在C#中使用二叉树实时计算海量用户积分排名的实现
从何说起
前些天和朋友讨论一个问题,他们的应用有几十万会员然后对应有积分,现在想做积分排名的需求,问有没有什么好方案。这个问题也算常见,很多地方都能看到,常规做法一般是数据定时跑批把计算结果到中间表然后直接查表就行,或者只显示个TOP N的排行榜,名次高的计算真实名次,名次比较低的直接显示在xxx名开外这种。但是出于探索问题的角度,我还是想找一下有没有实时计算的办法,并且效率能够接受。
在博客园搜到一篇不错的文章,基本罗列了常用的方案,每种算法详细介绍了具体思路,其中基于二叉树的算法是个非常不错的方案,文章中只给了思路没有给出代码,于是我决定自己用C#实现出来。
这里只讨论具体算法实现,不考虑业务需求是否合理。
思路解析
关于算法核心思想前面的文章中写的很详细,我不再重复描述,这里只用一个具体示例演示这个过程。
假设积分范围是0-5,我们对它不断进行中位分区直到不能分为止,形成如下一棵二叉树:
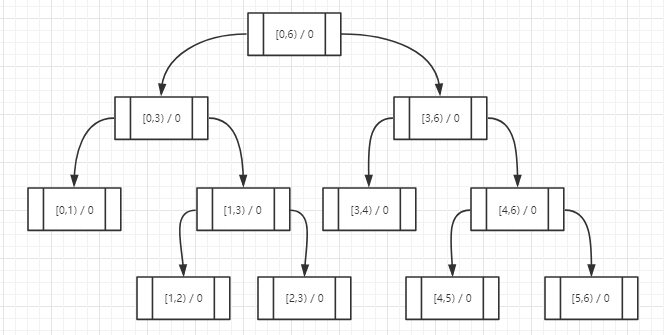
其中每个树节点包含2个信息:节点范围 range[min,max) 和命中数量计数器 count ,可以看到叶子节点的range一定是相邻的2个数。
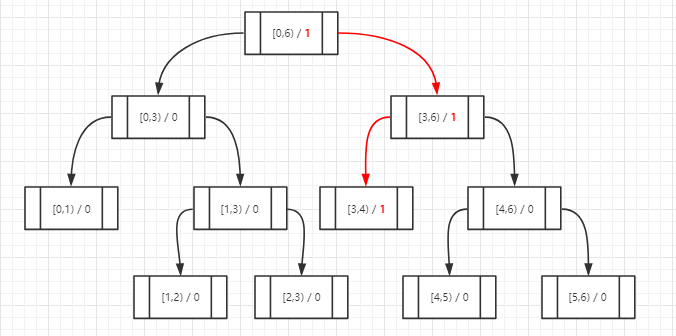
假如现在有一个积分3要插入到树中,该如何操作呢?当前节点从根节点开始,分别判断是否包含于左右子节点,如果包含的话当前节点改为这个子节点,同时计数器加1,然后再次进行相同判断,直到遍历到叶子节点为止,遍历顺序如下:
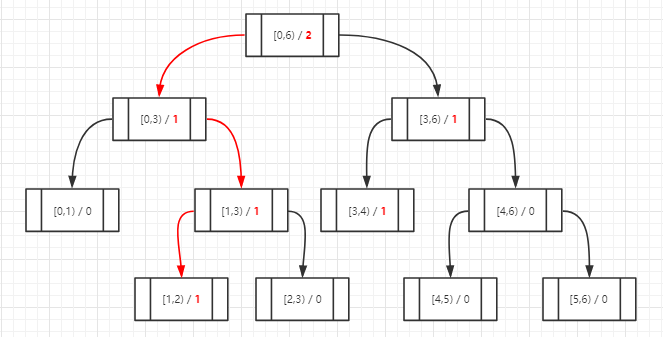
再依次插入1和4,二叉树的演变情况为:
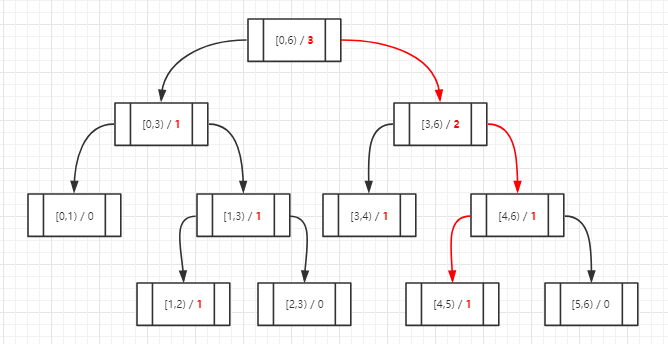
数据放进去后怎么判断它是排名多少呢?还是从根节点开始,判断它是否包含于左子节点,如果包含的话说明它比右子节点中count个数小(在count名之外),然后再往下一级做同样的判断;如果包含于右子节点那就继续往下判断,直到碰到叶子节点为止。依次累加count最后加上叶子节点占的一位就得到了它在这棵树里的排名,以1为例演示判断步骤(排名为2+1=3):
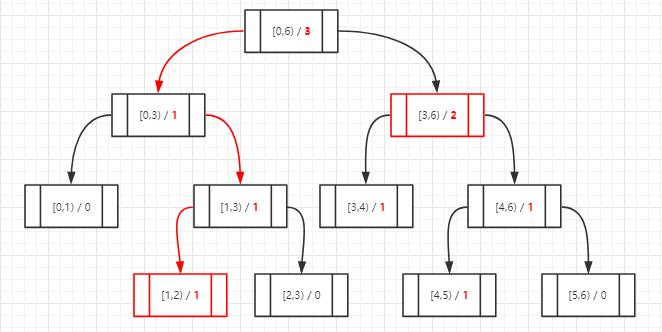
好了,一切就绪,只欠代码。
撸码实现
树结构由节点构成,那首先设计一个节点类:
/// <summary>
/// 树节点对象
/// </summary>
public class TreeNode
{
/// <summary>
/// 节点的最小值
/// </summary>
public int ValueFrom { get; set; }
/// <summary>
/// 节点的最大值
/// </summary>
public int ValueTo { get; set; }
/// <summary>
/// 在节点范围内的数量
/// </summary>
public int Count { get; set; }
/// <summary>
/// 节点高度(树的层级)
/// </summary>
public int Height { get; set; }
/// <summary>
/// 父节点
/// </summary>
public TreeNode Parent { get; set; }
/// <summary>
/// 左子节点
/// </summary>
public TreeNode LeftChildNode { get; set; }
