hbase2.1.9 centos7 完全分布式 搭建随记
hbase2.1.9 centos7 完全分布式 搭建随记
这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭配其他博客一同使用,并记得根据实际情况调整相关参数
1. 指定位置解压
2. vi /etc/profile
export HBASE_HOME=/opt/hbase/hbase-2.1.9
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH
source /etc/profile
3. vi /.../hbase-2.1.9/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HBASE_HOME=/opt/hbase/hbase-2.1.9
export HBASE_CLASSPATH=ls /opt/hadoop/hadoop-2.7.7/etc/hadoop/
export HBASE_PID_DIR=/opt/DonotDelete/hbasepid
export HBASE_MANAGES_ZK=false
###
export HBASE_CLASSPATH-->hadoop配置文件的位置
HBASE_MANAGES_ZK=false-->不启用HBase自带的Zookeeper集群
export HBASE_PID_DIR-->存储pid,防止pid在tmp文件夹中被删而造成无法通过命令关闭进程
详见:
https://blog.csdn.net/xiao_jun_0820/article/details/35222699
https://www.cnblogs.com/qindongliang/p/4894572.html
https://www.cnblogs.com/weiyiming007/p/12018288.html
同样的,为了hadoop的pid的安全
vi /opt/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
export HADOOP_PID_DIR=/opt/DonotDelete/hadooppid
同理vi ~/spark-env.sh
export SPARK_PID_DIR=/opt/DonotDelete/sparkpid
4. vi /.../hbase-2.1.9/conf/hbase-site.xml
注:如果要指定HDFS上的目录,端口号要与hdfs-site.xml中设为一致
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Gwj:8020/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Gwj,Ssj,Pyf</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase/temphbasedata</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>Gwj:60000</value>
</property>
</configuration>
5. vi /.../hbase-2.1.9/conf/regionservers
Ssj
Pyf
6. 启动 关闭 检查状态
/opt/hbase/hbase-2.1.9/bin/start-hbase.sh
stop-hbase.sh
status-hbase.sh
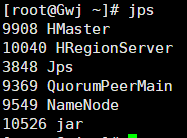
正常启动节点进程
HBase
Master---HMaster
Slave---HRegionServer
hbase2.1.9 centos7 完全分布式 搭建随记的更多相关文章
- zookeeper3.5.5 centos7 完全分布式 搭建随记
zookeeper3.5.5 centos7 完全分布式 搭建随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备 1,hadoop-2.7.3.tar.gz(包) 2,三台机器装有cetos7的机子 (二)安装步骤 1,给每台机子配相同的用户 进入root : su root ---------& ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
- Hadoop2.7.7 centos7 完全分布式 配置与问题随记
Hadoop2.7.7 centos7 完全分布式 配置与问题随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- 基于腾讯Centos7云服务器搭建SVN版本控制库
基于腾讯Centos7云服务器搭建SVN版本控制库 最近在和小伙伴组队参加一个关于人工智能的比赛,无奈不知道怎么处理好每个人的代码托管问题,于是找到了晚上免费svn托管服务器的服务,但是所给的免费空间 ...
- hadoop分布式搭建
1.新建三台机器,分别为: hadoop分布式搭建至少需要三台机器: master extension1 extension2 本文利用在VMware Workstation下安装Linux cent ...
- CentOS7.5 下搭建SFTP
CentOS7.5 下搭建SFTP Linux 创建用户组 groupadd sftp 创建用户test useradd -G sftp -s /sbin/nologin test -s 禁止用户ss ...
- [Jenkins]CentOS7下Jenkins搭建
最近在倒腾Kubernetes的一些东西,这次需要用到Jenkins来实现自动化构建.来讲一讲搭建的整个过程. Jenkins是什么 Jenkins提供了软件开发的持续集成服务.它运行在Servlet ...
随机推荐
- java实现第七届蓝桥杯平方圈怪
平方圈怪 题目描述 如果把一个正整数的每一位都平方后再求和,得到一个新的正整数. 对新产生的正整数再做同样的处理. 如此一来,你会发现,不管开始取的是什么数字, 最终如果不是落入1,就是落入同一个循环 ...
- python3 驱动自动安装脚本
from pywinauto.application import Applicationimport osimport timeos.system('start C:/Users/Administr ...
- ASP.NET Core通过Nacos SDK读取阿里云ACM
背景 前段时间,cranelee 在Github上给老黄提了个issues, 问到了如何用Nacos的SDK访问阿里云ACM. https://github.com/catcherwong/nacos ...
- 最新 iOS 框架整体梳理(二)
在前面一篇中整理出来了一些了,下面的内容是接着上面一篇的接着整理.上篇具体的内容可以点击这里查看: 最新 iOS 框架整体梳理(一) Part - 2 34.CoreTeleph ...
- ubuntu12.04 empathy添加qq登陆
1,
- 关于"touchstart与click同时触发"问题
点击事件可以分解成多个事件: 在移动端,手指点击一个元素,会经过:touchstart --> touchmove -> touchend --> click 由于移动设备能够同时 ...
- [apue] sysconf 的四种返回状态
众所周知,sysconf 用来返回某种常量的定义或者资源的上限,前者用于应用动态的判断系统是否支持某种标准或能力.后者用于决定资源分配的尺寸. 但是你可能不知道的是,sysconf 可以返回四种状态: ...
- dbca oracle 12 c 遇到ora27125
网上大部分方法是把dba组放在内核的,没有效果,可以尝试 google找到一位大神的方案,成功解决 https://oracle-admin.com/2014/01/22/ora-27125-unab ...
- @atcoder - ARC077F@ SS
目录 @description@ @solution@ @accepted code@ @details@ @description@ 规定一个字符串为 "偶串" 当且仅当它可以表 ...
- C# 9.0 新特性之模式匹配简化
阅读本文大概需要 2 分钟. 记得在 MS Build 2020 大会上,C# 语言开发项目经理 Mads Torgersen 宣称 C# 9.0 将会随着 .NET 5 在今年 11 月份正式发布. ...