和官 ...
- PHP抓取远程图片教程(包含不带后缀图片)
之前做微信登录开发时候,发现微信头像图片没有后缀名,传统的图片抓取方式不奏效,需要特殊的抓取处理.所以,后来将各种情况结合起来,封装成一个类,分享出来. 创建项目 作为演示,我们在www根目录创建项目 ...
- php远程抓取网站图片并保存
以前看到网上别人说写程序抓取网页图片的,感觉挺神奇,心想什么时候我自己也写一个抓取图片的方法! 刚好这两天没什么事,就参考了网上一个php抓取图片代码,重点借鉴了 匹配img标签和其src属性正则的写 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 百度UEditor编辑器关闭抓取远程图片功能(默认开启)
这个坑娘的功能,开始时居然不知道如何触发,以为有个按钮,点击一下触发,翻阅了文档,没有发现,然后再网络上看到原来是复制粘贴非白名单内的图片到编辑框时触发,坑娘啊............... 问题又来 ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- 抓取网页图片的脚本(javascript)
抓取网页图片的脚本(javascript) 本文地址: http://blog.csdn.net/caroline_wendy/article/details/24172223 脚本内容 (没有换行) ...
随机推荐
- Codeforces 1304F2 Animal Observation (hard version) 代码(dp滑动窗口线段树区间更新优化)
https://codeforces.com/contest/1304/problem/F2 #include<bits/stdc++.h> using namespace std; ; ...
- java学习笔记之集合—ArrayList源码解析
1.ArrayList简介 ArrayList是一个数组队列,与java中的数组的容量固定不同,它可以动态的实现容量的增涨.所以ArrayList也叫动态数组.当我们知道有多少个数据元素的时候,我们用 ...
- JavaSE学习笔记(1)---数据类型、运算符、控制结构
javaSE学习笔记(1) 数据类型和运算符 1.注释可以提高程序的可读性.可划分为 单行注释 // 多行注释 /.../ 文档注释 /**...*/ 2.标识符的命名规则: 标识符必须以字母.下划线 ...
- liunx 查找locate
使用 安装 yum install mlocate 更新数据库 updatedb 查找my.cnf文件 locate my.cnf
- python package install error and little code bugs
When you install packages using setup.py, the error: (py37) C:\Users\weda\Phd\python packages\visibi ...
- webpack 之搭建本地服务器
搭建本地服务器 webpack提供了一个可选的本地开发服务器,这个本地服务器基于node.js搭建,内部使用express框架,可以实现 我们想要的让浏览器自动刷新显示我们修改后的结果 不过它是一个单 ...
- 关于“教室派”APP的使用报告和相关建议
教室派APP能够很好的解决学生查询各教室占用情况这一问题,使用起来非常方便.用户可根据需要选取星期来查询不同教学楼教室使用情况. 编辑课表是其附带功能,但通过使用发现手动编辑课表效率太低,建议开发者加 ...
- 学习 Rust cookbook 之算法篇(algorithm)
原文作者:suhanyujie 永久链接:https://github.com/suhanyujie/rust-cookbook-note 博客链接:https://ishenghuo.cnblogs ...
- javascript脚本混淆
javascript脚本混淆 脚本病毒是一个一直以来就存在,且长期活跃着的一种与PE病毒完全不同的一类病毒类型,其制作的门槛低.混淆加密方式的千变万化,容易传播.容易躲避检测,不为广大网民熟知等诸多 ...
- webscarab
1.功能 WebScarab是一个用来分析使用HTTP和HTTPS协议的应用程序框架.其原理很简单,WebScarab可以记录它检测到的会话内容(请求和应答),并允许使用者可以通过多种形式来查看记录. ...