/// <summary>
/// 右子节点
/// </summary>
public TreeNode RightChildNode { get; set; }
}
树节点的属性主要包含范围值ValueFrom、ValueTo、计数器Count、左子节点LeftChildNode和右子节点RightChildNode,由此组成一个有层次的树结构。
然后就是定义我们的树对象了,它的核心字段就是代表源头的根节点:
public class RankBinaryTree
{
/// <summary>
/// 根节点
/// </summary>
private TreeNode _root;
}
根据前面的算法思想,创建树的时候要用积分范围初始化所有节点,这里约定了最小积分为0,通过构造函数传入最大值并创建树结构:
/// <summary>
/// 构造函数初始化根节点
/// </summary>
/// <param name="max"></param>
public RankBinaryTree(int max)
{
_root = new TreeNode() { ValueFrom = 0, ValueTo = max+1, Height = 1 };
_root.LeftChildNode = CreateChildNode(_root, 0, max / 2);
_root.RightChildNode = CreateChildNode(_root, max / 2, max);
}
/// <summary>
/// 遍历创建子节点
/// </summary>
/// <param name="current"></param>
/// <param name="min"></param>
/// <param name="max"></param>
/// <returns></returns>
private TreeNode CreateChildNode(TreeNode current, int min, int max)
{
if (min == max) return null;
var node = new TreeNode() { ValueFrom = min, ValueTo = max, Height = current.Height + 1 };
node.Parent = current;
int center = (min + max) / 2;
if (min < max - 1)
{
node.LeftChildNode = CreateChildNode(node, min, center);
node.RightChildNode = CreateChildNode(node, center, max);
}
return node;
}
有了树以后下一步就是往里面插入数据,根据前面介绍的逻辑:
/// <summary>
/// 往树中插入一个值
/// </summary>
/// <param name="value"></param>
public void Insert(int value)
{
InnerInsert(_root, value);
_data.Add(value);
}
/// <summary>
/// 子节点判断范围遍历插入
/// </summary>
/// <param name="node"></param>
/// <param name="value"></param>
private void InnerInsert(TreeNode node, int value)
{
if (node == null) return;
//判断是否在这个节点范围内
if (value >= node.ValueFrom && value < node.ValueTo)
{
//更新节点总数信息
node.Count++;
//更新左子节点
InnerInsert(node.LeftChildNode, value);
//更新右子节点
InnerInsert(node.RightChildNode, value);
}
}
下一步提供方法获取指定值在树中的排名:
/// <summary>
/// 从树中获取总排名
/// </summary>
/// <param name="value"></param>
/// <returns></returns>
public int GetRank(int value)
{
if (value < 0) return 0;
return InnerGet(_root, value);
}
/// <summary>
/// 遍历子节点获取累计排名
/// </summary>
/// <param name="node"></param>
/// <param name="value"></param>
/// <returns></returns>
private int InnerGet(TreeNode node, int value)
{
if (node.LeftChildNode == null || node.RightChildNode == null) return 1;
if (value >= node.LeftChildNode.ValueFrom && value < node.LeftChildNode.ValueTo)
{
//当这个值存在于左子节点中时,要累加右子节点的总数(表示这个数在多少名之后)
return node.RightChildNode.Count + InnerGet(node.LeftChildNode, value);
}
else
{
//如果在右子节点中就继续遍历
return InnerGet(node.RightChildNode, value);
}
}
到这里,核心功能已经实现了。考虑到有积分更新的情况,我们可以加上节点更新和删除的方法。删除很容易,和插入逆向操作就行,更新就更容易了,把旧节点删除再计算出新值插入即可,完整代码已经上传到Github。
这棵树究竟效率如何,下面我们跑个分看看。
测试走起来
在测试程序中,我模拟了积分范围0-1000000的场景,这个范围几乎覆盖了真实业务中90%的积分值,100万积分以上的会员系统应该比较少见了。
而会员的积分值分布也是不均匀的,一般来说拥有小额积分的用户比例最大,积分值越高所占用户比例越小。
在程序中我假设有100万个会员,其中50W用户积分都在100以内,30W用户积分在100-10000,15W用户积分在10000-50000,5W用户积分在50000以上。
下面是各个操作的耗时时间:
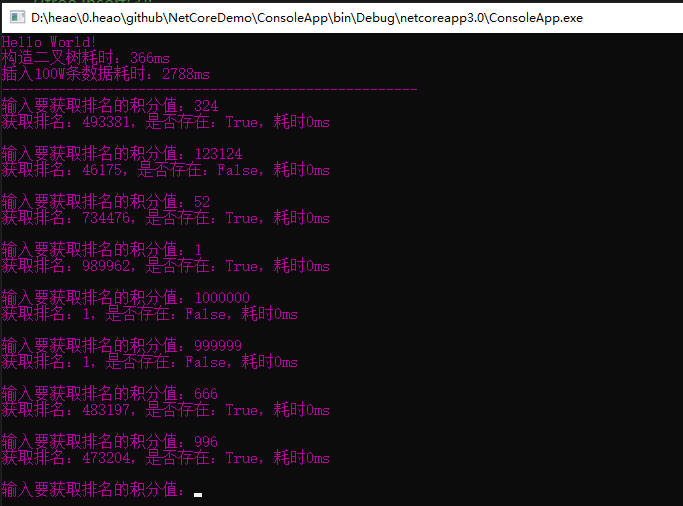
可以看到,这个效率不是一般的快啊,其中获取排名的查询时间几乎可以忽略不计。
这时候有人问了,这么多数据会不会非常吃内存,下面用任务管理器分别查看不使用树和使用树的内存情况:


运行环境是.NetCore3.0 Console,测试主机配置情况:
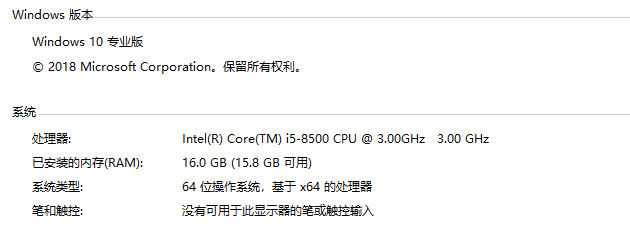
100万数据只有130M内存占用,对现代计算机来说简直是洒洒水~
业务环境中使用务必注意线程安全问题!!!
写在最后
以上的二叉树算法处理排名问题确实比较巧妙,实现起来也不算特别复杂,如果上述代码有缺陷或有其他更好的方案,欢迎探讨,也算抛砖引玉了~
完整代码及测试用例请戳这里https://github.com/hey-hoho/NetCoreDemo/tree/master/ConsoleApp/ScoreRank
在C#中使用二叉树实时计算海量用户积分排名的实现的更多相关文章
- storm中DAU实时计算方案
所就职的公司是一家互联网视频公司,存在大量的实时计算需求,计算uv,pv等一些经典的实时指标统计.由于要统计当天的实时 UV,当天的uv由于要存储当天的所有的key,面临本地内存不够用的问题,异常重启 ...
- Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV
Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV – lxw的大数据田地 http://lxw1234.com/archives/2015/09/516.htm Java使用极小 ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- Apache Flink 如何正确处理实时计算场景中的乱序数据
一.流式计算的未来 在谷歌发表了 GFS.BigTable.Google MapReduce 三篇论文后,大数据技术真正有了第一次飞跃,Hadoop 生态系统逐渐发展起来. Hadoop 在处理大批量 ...
- 《storm实战-构建大数据实时计算读书笔记》
自己的思考: 1.接收任务到任务的分发和协调 nimbus.supervisor.zookeeper 2.高容错性 各个组件都是无状态的,状态 ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- 克拉克拉(KilaKila):大规模实时计算平台架构实战
克拉克拉(KilaKila):大规模实时计算平台架构实战 一.产品背景:克拉克拉(KilaKila)是国内专注二次元.主打年轻用户的娱乐互动内容社区软件.KilaKila推出互动语音直播.短视频配音. ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- Storm大数据实时计算
大数据也是构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等 storm,在做热数据这块,如果要做复 ...
随机推荐
- 2018-8-10-添加右键使用-SublimeText-打开
title author date CreateTime categories 添加右键使用 SublimeText 打开 lindexi 2018-08-10 19:16:52 +0800 2018 ...
- TOP10!全球顶级云计算公司战斗力排行榜
TOP10!全球顶级云计算公司战斗力排行榜 1亚马逊\VMware.微软 [PConline 资讯]现如今,不谈“云”,似乎会与这个时代格格不入.无论是企业还是个人,都会与“云”扯上关系.可以说,云计 ...
- linux服务器时间更新
yum install ntpdate ntpdate ntp1.aliyun.com(阿里云服务器时间)
- js递归遍历树结构(tree)
如图: 代码: let datas = [] //是一个树结构的数据 setName(datas){ //遍历树 获取id数组 for(var i in datas){ this.expandedKe ...
- 【Pandas】Pandas求某列字符串的长度,总结经验教训
测试集大小: test.shape(898, 11) 对某列的字符串做统计长度1.for遍历法:start = time.time()for i in test.index.values: test. ...
- linux inode 结构
inode 结构由内核在内部用来表示文件. 因此, 它和代表打开文件描述符的文件结构是不 同的. 可能有代表单个文件的多个打开描述符的许多文件结构, 但是它们都指向一个单个 inode 结构. ino ...
- P1024 硬币问题
题目描述 假设现在有面值为1, 5, 10, 50, 100, 500的硬币各无限枚, 如果用这些硬币来支付A元, 最少需要多少枚硬币? 输入格式 一个整数A(0<=A<=1e9), 表示 ...
- H3C 无类域间路由斜线表示法
- 9月29更新美版T-mobile版本iPhone7代和7P有锁机卡贴解锁方法
T版是块难解的砖头,之前一直没有找到稳定解锁办法,经过多次不写努力和实验,终于解决 不管是用超雪卡贴还是GPP卡贴,第一次先用连接WIFI激活手机! 注意:一定不要用ICCID通用激活,或者是TM ...
- linux虚拟机设置固定IP并实现联网,主机与虚拟机实现互ping
ifconfig eth0 up 启用第一块网卡 onboot=yes 自动启动 service network restart 重启网络服务 使用虚拟机添加一块桥接网卡 cp eth0 eth1 复 ...